

一、微博API
使用微博API获取数据是最简单方便,同时数据完整性高的方式,缺点是微博开发平台对于API的调用次数做了严格的限制。具体使用过程参考http://open.weibo.com/,有详细的教程,对于API次数的限制,我们是通过注册多个开发者账号来绕过,对于某个IP调用API次数的限制,暂时没办法解决。微博API是通过httpclient发起请求,返回json形式的数据。对于数据重复获取方面,也有专门的接口通过参数控制获取增量数据。优点:简单,数据完整性高,增量简单。缺点:API次数有严格限制,数据量小。
二、抓取API数据
可以通过Jsoup来模拟浏览器的HTTP请求,Jsoup绕过微博登陆的方法就是设置cookie,对于获取回来的HTML页面,Jsoup也可以方便的进行解析,但是微博的数据比较特殊,页面是异步加载的,通过JS函数插入到指定div内,所以是通过自己写正则或者自己想办法解析,但是由于数据是异步加载,可能有时候会失败。但是页面内微博数据的获取是正确,完整度高的。优点:可并发,无次数限制,数据完整性高。缺点:有失败可能。
通过weibo.com/login.php 获取数据需要设置cookie,且数据是异步加载,有失败的可能,对于weibo.cn的数据是同步加载的,但是由于页面元素简单,所以数据完整度低,对于增量数据获取以及数据判断去重复方面,不容易进行。对于weibo.cn可以通过在URL请求中加入gsid参数,绕过登陆检验,比设置cookie简单些。优点:可并发,数据获取没有失败可能。
参考博客:http://fair-jm.iteye.com/blog/2046031
参考博客:https://segmentfault.com/a/1190000000498692
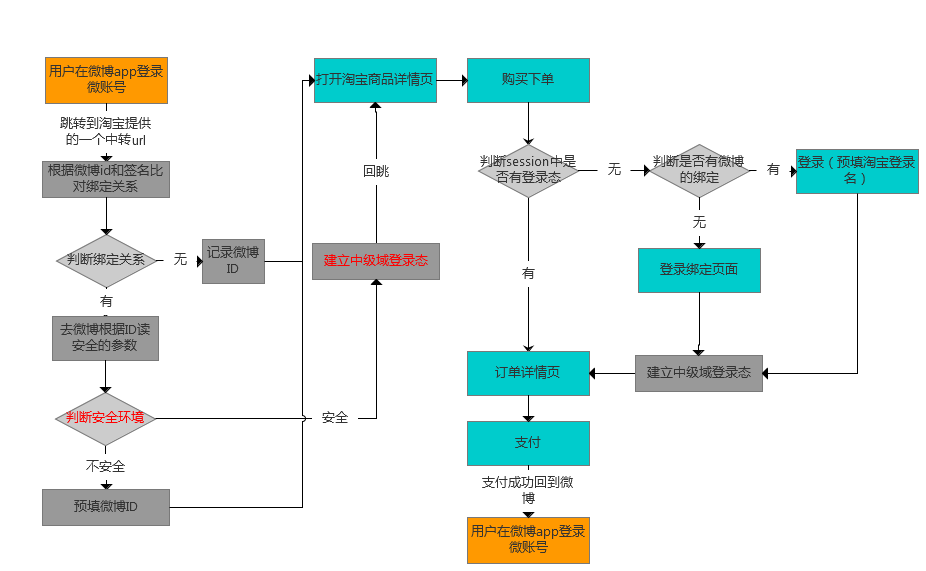
二、通过微博跳转淘宝的免登方案大致流程图:
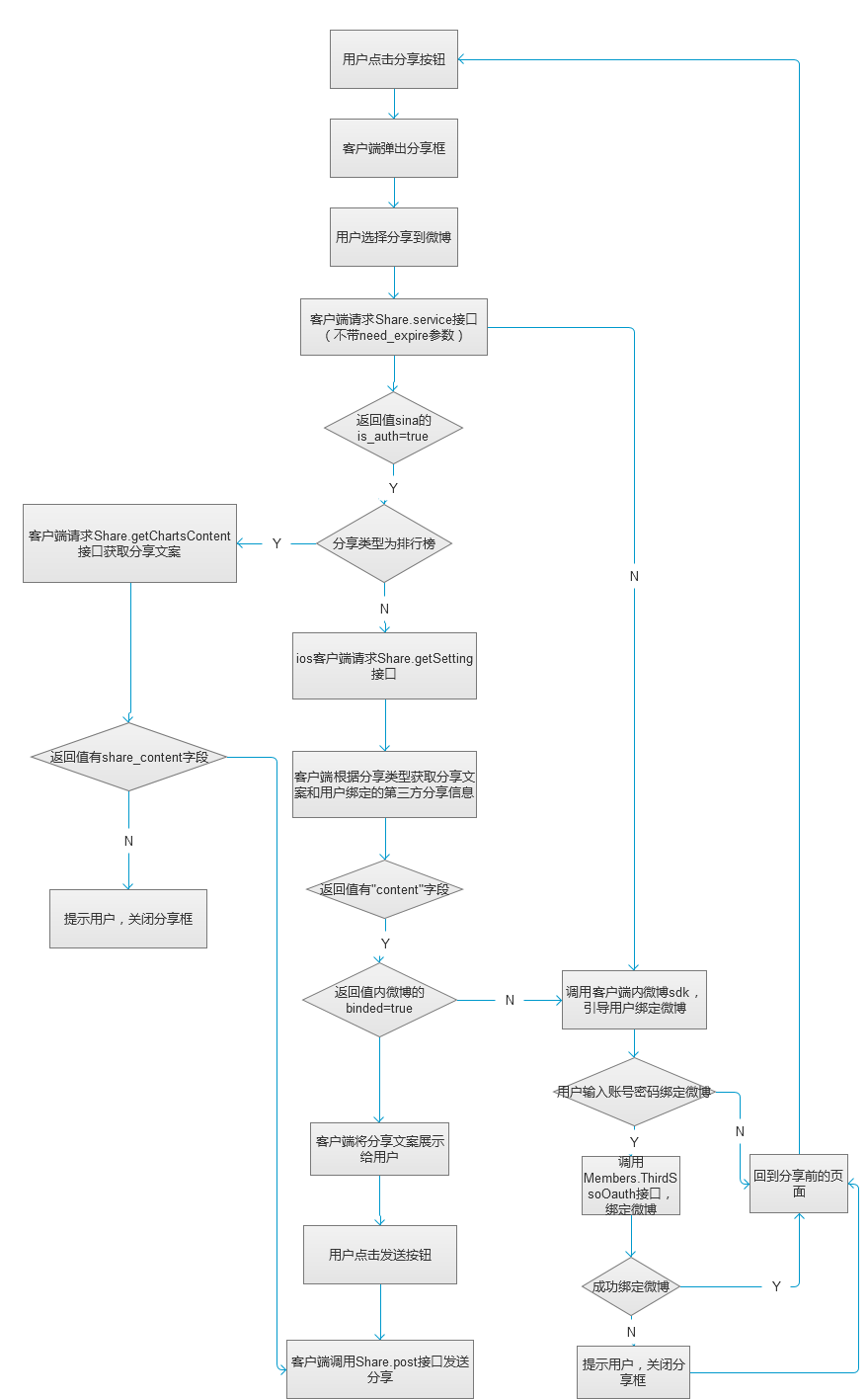
分享到微博的大致流程图:

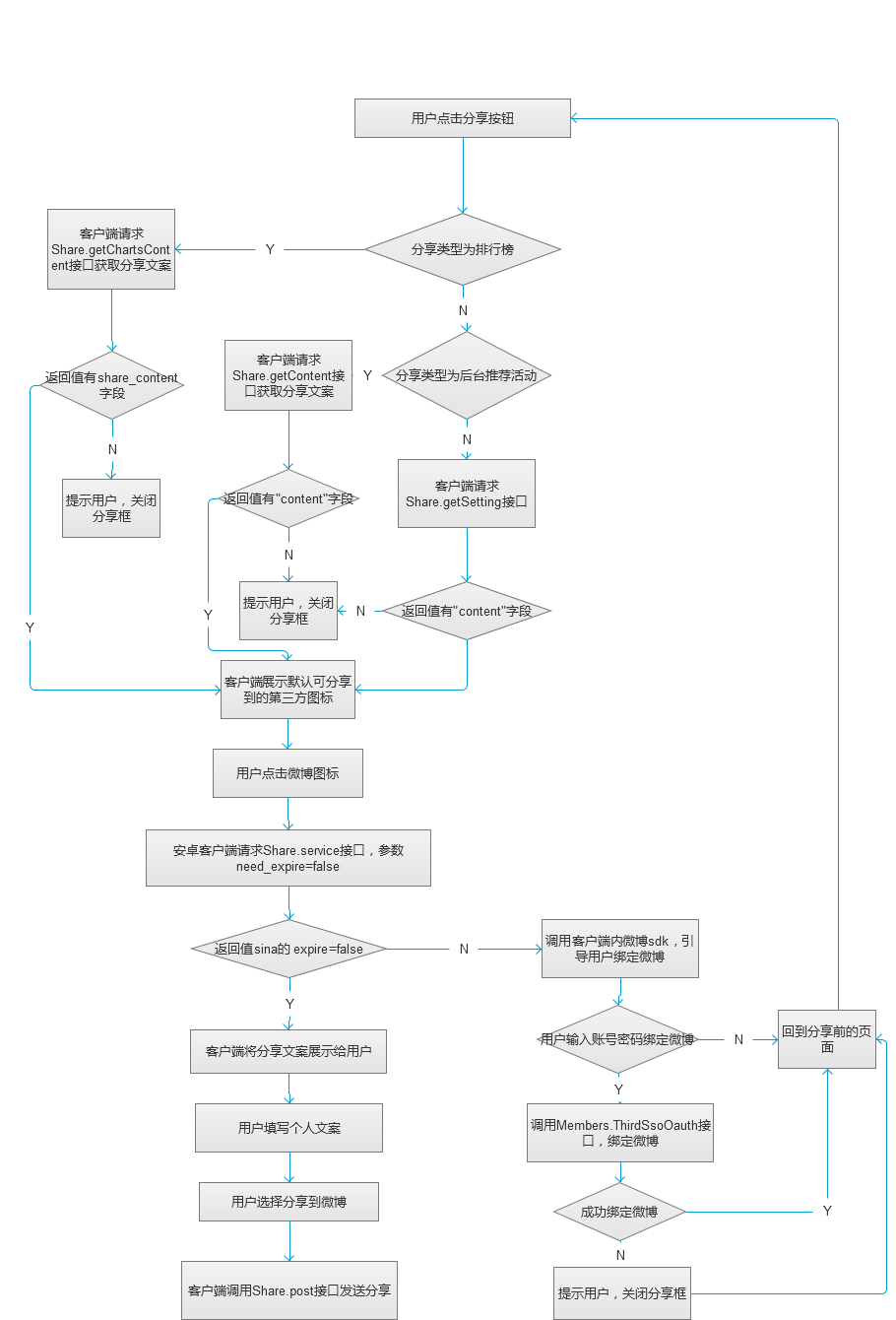
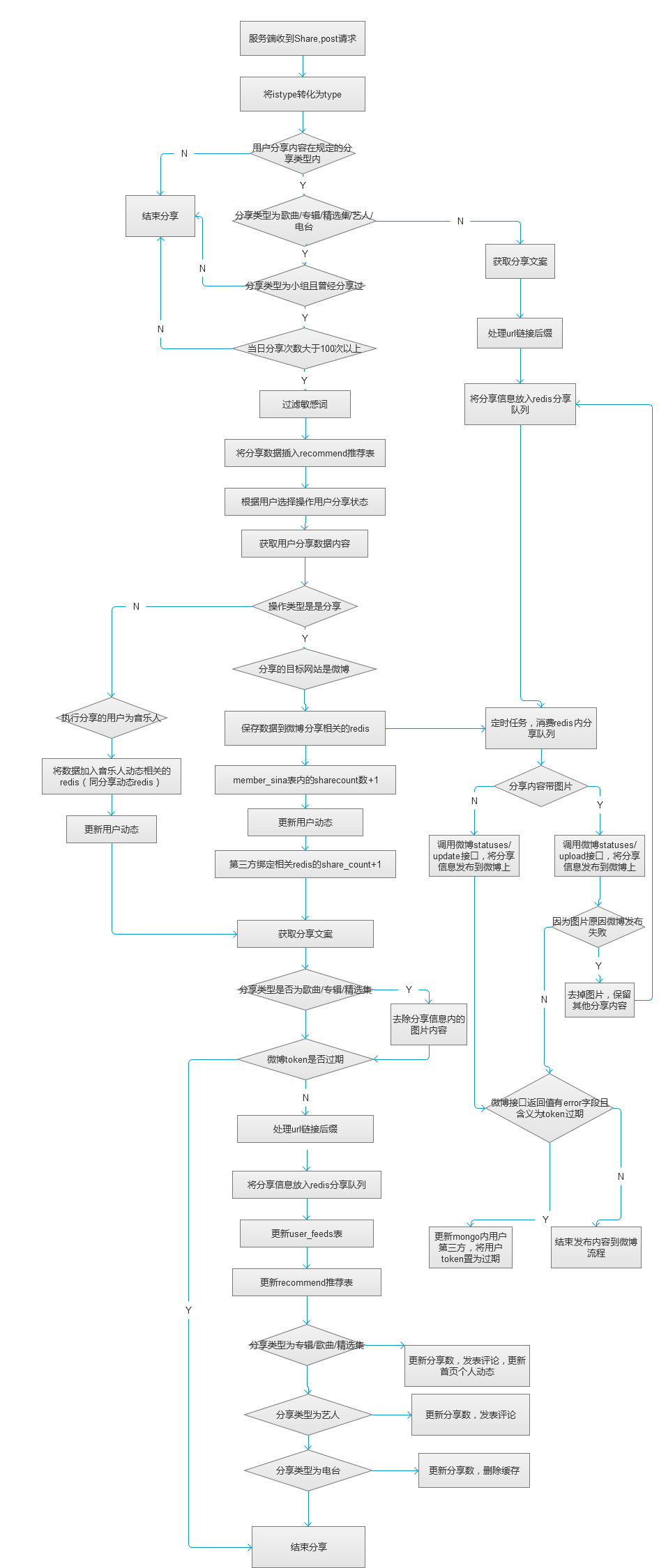
。

