

刨死你系列——LinkedHashMap剖析(基于jdk1.8)
一、概述
1.8版本的LinkedHashMap 继承自 HashMap,在 HashMap(数组链表+红黑树) 基础上,通过维护一条双向链表,解决了 HashMap 不能随时保持遍历顺序和插入顺序一致的问题。除此之外,LinkedHashMap 对访问顺序也提供了相关支持。在一些场景下,该特性很有用,比如缓存。在实现上,LinkedHashMap 很多方法直接继承自 HashMap,仅为维护双向链表覆写了部分方法。所以,在学习LinkedHashMap前,你要先了解HashMap。其结构可能如下图:

二、源码解析
2.1 Entry的继承体系
LinkedHashMap数据结构相比较于HashMap来说,添加了双向指针,分别指向前一个节点——before和后一个节点——after,从而将所有的节点已链表的形式串联一起来,让我们来看一下它们的继承关系。
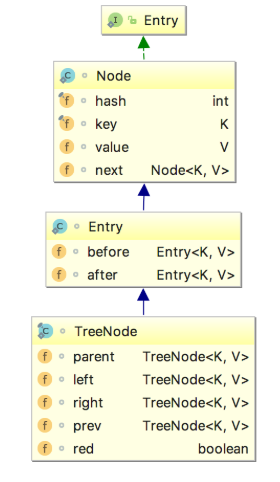
HashMap 的内部类 TreeNode 不继承它的了一个内部类 Node,却继承自 Node 的子类 LinkedHashMap 内部类 Entry。这里这样做是有一定原因的,这里先不说。先来简单说明一下上面的继承体系。LinkedHashMap 内部类 Entry 继承自 HashMap 内部类 Node,并新增了两个引用,分别是 before 和 after。这两个引用的用途不难理解,也就是用于维护双向链表。同时,TreeNode 继承 LinkedHashMap 的内部类 Entry 后,就具备了和其他 Entry 一起组成链表的能力。
2.2成员变量
具体看下面代码:
private static final long serialVersionUID = 3801124242820219131L; // 用于指向双向链表的头部 transient LinkedHashMap.Entry<K,V> head; //用于指向双向链表的尾部 transient LinkedHashMap.Entry<K,V> tail; /** * 用来指定LinkedHashMap的迭代顺序, * true则表示按照基于访问的顺序来排列,意思就是最近使用的entry,放在链表的最末尾 * false则表示按照插入顺序来 */ final boolean accessOrder;
2.3构造方法
由于LinkedHashMap继承HashMap,构造方法基本类似,唯一的区别就是添加了前面提到的accessOrder,默认赋值为false——按照插入顺序来排列,这里主要说明一下不同的构造方法。
//多了一个 accessOrder的参数,用来指定按照LRU排列方式还是顺序插入的排序方式 public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder; }
LRU(Least Recently Used)最近最久未使用算法。会在后面介绍该算法.
2.4 put()方法
让我们来看一下LinkedHashMap是怎么插入Entry的:LinkedHashMap的put方法调用的还是HashMap里的put,不同的是重写了里面的部分方法,一起来看一下:
//HashMap的put方法 final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { ... tab[i] = newNode(hash, key, value, null); ... e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); ... if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); ... afterNodeAccess(e); ... afterNodeInsertion(evict); return null; }
由于在前面的文章HashMap, 分析过了put方法,这里笔者就省略了部分代码,LinkedHashMap将其中newNode方法以及之前设置下的钩子方法afterNodeAccess和afterNodeInsertion进行了重写,从而实现了加入链表的目的。一起来看一下:
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) { //秘密就在于 new的是自己的Entry类,然后调用了linkedNodeLast LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e); linkNodeLast(p); return p; } //顾名思义就是把新加的节点放在链表的最后面 private void linkNodeLast(LinkedHashMap.Entry<K,V> p) { //将tail给临时变量last LinkedHashMap.Entry<K,V> last = tail; //把new的Entry给tail tail = p; //若没有last,说明p是第一个节点,head=p if (last == null) head = p; //否则就做准备工作,你懂的 ( ̄▽ ̄)" else { p.before = last; last.after = p; } } //把TreeNode的重写也加了进来,因为putTreeVal里有调用了这个 TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) { TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next); linkNodeLast(p); return p; } //插入后把最老的Entry删除,不过removeEldestEntry总是返回false,所以不会删除,估计又是一个钩子方法给子类用的 void afterNodeInsertion(boolean evict) { LinkedHashMap.Entry<K,V> first; if (evict && (first = head) != null && removeEldestEntry(first)) { K key = first.key; removeNode(hash(key), key, null, false, true); } } protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { return false; }
2.5 remove()方法
与插入操作一样,LinkedHashMap 删除操作相关的代码也是直接用父类的实现。在删除节点时,父类的删除逻辑并不会修复 LinkedHashMap 所维护的双向链表,这不是它的职责。那么删除及节点后,被删除的节点该如何从双链表中移除呢?当然,办法还算是有的。上一节最后提到 HashMap 中三个回调方法运行 LinkedHashMap 对一些操作做出响应。所以,在删除及节点后,回调方法 afterNodeRemoval 会被调用。LinkedHashMap 覆写该方法,并在该方法中完成了移除被删除节点的操作。相关源码如下:
// HashMap 中实现 public V remove(Object key) { Node<K,V> e; return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value; } // HashMap 中实现 final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) { Node<K,V>[] tab; Node<K,V> p; int n, index; if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) { Node<K,V> node = null, e; K k; V v; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) node = p; else if ((e = p.next) != null) { if (p instanceof TreeNode) {...} else { // 遍历单链表,寻找要删除的节点,并赋值给 node 变量 do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e; break; } p = e; } while ((e = e.next) != null); } } if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) { if (node instanceof TreeNode) {...} // 将要删除的节点从单链表中移除 else if (node == p) tab[index] = node.next; else p.next = node.next; ++modCount; --size; afterNodeRemoval(node); // 调用删除回调方法进行后续操作 return node; } } return null; } // LinkedHashMap 中覆写 void afterNodeRemoval(Node<K,V> e) { //与afterNodeAccess一样,记录e的前后节点b,a LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; //p已删除,前后指针都设置为null,便于GC回收 p.before = p.after = null; //与afterNodeAccess一样类似,一顿判断,然后b,a互为前后节点 if (b == null) head = a; else b.after = a; if (a == null) tail = b; else a.before = b; }
删除的过程并不复杂,上面这么多代码其实就做了三件事:
- 根据 hash 定位到桶位置
- 遍历链表或调用红黑树相关的删除方法
- 从 LinkedHashMap 维护的双链表中移除要删除的节点
2.6 get()方法
默认情况下,LinkedHashMap 是按插入顺序维护链表。不过我们可以在初始化 LinkedHashMap,指定 accessOrder 参数为 true,即可让它按访问顺序维护链表。访问顺序的原理上并不复杂,当我们调用get/getOrDefault/replace等方法时,只需要将这些方法访问的节点移动到链表的尾部即可。相应的源码如下:
public V get(Object key) { Node<K,V> e; //调用HashMap的getNode的方法,详见上一篇HashMap源码解析 if ((e = getNode(hash(key), key)) == null) return null; //在取值后对参数accessOrder进行判断,如果为true,执行afterNodeAccess if (accessOrder) afterNodeAccess(e); return e.value; }
从上面的代码可以看到,LinkedHashMap的get方法,调用HashMap的getNode方法后,对accessOrder的值进行了判断,我们之前提到:
//accessOrder为true则表示按照基于访问的顺序来排列,意思就是最近使用的entry,放在链表的最末尾
由此可见,afterNodeAccess(e)就是基于访问的顺序排列的关键,让我们来看一下它的代码:
//此函数执行的效果就是将最近使用的Node,放在链表的最末尾 void afterNodeAccess(Node<K,V> e) { LinkedHashMap.Entry<K,V> last; //仅当按照LRU原则且e不在最末尾,才执行修改链表,将e移到链表最末尾的操作 if (accessOrder && (last = tail) != e) { //将e赋值临时节点p, b是e的前一个节点, a是e的后一个节点 LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; //设置p的后一个节点为null,因为执行后p在链表末尾,after肯定为null p.after = null; //p前一个节点不存在,情况一 if (b == null) // ① head = a; else b.after = a; if (a != null) a.before = b; //p的后一个节点不存在,情况二 else // ② last = b; //情况三 if (last == null) // ③ head = p; //正常情况,将p设置为尾节点的准备工作,p的前一个节点为原先的last,last的after为p else { p.before = last; last.after = p; } //将p设置为将p设置为尾节点 tail = p; // 修改计数器+1 ++modCount; } }
标注的情况如下图所示(特别说明一下,这里是显示链表的修改后指针的情况,实际上在桶里面的位置是不变的,只是前后的指针指向的对象变了):

下面来简单说明一下:
-
正常情况下:查询的p在链表中间,那么将p设置到末尾后,它原先的前节点b和后节点a就变成了前后节点。
- 情况一:p为头部,前一个节点b不存在,那么考虑到p要放到最后面,则设置p的后一个节点a为head
- 情况二:p为尾部,后一个节点a不存在,那么考虑到统一操作,设置last为b
-
情况三:p为链表里的第一个节点,head=p
2.7 基于 LinkedHashMap 实现缓存
在上节中,说到LRU算法,我I们通过继承LinkedHashMap实现了一个简单的 LRU 策略的缓存。在实践前我们要补充部分知识:
void afterNodeInsertion(boolean evict) { // possibly remove eldest LinkedHashMap.Entry<K,V> first; // 根据条件判断是否移除最近最少被访问的节点 if (evict && (first = head) != null && removeEldestEntry(first)) { K key = first.key; removeNode(hash(key), key, null, false, true); } } // 移除最近最少被访问条件之一,通过覆盖此方法可实现不同策略的缓存 protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { return false; }
上面的源码的核心逻辑在一般情况下都不会被执行,所以之前并没有进行分析。上面的代码做的事情比较简单,就是通过一些条件,判断是否移除最近最少被访问的节点。看到这里,大家应该知道上面两个方法的用途了。当我们基于 LinkedHashMap 实现缓存时,通过覆写removeEldestEntry方法可以实现自定义策略的 LRU 缓存。比如我们可以根据节点数量判断是否移除最近最少被访问的节点,或者根据节点的存活时间判断是否移除该节点等。本节所实现的缓存是基于判断节点数量是否超限的策略。在构造缓存对象时,传入最大节点数。当插入的节点数超过最大节点数时,移除最近最少被访问的节点。实现代码如下:
//作者:https://segmentfault.com/a/1190000012964859
public class SimpleCache<K, V> extends LinkedHashMap<K, V> { private static final int MAX_NODE_NUM = 100; private int limit; public SimpleCache() { this(MAX_NODE_NUM); } public SimpleCache(int limit) { super(limit, 0.75f, true); this.limit = limit; } public V save(K key, V val) { return put(key, val); } public V getOne(K key) { return get(key); } public boolean exists(K key) { return containsKey(key); } /** * 判断节点数是否超限 * @param eldest * @return 超限返回 true,否则返回 false */ @Override protected boolean removeEldestEntry(Map.Entry<K, V> eldest) { return size() > limit; } }
测试代码如下:
public class SimpleCacheTest { @Test public void test() throws Exception { SimpleCache<Integer, Integer> cache = new SimpleCache<>(3); for (int i = 0; i < 10; i++) { cache.save(i, i * i); } System.out.println("插入10个键值对后,缓存内容:"); System.out.println(cache + "\n"); System.out.println("访问键值为7的节点后,缓存内容:"); cache.getOne(7); System.out.println(cache + "\n"); System.out.println("插入键值为1的键值对后,缓存内容:"); cache.save(1, 1); System.out.println(cache); } }
测试结果:

不过笔者自己也通过继承LinkedHashMap实现了LRU算法,感兴趣的小伙伴可以看看!
2.8 小结
本文对 LinkedHashMap 的源码put,get,remove进行了分析,并在文章的结尾基于 LinkedHashMap 实现了一个简单的 Cache。在日常开发中,LinkedHashMap 的使用频率虽不及 HashMap,但它也个重要的实现。在 Java 集合框架中,HashMap、LinkedHashMap 和 TreeMap 三个映射类基于不同的数据结构,并实现了不同的功能。HashMap 底层基于拉链式的散列结构,并在 JDK 1.8 中引入红黑树优化过长链表的问题。基于这样结构,HashMap 可提供高效的增删改查操作。LinkedHashMap 在其之上,通过维护一条双向链表,实现了散列数据结构的有序遍历。TreeMap 底层基于红黑树实现,利用红黑树的性质,实现了键值对排序功能。
由于个人能力问题,先学习这些,数据结构这个大山,我一定要刨平它。
参考博客:https://segmentfault.com/a/1190000012964859
https://blog.csdn.net/ShelleyLittlehero/article/details/82957336

