

将爬取的实习僧网站数据传入HDFS
一、引言:
作为一名大三的学生,找实习对于我们而言是迫在眉睫的。实习作为迈入工作的第一步,它的重要性不言而喻,一份好的实习很大程度上决定了我们以后的职业规划。
那么,一份好的实习应该考量哪些因素呢?对于我们计算机专业的学生而言现在的实习趋势是什么呢?
我从实习僧网站爬取了5000条全国互联网行业的职位信息(时间节点06/17),下面开始从职位、薪资、地点、时长、工作要求五个维度进行分析。
二、数据提取与分析
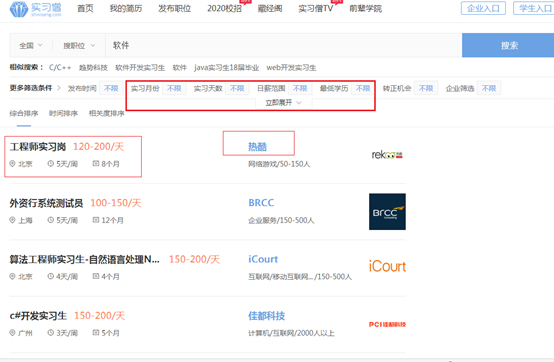
- 爬取的页面
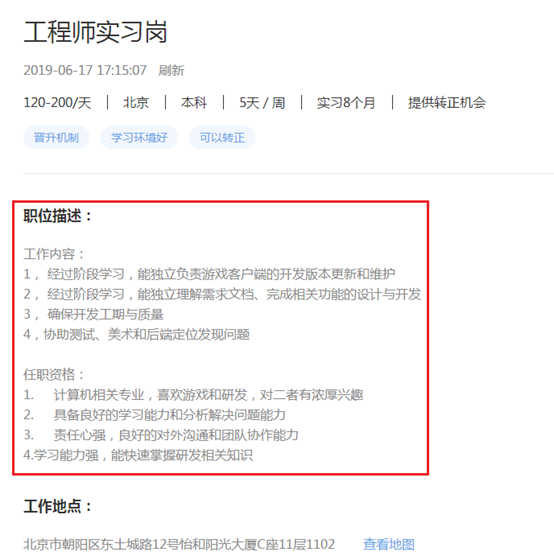
软件类实习中的实习月份需求、实习天数需求、实习岗位、公司名称、薪资范围 和 职业描述(这个需要在 点击实习名称 后 的页面中实现)
- 数据获取工具
主要工具:Python 3.6、Excel2016
涉及爬虫库:requests、Beautiful Soup
涉及反爬虫库:fontTools.ttLib
涉及可视化库:matplotlib、wordcloud、pyecharts
- 使用反爬虫手段对解析页面的数据进行清洗
爬虫是一段自动获取网站数据的程序,一些网站为了保护数据或者避免爬虫过多对服务器造成太大压力就使用了反爬虫技术,在我们所获取信息的实习僧网站就用了反爬虫技术。
由此我们的爬取需要解析完他们某个时间段内的反爬虫代码之后,在一次性、有限内爬完不然将会在爬到一半的时候无法解析实习僧网站的反爬虫代码,爬出来的数据将会是空。
- 部分代码
通过选取实习僧网页中的数字,在中文转换网站转换编码后,得出下面数字的编码。
# 数字解析 replace_dict = { '\ueae5': '0', '\ueff5': '1', '\uf17d': '2', '\ue5f2': '3', '\uf5ce': '4', '\uf5e8': '5', '\uef8f': '6', '\ue64a': '7', '\ued3c': '8', '\uf775': '9', }
def get_pageInfo(urlList,replace_dict): ''' 解析request获取的信息 :param urlList: 保存url :param replace_dict: 数字解析 :return: 无 ''' info={} for url in urlList: response=requests.get(url) soup = BeautifulSoup(response.content, 'html.parser', from_encoding="utf-8") text = soup.prettify() for key, value in replace_dict.items(): text = text.replace(key, value) soup = BeautifulSoup(text, 'html.parser') jobName=soup.select('.new_job_name')[0].text.strip() jobMoney=soup.select('.job_money')[0].text.strip() jobPosition=soup.select('.job_position')[0].text.strip() jobAcademic=soup.select('.job_academic')[0].text.strip() jobWeek=soup.select('.job_week')[0].text.strip() jobTime=soup.select('.job_time')[0].text.strip() jobDetail=soup.select('.job_detail')[0].text.replace(' ','').replace('\n','') comName=soup.select('.com-name')[0].text.strip() info['jobName']=jobName info['jobMoney']=jobMoney info['jobPosition']=jobPosition info['jobAcademic']=jobAcademic info['jobWeek']=jobWeek info['jobTime']=jobTime info['jobDetail']=jobDetail info['comName']=comName save_item(info)
- 爬取结果展示

- 词云分析

这次爬取的信息一共5000条,除去无用信息一共有4700+数据,可以看到所有岗位中最热门的当属软件测试,可以说软件工程和运营类的同学相对来说最容易找到实习。
紧随其后的则是前端,java,数据分析之类。
一.将爬虫大作业产生的csv文件上传到HDFS

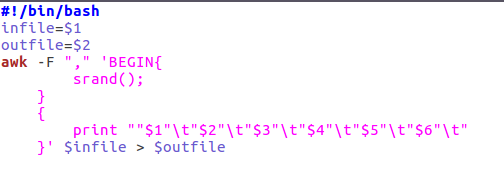
二.对CSV文件进行预处理生成无标题文本文件

三.把hdfs中的文本文件最终导入到数据仓库Hive中
启动数据库后开启hive —> 查看数据库是否传入—>在数据仓库中建表
service mysql start #启动mysql数据库


四.在Hive中查看并分析数据
查看全部信息验证是否上传成功:1 select * from yh.data limit 20(前20条)
2:查看在HIVE中csv文档的工作名称前200条内容。

五.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
1.查看发布招工数量最多的城市。最终结论:北上广深还是名列前四,经济越发达的地区招实习生的数量也是比较多的,其中北京和上海的招实习生数量更是广州和深圳的2-3倍之多。
接着就是杭州、成都、南京等二线城市。


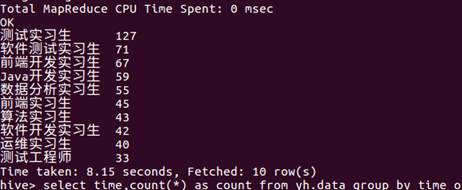
2.通过数量多少排序,将每个招聘的名称进行统计,最后得出测试实习生是招实习生最多包括软件测试实习生在内的一个职业有198个,再是前端开发和java开发都在70个左右。
由此可见,现阶段关于软件相关职业而言,测试岗位还是比较缺人的。

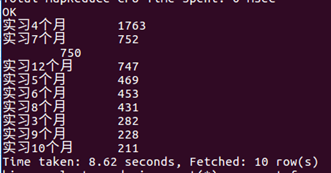
3.将实习周期进行统计排名得出,一般单位会要求你实习4个月,再而是7个月,经过调查了解7个月的一般都是签订了三方协议,以保障公司和实习生的利益。

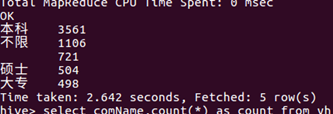
4.经过对学历要求的统计,目前来讲,本科的要求是比较多的有3561超过统计总数的五分之三。第二个是不限学历,第三个是硕士生再后就是大专。由此可见对于当代的就职而言,相较于本科生和大专生,本科生的择业选择多于大专生。

5.将本科生的薪资统计和排名得出,对于本科类学业的学生而言,工资一般是100-200这个区间所占的比例比较大。


6.将专科的工资进行排名和统计得出,对于专科毕业的学生而言,一般也是100-150,。从数据上看相比较于本科生而言,专科生的平均实习工资会比本科生少80左右。

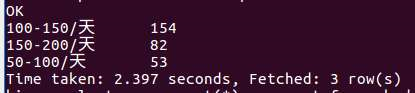
7.这个是对硕士生的薪资的排名,结果是150-200的居多,100-150的排名第三,所以三个数据一起看我们也可以得出结论,学历越高找到高薪资的可能性会更大。

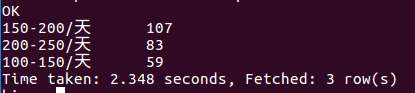
8.对所发布应聘的公司进行统计,发布兼职数目最多的是CVPR,ECCV这些企业,然后是亚信科技 和 字节跳动(抖音)而且他们基本是在北京。

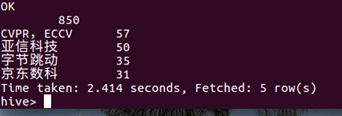
9.对所有城市的工资做一个统计。一般是11-150的居多,其次是150-200的。所有如果以后找实习,工资找到100-200的算是差不多的了。

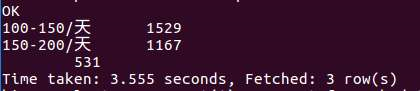
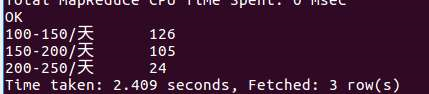
10对广州的薪资情况进行分析,大部分的工资是100-150,少数为50-100及面议。如果有想从事软件方面的小伙伴考虑以后可能在广州工作的话可以参考100-150这个薪资区间。

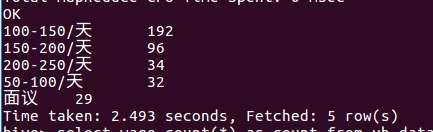
11.这个是对深圳的薪资分析,相比于广州,深圳的工资100-150和150-200所占的比例相差不大。如果有软件专业的同学对于以后工作的地点是在广州还是深圳之间有所犹豫的话,这个结论也是可以当做参考的。

总结~~
对于想软件方面职业的朋友而言,学历越高的朋友找工作的薪资会更高一点,在北上广深这些经济发达的地方找工作会比二三线城市方便 找到工作且薪资普遍会比较高一些。一般北京的公司规模会大一些,需要招收的实习生也是比较多的。在现阶段,本科生是大部分公司的招人方向。硕士生的薪资一般是150-250,本科学生的薪资一般是100-200居多,专科生普遍50-150。工作时长一般是要求实习4个月,其次是7个月。
测试实习生是招实习生最多包括软件测试实习生在内的一个职业有198个,再是前端开发和java开发都在70个左右。现阶段关于软件相关职业而言,测试岗位还是比较缺人的。

