
搭建hadoop、hdfs环境--ubuntu(完全分布式)
最近在学习hadoop相关知识,就在本机上安装了hadoop,遇到了一些坑,也学到了不少。仅此记录我的安装过程,及可能遇到的问题。供参考。交流沟通见页末。
软件准备
> 虚拟机(VMware)
个人情况下,不太可能有多台电脑,装一个虚拟机来进行实验。虚拟机中我用的是Linux的ubuntu版本。
具体安装就不在这里说明了,提示的是:安装的网络模式选bridged,如果出现无法上网或者不能与本机链接,可以使用多网卡,增加NAT模式(如工作网络导致这种情况)。
>hadoop:去apache下载hadoop(http://hadoop.apache.org/releases.html),我选的是2.6.5版本;

> Java环境
JDK:去(http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html)下载jdk,我选的是tar.gz,这样就知道解压到哪里了。

> WinScp
后期三台虚拟机之间需要进行文件的互通,这里使用winscp可能会更方便(当然也有其他方式,比如wget下载网络文件,scp进行虚拟机之间的文件传输。)
安装啦!
>第一步:装好VMware,创建三个虚拟机(hadoop至少需要三个,一个master,两个node。为什么需要以后再说啦!)并将下载的hadoop2.6.5和jdk导入到VMware中
chap1:VMware:有master、nod1、nod2,使用的是个人创建账号(shj,网络上都是创建了hadoop账号来进行管理,我这里就不费那个事了。)

通过WinScp导入文件时,提示虚拟机没有开启SFTP服务。这时需要对虚拟机做一些配置。
chap2:开通SSH服务:进入虚拟机的命令行(CRTL+ALT+T),使用root账号(sudo su )

首先更新源文件(atp-get update)-->下载/安装yum文件(apt-get install -y yum)-->下载/安装ssh服务(apt-get install -y openssh-server)-->启动服务(service ssh start,默认开启 )
 --->
--->
chap3:文件传输:使用WinScp成功登陆到虚拟机中,将hadoop和jdk文件导入。我放到/home/shj/Documents中
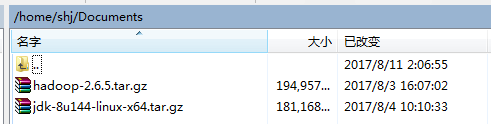
chap4:解压文件到指定目录
切换回shj账号(su shj)
hadoop解压:tar -xzvf /home/shj/Documents/hadoop-2.6.5.tar.gz -C ~/hadoop --->将压缩文件解压到指定目录中(没有该目录则创建,mkdir -p ~/hadoop)
jdk解压:tar -xzvf /home/shj/Documents/jdk-8u144linux-x64.tar.gz -C~/jdk --->将压缩文件解压到指定目录中(同上)

另外两台机器,重复上述操作。
第二步:配置SSH秘钥
我们使用的shj账号,配置的目的使得三台虚拟机能够通过该账号相互进行通信。(对root账号,不可行)
chap1:生成ssh密钥对(私钥和公钥)
mkdir -p ~/.ssh(如果没有.ssh则生成一个,ubuntu的好像是没有的) -->ssh-keygen -t dsa -p '' -f ~/.ssh/key_id(生成ssh密钥对,放在~/.ssh目录下)
将生成的key_id.pub写入文件(authorized_keys)中,确保文件名没有问题。
chap2:进行本机的免密登录:ssh localhost
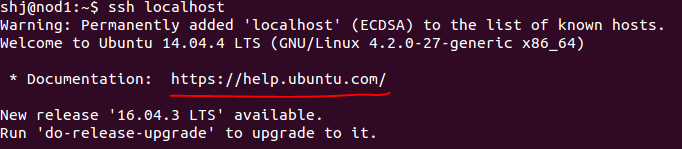
如果报错,要求输入密码,则有问题(一般重启一下就可以了,如果还有问题,则可能是你的家目录和私钥的权限不对,导致系统不允许免密登录)
chap3:另外两台机器同等操作
同chap2
chap4:汇总三台虚拟机的key_id.pub,三个公钥追加到同一个authorized_keys

通过scp命令(WinScp也可以)将三个公钥并共享该公钥。也就是三台虚拟机的公钥是相同的。
chap5:配置/etc/hosts、/etc/hostname文件
将ip对应的主机名进行映射
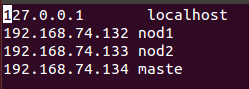
chap6:三台虚拟机之间的免密登录(修改了配置文件,服务需要重启。)

第一次登录,会问要不要。当然yes啦!!!完成这一步了。
第三步:配置系统环境
这一步我们需要告诉Linux,我们装的东西在哪里,装了哪些命令
配置系统环境变量(vim /etc/bash.bashrc)
在文件末尾追加:
export JAVA_HOME=/home/shj/jdk(这里我做了一些变化,解压后的地址应该不是这些。以实际为准)
export HADOOP_INSTALL=/home/shj/hadoop(同上)
export PATH=$PATH:/home/shj/hadoop/bin:/home/shj/jdk/bin(同上)

完成后,激活一下配置。执行命令:source /etc/bash.bashrc
验证jdk是否完成配置:java -version

没有问题!
另外两台机器,重复上述(也可以后期拷贝到另外两台机器上。见仁见智!)
第四步:配置hadoop的site文件
>chap1:四个文件(地址:~/hadoop/etc/hadoop)
core-site.xml(全局配置)、mapred-site.xml(MR配置)、hdfs-site.xml(hdfs配置)、hadoop-env.sh(...)
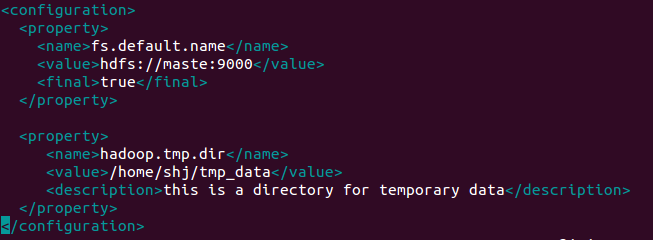
文件: core-site.xml
文件:mapred-site.xml.template
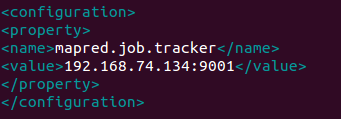
文件:hdfs-site.xml
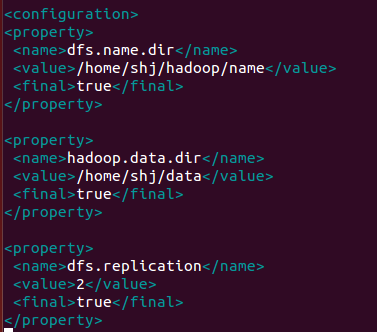
文件:hadoop-env.sh

需要绝对路径,要不然会有问题的!
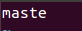
>chap2:写主机名文件
vim masters
vim slaves
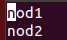
>chap3:将配置的文件同步到另外两台机器

完成所有机器相同配置
第四步:启动hadoop
如果这些事情都做完了(当然系统配置不要忘了,这个用scp不好使。)那么我们开始启动我们的hadoop吧(如果困难,重启试试)
> chap1:格式化
在master节点上格式化:hadoop namenode -format

> cha2:启动
cd ~/hadoop/sbin -->source start-all.sh -->没有问题,则执行命令:jps
在master节点执行jps
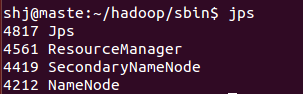
在node节点执行jps

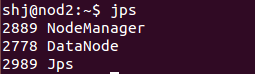
这样就结束了。成功的启动了你的hadoop。
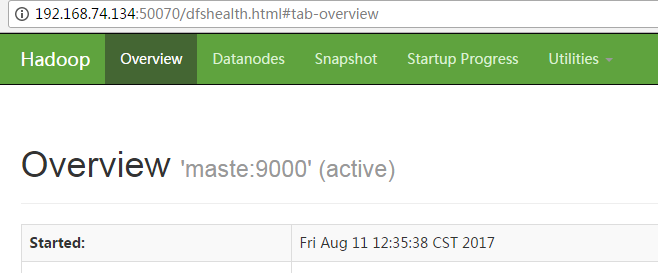
hadoop支持web界面,可以在浏览器中输入http://192.168.74.134:50070
你可以在web界面中查看你的hadoop运行情况。是不是很爽?!
注意事项/个人经验
1、由于是dhcp网络配置,如果重启可能会导致ip地址的变化,这个时候要么将网络设置成静态网络要么重新配置一些/etc/hosts文件
2、不同的阶段问题的的原因可能不一样,其中ssh配置出的问题会多一点。基本上重启一下就能解决。
3、在启动hadoop时,如果遇到问题就查看对应目录下的/hadoop/logs文件。master和node哪个错了,查看哪个的日志,直接翻到最后一行,往上捋
转载请注明出处!欢迎邮件沟通:shj8319@sina.com

