

1. 文件系统从头说
2. Hadoop的文件系统
3. 如何将文件复制到HDFS
3.1 目录和文件结构
3.2 FileCopy.java文件的源代码
3.3 编译
3.4打包
3.5 运行
3.6 检查结果
1. 文件系统从头说
文件系统的作用就是永久存储数据。计算机可以存储数据的地方是内存,硬盘,优盘,SD卡等等。如果计算机断电关机,存放在内存里的数据就没有了,而存放在硬盘优盘SD卡这些上的数据会仍然存在。硬盘优盘SD卡上的数据是以文件的形式存在,文件系统就是文件的组织和处理。总之,凡是断电之后不会消失的数据,就必须由文件系统存储和管理。
从用户的角度来说,文件系统需要提供文件的创建,删除,读,写,追加,重命名,查看属性,更改属性等各种功能。文件夹,也叫目录,它的作用类似容器,保存其他文件夹和文件。于是,各级文件夹和各级文件就共同组成了文件系统的层次,看起来象一棵倒放的树,最上层是最大的目录,也叫根目录,然后这个目录包含子目录和文件,子目录又包含更多的子目录和文件,这棵树的术语叫目录树。
起初,Linux使用的文件系统是Minix文件系统。但Minix系统有不少限制,诸如最大文件尺寸只有64M,文件名最多是14个字符长度。后来,Linux内核加入了VFS,也就是虚拟文件系统Virtual File System。VFS是Linux内核和真正文件系统之间的抽象层,它提供统一的接口,真正的文件系统和Linxu内核必须通过VFS的接口进行沟通。随后,Linux逐步使用基于VFS的ext文件系统,ext2文件系统,ext3文件系统等等。基于VFS,Linux对Windows的FAT和NTFS格式也提供支持。
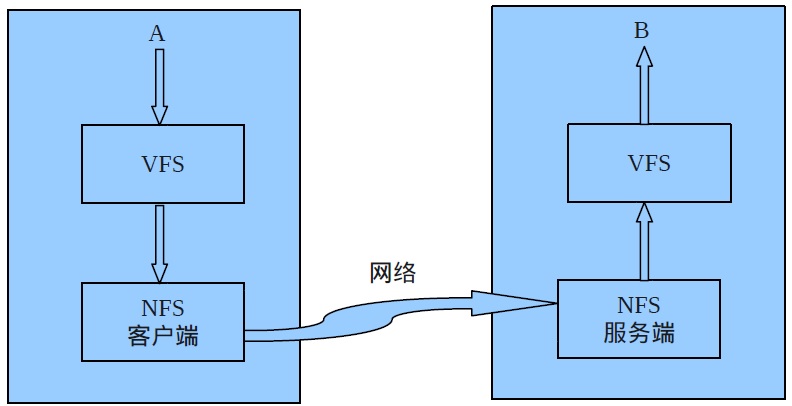
通常情况下,Linux的文件系统是单机的,也就说,从物理的角度看,文件系统只存储单台计算机的数据。分布式文件系统在物理上分散的计算机上存储数据。比如,NFS(NetWork File System)是一种非常经典的分布式文件系统,它基于VFS,由Sun公司开发的。本质上,NFS是在物理上分散的计算机之间增加了一个客户-服务器层。对NFS,可以这么理解:计算机A有自己的VFS,计算机B也有自己的VFS,那么,如果A想操作B上的文件,A的数据和命令依次通过的路线是:A的VFS-->A的NFS客户端-->网络-->B的NFS服务器端-->B的VFS-->B的文件系统。
2. Hadoop的文件系统
Hadoop借鉴了VFS,也引入了虚拟文件系统机制。HDFS是Hadoop虚拟文件系统的一个具体实现。除了HDFS文件系统之外,Hadoop还实现很多其他文件系统,诸如本地文件系统,支持HTTP的HFTP文件系统,支持Amazon的S3文件系统等等。
HDFS从设计上来说,主要考虑以下的特征:超大文件,最大能支持PB级别的数据;流式数据访问,一次写入,多次读取;在不可靠的文件,故障率高的商用硬件上能运行。Hadoop的不利之处,是不适应低时间延迟的数据访问,不适应大量的小文件,也不适应多用户写入任意修改文件的情况。
假设有一个HDFS集群,那么这个集群有且仅有一台计算机做名字节点NameNode,有且仅有一台计算机做第二名字节点SecondaryNameNode , 其他机器都是数据节点DataNode 。在伪分布式的运行方式下,
NameNode,SecodaryNameNode,DataNode都由同一台机器担任。
NameNode是HDFS的管理者。SecondaryNameNode是NameNode的辅助者,帮助NameNode处理一些合并事宜,注意,它不是NameNode的热备份,它的功能跟NameNode是不同的。DataNode以数据块的方式分散存储HDFS的文件。HDFS将大文件分割成数据块,每个数据块是64M,也可以设置成128M或者256M,然后将这些数据块以普通文件的形式存放到数据节点上,为了防止DataNode意外失效,HDFS会将每个数据块复制若干份放到不同的数据节点。
执行”hadoop fs -help”可以看到HDFS的命令行工具和用法。
如前所说,文件系统主要作用是提供文件的创建,删除,读,写,追加,重命名,查看属性,更改属性等各种功能 。在随后部分,本章选取若干功能,给出了HDFS的文件操作示例代码。熟悉这些之后会对HDFS的操作有一个形象了解。这样将来参考Hadoop API的FileSystem类及其相关子类,就可以写出更多的文件系统操作。

3. 如何将文件复制到HDFS
3.1 目录和文件结构
这个例子的功能跟”hadoop fs -put”是一样的。创建目录~/filecopy存放源代码、编译和打包结果。在filecopy目录下,有两个子目录,分别是src目录和classes目录,src目录存放Java源代码,class存放编译结果。在src目录下,只有一个源代码文件FileCopy.java。
3.2 FileCopy.java文件的源代码
apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; public class FileCopy { public static void main(String[] args) throws Exception
{ if (args.length != 2)
{ System.err.println("Usage: filecopy <source> <target>"); System.exit(2); }
Configuration conf = new Configuration(); InputStream in = new BufferedInputStream(new FileInputStream(args[0])); FileSystem fs = FileSystem.get(URI.create(args[1]), conf); OutputStream out = fs.create(new Path(args[1])); IOUtils.copyBytes(in, out, 4096, true); }
}
3.3 编译
“cd ~/filecopy”
“javac -cp /home/brian/usr/hadoop/hadoop-1.2.1/hadoop-core-1.2.1.jar -d ./classes ./src/*.java”
3.4打包
“jar -cvf filecopy.jar -C ./classes/ .”
3.5 运行
“cd /home/brian/usr/hadoop/hadoop-1.2.1”
“./bin/hadoop jar ~/filecopy/filecopy.jar com.brianchen.hadoop.FileCopy README.txt readme.txt”
首先确认Hadoop已经是运行的,然后切换到Hadoop的安装目录,仍然用README.txt做测试,将这个文件复制到HDFS,另存为readme.txt文件。
3.6 检查结果
“./bin/hadoop fs -ls”
执行这个命令可以看到readme.txt是否存在。
“./bin/hadoop fs -ls cat readme.txt”
输出readme.txt文件到屏幕查看其内容。

