User Browsing Model简介
搜索引擎的点击日志提供了很多有价值的query-doc相关性信息,但是这些信息是有偏的,因为对于用户没有点击过的doc,我们无法确定其是否真实地被用户浏览过。即日志中记录的展现信息与实际的展现信息之间是存在一定的差距的,日志中记录的展现doc在实际上用户并不一定真的看到,排序的位置对用户是否看到 & 点击也存在一定的影响。User Browsing Model(UBM) 即是在消除这些因素对CTR的影响,使得根据历史信息得到的CTR能更好的拟合doc原始的CTR。
User Browsing Model(UBM) 通过对用户在搜索结果页上的浏览行为和点击行为作出一定的假设,来预估每个doc被用户浏览过的概率。具体的方法是,构建出(query-doc的展现CTR:Display CTR)与(query-doc的展现概率:Examination和 query-doc的真实CTR:Attractiveness)这二者之间的关系,即Display CTR = Examination * Attractiveness。
在实际的使用中,User Browsing Model得到的模型的参数,可以有两种使用方向:
1)doc的展现概率:Examination,可以用于修正相应的doc的展现次数,进一步可以修正统计CTR,以及修正CTR预估模型的目标。
2)doc的真实CTR:Attractiveness,可以用于修正相应的doc的CTR数值,可以作为统计CTR来看待,也可以作为CTR预估模型的目标。
考虑这样的场景:当一个用户输入一个query后,搜索引擎返回给他一个搜索结果列表,用户从第一个结果开始按照排序结果的顺序进行浏览,对于每一个位置的结果,用户需要决定是否浏览这个结果,如果进行浏览行为了之后,再根据这个结果是否相关(或者说对于用户有吸引力)来决定是否进行点击。所以,如果最后用户对某个结果进行点击了,说明:
1)用户对该doc进行了“浏览”(Examination=1)
2)该doc与query“相关”(Attractiveness=1)

User Browsing Model中假设:
1)是否相关的概率则是由query(q)与doc(u)决定。
2)用户是否浏览某个doc的概率与该doc的的位置r,以及距离上一次点击的距离d有关(如果之前没有过点击行为,则认为是上一次点击的位置为0)。之所以考虑距离上一次点击的距离,是基于这样的假设:当用户看到一大段不相关的结果列表时,更倾向于放弃这次搜索行为。
因此,Attractiveness和Examination可以定义如下: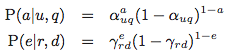
那么,一次点击行为序列则可以使用联合概率P(c,a,e|u,q,d,r)来表示: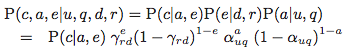
为了计算一个观测组(c,u,q,d,r),则需要分别考虑点击与否的情况。
当c=1时,即当前发生一次点击,我们可以以此推断用户对该doc进行了“浏览”(Examination=1),同时该doc与query“相关”(Attractiveness=1)。与此相反,若当前没有发生点击,则说明用户对该doc没有进行“浏览”(Examination=0),或者该doc与query“不相关”(Attractiveness=0),综合来看,可以表述为: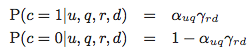
为了求得参数α和γ的值,可以使用最大似然估计的方法,将观测结果分为两个集合,分别为点击集合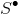 和未点击集合
和未点击集合 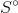 ,可以得到如下的似然函数:
,可以得到如下的似然函数:
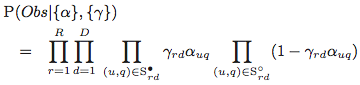
其中,q代表query,u代表一个样本id,r代表样本排序的位置, 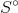 代表未点击样本的集合,d代表样本排序与上一次点击的距离,γ代表在位置r,距离d时被用户看到的概率,α表示样本被点击的实际概率。
代表未点击样本的集合,d代表样本排序与上一次点击的距离,γ代表在位置r,距离d时被用户看到的概率,α表示样本被点击的实际概率。
由于得到的似然函数是凸函数,因此可以使用梯度下降的方式来进行求解,分别对两个参数计算梯度:
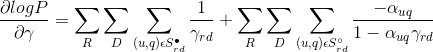
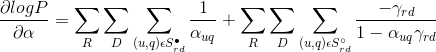
使用随机梯度下降的方法求解参数α和γ使得似然函数取得最大值: