

------人工智能飞速发展的势头已经不可小视,目前它的神秘仍然像一个black box,然而我们不妨大胆的预测,随着feature visualizing技术和方法的前进,真相大白的一天终会到来,本篇就是一个mark stone of the Amazing future of AI! -------
近些年大规模的卷积神经网络模型在图片分类上取得了显著成果,然而对为什么会习得如此好的分类性能,学术界仍没有给出清晰的解释。本文将介绍一种新颖的可视化技术,利用反卷积网络辅助理解卷积神经网络中间特征层的作用。此外,通过敏感性遮挡实验验证了神经网络在分类图片时,主要取决于图片中人物而不是不相关的背景信息。通过充分理解神经网络的特征信息,我们才可更好的改进现有模型。
关键词:卷积神经网络,特征可视化,反卷积。
1.前言
从1990年初,卷积神经网络模型由LeCun等人[1]介绍后,便逐渐在诸多领域表现出很好的性能,如手写字母识别和人脸检测领域。在最近的十八个月内,卷积神经网络得到迅速发展,在ImageNet 数据库和CIFAR-10数据库均表现出卓越的分类识别性能。之所以有这么好的表现,我们可归纳为以下几个原因:
1.训练数据集规模大,可达百万级别。
2.GPU的应用,使得训练大规模数据可行化。
3.更好的泛化策略,如dropout策略[2]。
除了上述这些易于理解的解释,目前缺少的是对卷积神经网络模型到底是如何作用的阐述。 从科研的立场来看这个问题,目前的对卷积神经网络的理解是令人不满意的,没有本质上清楚的解释卷积神经网络模型是怎么工作的以及为什么这么工作,那么未来的发展就只能基于过往的经验,这对卷积神经网络的发展来说是个不利因素。本文提出一种可视化技术用于揭示输入是怎么激励模型各个中间特征层输出的,同时我们可以借此观察到训练过程中特征层的卷积结果来诊断模型中潜在的问题。该可视化技术主要应用多层反卷积网络,它是由ZeiLer等人[3]提出。
本文所用的模型是标准的全监督卷积神经网络模型如图1所示。它将一个2D的输入图像xi,经由一系列隐藏层的训练,输出一个为概率向量yi(总共有C个不同的类别),故该卷积神经网络的模型的每一层包括:
1.卷积核(Learned Filters or Kernels)及其与上一层输出的卷积响应(Activation map or feature map)。
2.将卷积响应传给一个校正线性函数(Relu(x)=max(x,0))。
3.选择性的执行max pooling。
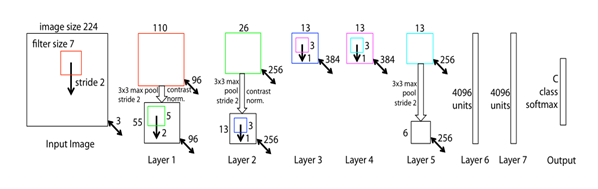
图 1. 本文应用模型是一个8层的卷积神经网络,输入是224×224的三通道图像(so,the volume is 224×224×3),第一层有96个7×7的kernel,在x和y方向的步长均为2,对feature maps 的操作依次有:(1)逐元素的线性函数矫正如relu;(2)用3×3的邻域,步长为2进行池化;(3)对比度归一化操作后可得到volume=55×55×96;相同的操作应用到2、3、4、5层,紧接着是两层全连接层,最后一层softmax层,共有c个类别。
2. 反卷积网络的设计
理解卷积神经网络的突破点在于理解中间特征层含义,本文提出一种新颖的方法可将中间特征层的输出映射到原始输入的空间上,这种映射是通过反卷积网络来实现的,一个反卷积网络可以看做是利用相同元素(kernels, pooling )的卷积网络,只是这些元素的顺序要依次对调过来。卷积神经网络是把像素映射成特征,那么反卷积网络就是把特征映射为输入空间上的像素。
应用反卷积网络辅助理解一个卷积神经网络,需要在该网络模型的每一层附带一个反卷积层,在检测理解某一层的某一个activation map时,我们需要先将该层的其他activation map 的值置为0,然后将该层的feature maps 作为输入传递给该层附带的反卷积层,依次执行unpooling, rectification, filtering 来重构响应的输入像素特征。
Unpooling: 在卷积网络中,max pooling 操作是不可逆的,然而我们可以通过记录最大值的位置(switch variables)来近似执行它的反操作。
Rectification: 在卷积层中,利用relu这一非线性函数来校正feature maps,使得特征值均为正值,因而在反卷积中来实现特征重构时,也需要将值传递给一个relu的非线性函数。
Filtering: 在卷积网络中,利用可学习的filters 来跟上一层的feature maps进行卷积,为了近似的反转这个过程,反卷积层利用同一filter的转置矩阵(FT)作为卷积核。
如图2所示,图上半部分是反卷积操作的步骤图,依次经过Max Unpoooling,Rectified Linear Function和Convolutional Filtering操作;下半部分是图形化的展示。图右侧是一个卷积层,左侧是附带其上的反卷积层。从图中可看出"reconstruction"是"layer below pooled map"的一个重构近似结果。
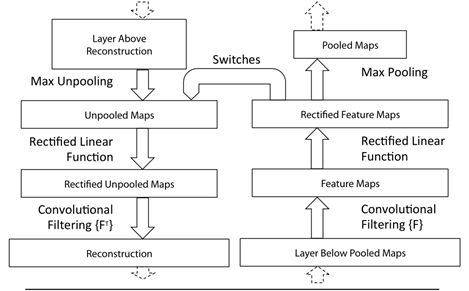
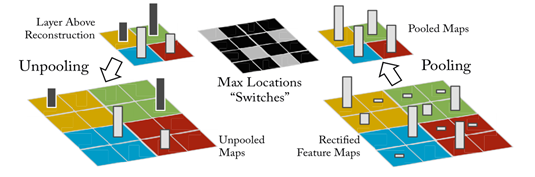
图 2. 利用反卷积网络可视化模型流程图。
3. 网络特征可视化
本文所训练的模型如图1所示,训练的数据集是ImageNet 2012 traning set,其中包含1.3×10^6个图片,隶属于1000个类别[4]。将训练好的神经网络模型应用反卷积网络的方法可视化模型中的feature activations。
如图 3.1所示是将模型进行特征可视化的结果示意图。对于一个给定的feature map,我们选取前九个activations,每一个都单独反卷积过去投射到像素空间(投射的结果称为projections),从而揭示了与之对应的filter所敏感的像素特征。旁边是与之对应的图像块。对比可发现,这与我们视觉的观察结果有很大不同。例如,在5层中,第一列的第二个中,图像块彼此并没有什么相同点,但相应的filter却发现了它们有相同的背景,并不是背景前面的物体。
此外,每一层的projections显示的信息均具有层次感,也体现了神经网络观察分辨图片的层次能力。如第二层网络对应的是边界、轮廓和色块信息;第三层捕捉的是纹理信息;第四层展现了较大的差异主要是一些类别上部分的信息,狗的脸,鸟的腿等;第五层展示的是不同姿势的整个物体的视图。

图 3.1 在训练好了的模型中进行特征可视化。2-5层是利用反卷积网络的方法分别展示了在验证集合上的前九个激活特征视图(activations map)。
图3.2 展示的是训练过程中特征的演变,从图中可看出,在训练过程中,底层的特征很快便可以收敛,然而高层的特征要经过相当多次迭代才可以收敛。所以要想使得神经网络模型有好的性能,就要多次迭代使得它达到全网络层收敛。
图 3.2 训练过程中特征的演变。每一层的特征都由一个块表示,每一块中,每一行对应的随机挑选的filter在迭代[1,2,5,10,20,30,40,64]次习得特征(可视化这些特征采用的方法是是反卷积网络)
4. 敏感性遮挡验证
对于图片分类算法来说,一个重要的问题是我们的模型是否可以找到图片中物体所在的局部区域来分辨出物体还是根据环境信息来判别。图4系统性的回答了这个问题,通过有计划的遮挡输入图片的某一部分,监测分类器的输出。实验证明,如果将图片的物体部分遮挡住了,输出的正确标签那一项的概率会迅速减小。如图所示,列1表示图像被随机遮挡,列2表示第五层特征图最强输出,列3带黑框为被遮挡后特征向量投影到像素空间,列4为被遮挡后分类的正确率,列5为被遮挡后最可能的分类。
图 4. 敏感性遮挡实验结果
5.总结
本文利用ImageNet 2012的数据库训练了一个8层的神经网络如图1所示,然后利用反卷积网络的方法来观察模型的特征。实验表明,卷积神经网络模型之所以有这么好的分类性能是有道理可循的,卷积神经网络层捕捉的特征虽然跟我们人类看到的不尽相同,但也有很强的层次和规律在其中,理解了这一点,可以帮助我们更好的设计和训练卷积网络模型。此外,通过敏感性遮挡实验验证,卷积网络模型在识别一个物体时,起重要判别依据的是物体本身而非背景环境等不相干的信息,这一点证明了卷积神经网络模型可用性强的特点。尽管卷积神经网络模型在图片分类领域已达到精湛的水平,但仍存在一些问题,图卷积神经网络虽然对略微位移和缩放的图片不会改变判别正确率,但是无法对旋转产生很好的鲁棒性。
最后,本篇课程小论文是拜读Matthew 等人论文[5]的读后笔记,感谢这些大牛们的在人工智能领域的奉献。
参考文献
[1] LeCun, Y., Boser, B., Denker, J.S., Henderson, D., Howard, R.E., Hubbard, W., Jackel, L.D.: Backpropagation applied to handwritten zip code recognizition. Neural Comput. 1(4), 541-551(1989).
[2] Hinton,G.E., Srivastave, N., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.R.: Improving neural networks by preventing co-adaptation of feature detectors. In: arXvi: 1207.0580(2012).
[3] Zeiler, M., Taylor, G., Fergus, R.: Adaptive deconvolutional networks for mid and high level feature learning. In: ICCV(2011).
[4] Deng, J., Dong, W., Socher, R., li, L.J., li, K., Fei-Fei, L.: ImageNet: A large scale hierarchical image database. In: CVPR 2009(2009).
[5] Matthew, D., Zeiler, M., Fergus, R.: Visualizing and understanding convolutional networks. In: ECCV(2014).

