
cs231n --- 3 : Convolutional Neural Networks (CNNs / ConvNets)
CNN介绍
与之前的神经网络不同之处在于,CNN明确指定了输入就是图像,这允许我们将某些特征编码到CNN的结构中去,不仅易于实现,还能极大减少网络的参数。
一. 结构概述
与一般的神经网络不同,卷积神经网络尤其特殊之处。一般的神经网络每一层与前一层之间采用全连接;一层中的神经元之间也是互相独立的,并不共享权值;最后一层全连接层陈伟输出层,在分类任务中出表示类别得分。CIFAR-10中图像是32*32*3=3072,所以,与输入相连的第一个隐层的每个神经元的参数都有3072个,如果图像尺寸更大,那么每个神经元的参数更多,这将造成巨大的参数冗余,训练中也会很快导致过拟合问题。如下图左所示。
|
神经网络 |

卷积神经网络 |

卷积神经网络限定了输入的是图像,它可以采用更合理的方式安排神经元。CNN不将图像调整为向量之后再输入,而是直接以原始的3D矩阵形式(高x宽x通道数)给输入层,然后输出3D数据矩阵,并依次进行学习、表示。
二. 卷积神经网络的层 Layers
卷积神经网络是由一系列的层Layer组成的,下面介绍主要的层(包括卷积层 Convolutional layer,池化层 Pooling layer,全连接层 Fully-connected layer)。
以应用于CIFAR-10数据集的卷积神经网络为基础,介绍如下结构的卷积神经网络,
[ INPUT - CONV - RELU - POOL - FC ]
- Input:[32x32x3],保存原始图像的像素值
- CONV layer:计算与输入input 局部区域相连的神经元的输出,每个输出都是 局部输入与这些神经元的权重的点积(.*),如果有12个滤波器(卷积核),则输出为 [32x32x12]
- ReLU:非线性操作max(0,x),不改变输入尺寸,[32x32x12]
- Pool:池化,对输入的 [长x宽] 方向上进行下采样,改变输入尺寸,如可以得到这样的结果 [16x16x12]
- FC:计算类别得分,得到结果 1x1x10(CIFAR-10 有10类)
ReLU与Pool都是固定的函数,训练时 只对 CONV layer与FC进行权重更新
1. 卷积层 convolutional layer
卷积层是卷积神经网络的核心模块,它承担了主要的计算工作
卷积层的参数是一系列可以学习的滤波器。每个滤波器都是[ filter_宽xfilter_高x通道数 ],第一个卷积层的典型滤波器尺寸是 5x5xx3。前向传播时,我们把每个滤波器沿着输入数据的高度与宽度滑动(卷积),计算滤波器系数与滤波器窗口所覆盖的输入区域 之间的点积,随着滤波器沿着输入数据的高度x宽度全部滑动一遍,就会得到二维的输出映射(activation map),activation map 保存的是滤波器在输入上滑动时,在空间每一个点的响应(点积 .*)。这样一个滤波器就得到一个 activation map,12个滤波器就会得到12个activation map,然后沿着深度的方向将这12个二维的 activation map(输出映射)组合成输出,作为下一层的输入。
 一个滤波器对图像卷积,convolved feature即为滤波器的 activation map,即从图像学到的特征 |
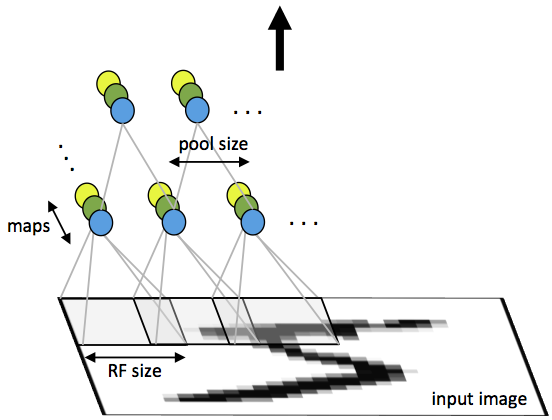
第一层对原始图像卷积后,学到多个二维 activation maps,然后按照Z轴(深度)组合起来,传递给后面的 pooling layer 进行下采样 |
直觉上卷积神经网络学习到的滤波器应该是这样的,它们在遇到特定的结构时会激活,比如有的滤波器在遇到边缘时会激活,有的在遇到某个直角会激活,...; 而且不同的层的滤波器检测的形状也不一样,前面的层,它们的滤波器检测基本的形状,越靠后面的层,这些基本特征组合成复杂形状,后面层的滤波器检测复杂形状,最后网络就能检测出车轮,或者花朵之类的物体。
1.1 局部连接
局部连接就是指小尺寸的滤波器,与高维的输入之间的连接。以卷积神经网络第一层为例,采取输入是原始图像,由于不可能像一般的神经网络那样实行全连接(参数太多!),所以定义小尺寸的滤波器 [filer_宽,filter_高,图像通道数],必须保证滤波器深度与图像的深度是一致的,这样滤波器在图像上面滑动(卷积)时,只考虑在图像 宽x高 的空间面上滑动,所以产生的是二维的输出。滤波器在图像上滑动时,它所能够覆盖的输入图像的区域,就是局部的小区域(大小是 filter_宽 x filter_高),卷积运算也就是在滤波器与小区域之间进行,得到一个卷积结果数值,随后再滑动一定的步长,再次进行卷积。局部连接就是每次卷积时,神经元只与覆盖的小区域连接。
输出的大小
卷积层对输入进行卷积后,得到activation maps,然后再以某种形式安排这些数据,形成输出,主要的参数有深度,步长,零填充。
- 深度是指输出的深度,即输出是 宽度 x 高度 x 深度。深度是由滤波器(卷积核)的数量控制的,有多少个滤波器,就有多少个 activation maps,输出就是将这些 activation maps组合起来,输出的深度就等于滤波器数量。
- 步长是指卷积时每次滤波器跳过的像素数,步长=1,则滤波器每次移动一个像素;步长=2,则滤波器每次移动2个像素执行卷积。注意,步长必须能整除 N+2P-m,见下面的例子。
- 零填充是为了使滤波器的 activation maps 与输入有相同的 宽度x高度
一个例子,输入是 NxNx3;滤波器是 mxmx3,共有K个;步长是 S;零填充是使用P个0在边界填充,则输出activation maps的 高度(=宽度)应该是 (N+2P-m)/ S + 1。
CIFAR-10 的图像是 32x32x3, 选择 滤波器尺寸 5x5x3,步长 S=1,填充 P= 0,则输出是 28x28;如果步长S=3,则输出是 10x10。
1.2 权值共享(参数共享)
一个例子是ImageNet 2012,图像是 227x227x3,m = 11,S=4,P=3,K=96,则第一层卷积的输出是 55x55x96。如果按照一般神经网络的设置,55x55x96的输出需要 55*55*96 =290400 个神经元,每个神经元需要的参数是 11*11*3 + 1 =364,因此在第一层就有 290400*364 =105,705,600个参数,这是非常多的。
卷积神经网络采用了权值共享的思路,对于一个滤波器来说,它的任务是检测某个特征,比如说检测水平线,那么它检测到了(x1,y1)位置处的水平线,那么如果在(x1,y2)位置处有水平线,它应该也能检测出来。因此,它应该使用相同的参数来检测不同位置处的水平线,所以,就设计一个滤波器在输入的所有位置(x,y)上滑动时,它的参数都是相同的,也就是说,滤波器在输入的所有位置上,都是用相同的参数来检查某一特征(体现为卷积操作),然后将卷积的结果就是它的activation map。这样就使得网络的参数大大减少,卷积神经网络第一层的参数就变为 96*11*11*3 + 96 = 34944。
注意:有的地方不需要权值共享,有时输入图像具有特定的中心结构,我们还希望学到这种结构。那就不需要权值共享了。比如,面部出现在图像中心,我们期望学到不同的位置的眼睛或者头发特征,那就不需要权值共享,而只需要局部连接就行了。
卷积的实现(Python):通过 im2col 的方法来实现,用矩阵相乘完成卷积操作
假设输入X [227x227x3],96个滤波器 [ 11x11x3 ],步长S=4,那么一个滤波器卷积的输出维度应该是 (227-11)/ 4 = 55,卷积层的输出应该是 55x55x96。
- 滤波器覆盖是区域是 11x11x3 =363,一个滤波器将对输入X执行卷积操作 55x55 =3025 次,所以根据X,可以得到 X_col [ 363x3025 ],每一列代表 滤波器在X上覆盖的区域的展开
- 根据96个 [11x11x3] 滤波器,得到 filter_col [ 96x363 ],每一行都是一个滤波器参数的展开
- 矩阵相乘 np.dot(filter_col, X_col) 得到 [96x3025],最后 np.reshape 即可得到55x55x96的卷积结果
2. 池化层 pooling layer
在连续的卷积层之间加入池化层很常见,pooling layer 的作用是逐步的减小从图像中提取的表达representation的尺寸,进而减少网络的参数与计算量,同时还能控制过拟合。最常见的pooling layer的下采样尺寸 2x2,步长s=2,它沿着 activation maps的 宽度x高度面下采样,并不影响深度。
主要有两种pooling方法,max pooling与mean pooling,主要有 尺寸 2x2,与步长S两个采样参数。但并不更新,是固定的,pooling layer只执行固定的下采样作用。下图示意图。
|
pooling |
max pooling |
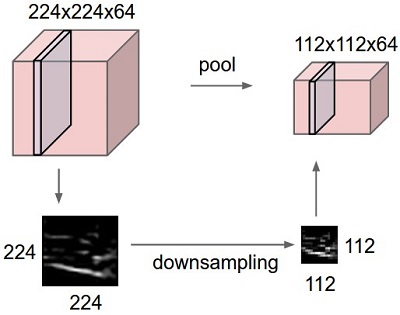
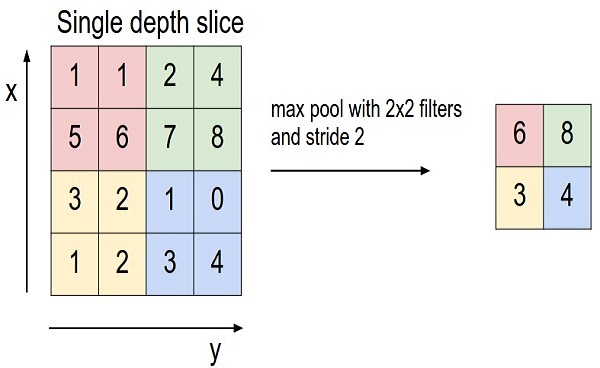
max pooling ,采样尺寸 2x2, 步长s=1,在2x2采样窗口所覆盖的输入区域内,取输入区域最大值max(...),作为对应的输出数据点(也就是输入的2x2数据产生一个输出数据);然后采样窗口根据步长规定移动,再对下一个窗口覆盖的输入数据采样,作为输出数据值,...,直至采样完成。max pooling的常见尺寸是 3x3, 步长S=2(重叠采样),或者 2x2,步长=2
mean pooling:与max pooling类似,只是取输入的均值作为输出值。现在更常用 max pooling,实际效果比 mean pooling 好。
注意:下采样时一般不用零填充
3. FC layers to CONV layers
实际中将全连接层转换成具有相同效果的卷积层,加快速度,提升效率。
三. 卷积神经网络的结构
卷积神经网络主要有: CONV, POOL(max), ReLU, FC 组成。
最常见的卷积网络结构是: [ 一些 CONV - ReLU 层,接着是一些 POOL 层 ],重复以上结构,直到图像合并成比较小的图,然后是 一些FC 层,最后一层 FC 层保存类别得分之类的输出,
如下所示:
INPUT -> [ [CONV -> RELU] *N -> POOL? ]*M -> [FC -> RELU]*K -> FC
* 表示重复,POOL? 表示可选的 pooling层, 通常 0 <= N <= 3,M >= 0,0 <= K < 3。
3.1 如下是常见的一些 卷积网络结构:
- INPUT -> FC,实现线性分类器功能,N = M = K = 0
- INPUT -> CONV -> ReLU -> FC
- INPUT -> [ CONV -> ReLU -> POOL ]*2 -> FC -> ReLU -> FC
- INPUT -> [ CONV -> ReLU -> CONV -> ReLU -> POOL ]*3 -> [ FC -> ReLU ]*2 -> FC, 大型的深度网络适用,在 pooling 层之前多个 conv 层可以提取输入的更复杂的特征
3个 3x3 CONV 效果 等同于 1个 7x7 CONV,但是更倾向于 多个小尺寸 CONV ,因为多个小尺寸 CONV层 可以 1. 更有效的表达特征,2. 减少参数。
3.2 各个层的尺寸问题
1. 输入层(INPUT)应该能够被 2 整除很多次,通常有 32(CIFAR-10),64,96(STL-10),224,384,512
2. CONV layer使用小的 filter(3x3,最多是 5x5),步长S=1,需要对输入进行零填充以保持输入的大小 ( 宽度x高度 ). 如果非要使用 大的filter(比如7x7),只有在跟输入的图像相邻的第一个卷积层上使用。
3. POOL layer 控制对输入的下采样,一般是Max pooling,最常用的是 2x2 ,步长S=2,这个设置就舍弃了 75%的下采样层的输入(即上一层的activation map);另外一个不经常用到的设置是 3x3,步长 S=2。对于 max pooling,采样窗口大于 3x3 会导致损失太大,性能不佳,很少用。
四. 卷积网络的几个例子
- LeNet:第一个成功应用的卷积神经网络,用于读取 zip编码,识别手写数字等。
- AlexNet: 由Alex Krizhevsky, Ilya Sutskever 和 Geoff Hinton提出,2012年的ImageNet ILSVRC challenge冠军,网络与LeNet很相似,但是更深更大,而且有CONV层叠加起来,之前都是一个CONV层后面就立即跟一个POOL层。
- ZF Net:ILSVRC 2013的冠军,由Matthew Zeiler 和 Rob Fergus 提出,ZF Net是对AlexNet的改进,扩展了中间的卷积层CONV layer,而且使第一层的步长S与滤波器filter的尺寸都更小。
- GoogleNet:Google的Szegedy et al.提出的,ILSVRC 2014冠军,主要贡献是开发的初始模块极大减少了网络的参数(GoogleNet的参数4M,AlexNet有60M),文章在网络的顶部使用平均池化Average pooling 而不是全连接层,消除了大量的无关紧要的参数。
- VGGNet:ILSVRC 2014的亚军,由Karen Simonyan 和 Andrew Zisserman提出,主要贡献是展示了网络的深度对于性能的提升非常重要。网络包含 16个 CONV / FC 层,从头到尾都是 3x3的CONVOLUTION,2x2的Pooling。参数有 140M。
- ResNet:残差网络是 ILSVRC 2015的冠军,由 Kaiming He et al. 提出,网络的特点是 skip connections 和 a heavy use of batch normalization,在网络的最后也没有FC层。截至2016.5月此网络是最好的卷积神经网络模型,实际中默认选择的卷积网络。
VGGNet 分析:
CONV layers执行3x3卷积,步长S=1,零填充P=1; POOL layers执行2x2 max pooling,步长S=2,不进行零填充P=0。
追踪每一步的 表达size 与 参数size:
INPUT: [224x224x3] memory: 224*224*3=150K weights: 0
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*3)*64 = 1,728
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*64)*64 = 36,864
POOL2: [112x112x64] memory: 112*112*64=800K weights: 0
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*64)*128 = 73,728
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*128)*128 = 147,456
POOL2: [56x56x128] memory: 56*56*128=400K weights: 0
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*128)*256 = 294,912
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
POOL2: [28x28x256] memory: 28*28*256=200K weights: 0
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*256)*512 = 1,179,648
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
POOL2: [14x14x512] memory: 14*14*512=100K weights: 0
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
POOL2: [7x7x512] memory: 7*7*512=25K weights: 0
FC: [1x1x4096] memory: 4096 weights: 7*7*512*4096 = 102,760,448
FC: [1x1x4096] memory: 4096 weights: 4096*4096 = 16,777,216
FC: [1x1x1000] memory: 1000 weights: 4096*1000 = 4,096,000
TOTAL memory: 24M * 4 bytes ~= 93MB / image (only forward! ~*2 for bwd)
TOTAL params: 138M parameters
计算上的考虑
现在构建卷积神经网络最大的瓶颈就是内存瓶颈,进行网络构建时提前计算所需内存大小:
1. 每层的activation maps,梯度。
2. 参数数量
3. 其余所需数据,比如 image data等。
理解CNN,可视化
总结一些理解与观察CNN的方法
1. 可视化层的activation
最直白的可视化就是在CNN计算前向传播时,可视化神经网络的输出映射activation maps。如果存在某些 activation maps,对于许多不同的输入这些activation maps的值都是0,那么就暗示这些滤波器 filters是“死”的滤波器,可能是学习率过大的标志。
2. CONV / FC Fliters
第二个常用方法是可视化权重,一般第一个卷积层的权重可视化后最易于解释,因为它连接的原始图像,后续的也应该可以可视化。权重可视化的用途在于,对于训练很好的网络,它的滤波器权重可视化后一般都是平滑流畅的无噪声图像。有噪声的可视化图像暗示着网络训练的时间不够长,或者是正则化强度太低导致了过拟合。

左侧是训练好的AlexNet的第一个卷积层的滤波器可视化,图中彩色/灰度在一起是 因为AlexNet网络有两个独立的处理流,结果就是一个开发高频灰度图像,另一个开发低频彩色图像 |

右侧是训练好的AlexNet第二个卷积层的滤波器可视化,可视化图像无法明确的解释,但是这些图像都是光滑的、无噪声图像 |
3.检索出能够使神经元有最大激活的图像
另一个可视化方法就是将一个大的图像集输入给网络,追踪可以最大激活某些神经元的图像,然后将图像显示出来。以此来观察这些神经元在它的感受野之内,它寻找的是什么样的图像。一个这样的可视化方法就是 Rich feature hierarchies for accurate object detection and semantic segmentation by Ross Girshick et al.:

AlexNet的第5个POOL 的某些神经元的 最大激活图像,激活值和感受野以白色显示 |
ReLU的神经元本身没有什么语义含义, http://cs231n.github.io/understanding-cnn/
4. 根据 t-SNE嵌入图像
t-SNE(t-distributed stochastic neighbor embedding):t-分布随机领域嵌入,是用于降维的一种机器学习算法,是由 Laurens van der Maaten 和 Geoffrey Hinton在08年提出来。此外,t-SNE 是一种非线性降维算法,非常适用于高维数据降维到2维或者3维,进行可视化。
思路就是将数据从高维降维到地位,然后将低维上距离相近的图像靠近,完成可视化。为了嵌入,我们可以将图像集合输入卷机网络,提取他们的CNN码,CNN码可以是AlexNet中分类器之前的 4096-维矢量,然后将CNN码插入t-SNE然后得到图像的2-维矢量,如下:

根据CNN码将图像进行t-SNE嵌入。CNN“认为”靠的近的图像更相似,这种相似性是语义与类别上相似性,而不是颜色或者像素值的相似性。 more related visualizations at different scales refer to t-SNE visualization of CNN codes. |
5. 遮挡图像的一部分
如果CNN网络将一幅图像判定为“dog”,那么如何确定CNN网络实际判定的依据呢?它是依据图中的dog来判定的?还是依据图像上下文或者其他物体来判定的呢?为了明确这一点,可以通过遮挡图像之后,画出CNN网络的预测类别来观察。具体的就是,逐块的遮挡图像中的区域,使要遮挡的区域设置为0,然后观察CNN判断类别为 dog 的概率。还可以将概率画作2-位热力图,Matthew Zeiler 已经使用此方法 Visualizing and Understanding Convolutional Networks:

三幅图像,遮挡都是以灰色区块表示。最左侧的 Dog 图像,Dog图像下方是 CNN判定次图像类别是 Dog 的概率,可以看出当遮挡了上面图像中Dog的脸部区域后,CNN判定Dog类别的概率就大幅下降(表现为蓝色),这说明,Dog的脸部是判定的主要依据。而那些遮挡后 类别概率不变的部位,对于类别判定的影响可以忽略。 |
Visualizing the data gradient and friends
Data Gradient.
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
DeconvNet.
Visualizing and Understanding Convolutional Networks
Guided Backpropagation.
Striving for Simplicity: The All Convolutional Net
Reconstructing original images based on CNN Codes
Understanding Deep Image Representations by Inverting Them
How much spatial information is preserved?
Do ConvNets Learn Correspondence? (tldr: yes)
Plotting performance as a function of image attributes
ImageNet Large Scale Visual Recognition Challenge
Fooling ConvNets
Explaining and Harnessing Adversarial Examples
Comparing ConvNets to Human labelers
What I learned from competing against a ConvNet on ImageNet
迁移学习(Transfer Learning)
实际上,很少有人从零训练整个卷积网络,因为很少有足够数目的数据供其训练使用。一般都是使用一个大数据集(如ImageNet)来预训练一个卷积模型,然后对于目标任务,使用这个模型作为初始模型或者作为固定特征抽取器。三个主要的迁移学习场景如下,
- 卷积网络作为固定特征抽取器。在ImageNet上预训练一个卷积模型,然后去掉最后的全连接层,将剩余的模型作为新数据集合的固定特抽取器来抽取特征。AlexNet中,在分类器之前的那一层输出,每个图像都将计算得到长为4096的特征矢量,称之为CNN码。 一般需要对CNN码进行ReLU操作,这样可以提高分类与预测性能。所有图像的CNN码提取完成之后,这些CNN码构成了新的数据集合,可以用线性分类器(linearSVM或softmax)分类。
- 对卷积网络参数调优。这个策略不仅仅替换掉卷积网络模型最后一层的分类器,而且还要继续对这个模型的参数调优。继续进行BP迭代即可,既可以对整个网络调优,也可以只固定前面的低层,仅仅对后面的的高层调优。这样做的原因在于,通过观察可以发现,卷积网络前面的低层学习的一般是对许多任务都通用的特征(如边,线,点等低级特征),而后面高层网络学习到的是对原始数据集分类任务所需要的更具体的特征(因此对不同的新数据集就不是最优的)。比如,ImageNet有许多种类的狗,模型的高层学习的更多是如何区分不同品种的狗,低层学习的可以是基本的线条形状等更通用的。
- 预训练模型。现在的模型在ImageNet上需要用2-3周的时间在多GPU上训练,有人就会放出他们在保存点保存的模型,以供别人调优,减少时间。
怎样调优?何时调优? 两个重要的因素是新数据的大小、新数据集与原数据集的相似程度。
- 新数据集小而且与原数据集相似。 新数据集小,不必对模型参数调优,防止可能的过拟合。二者相似,模型的高层特征与新数据集也会相关。因此最好是训练线性分类器对CNN码分类。
- 新数据集很大,且与原数据集相似。可以进行参数调优,而不必担心过拟合问题。
- 新数据集小,但是与原数据集差别很大。新数据集小,最好的直接训练线性分类器就好。然而新、旧数据集差别很大,因此模型的高层特征相关性比较小,不宜直接使用高层CNN码进行线性分类,最好是使用低层的CNN码。
- 新数据集大,而且于原数据集差别大。可以直接对原模型调优,不必担心过拟合。

