瘋耔java语言笔记
一◐ java概述
1.1 Java的不同版本:J2SE、J2EE、J2ME的区别
1998年12月,SUN公司发布了Java 1.2,开始使用“Java 2” 这一名称,目前我们已经很少使用1.2之前的版本,所以通常所说的Java都是指Java2。
Java 有三个版本,分别为 J2SE、J2EE和J2ME,以下是详细介绍。
J2SE(Java 2 Platform Standard Edition) 标准版
J2SE是Java的标准版,主要用于开发客户端(桌面应用软件),例如常用的文本编辑器、下载软件、即时通讯工具等,都可以通过J2SE实现。
J2SE包含了Java的核心类库,例如数据库连接、接口定义、输入/输出、网络编程等。
学习Java编程就是从J2SE入手。
J2EE(Java 2 Platform Enterprise Edition) 企业版
J2EE是功能最丰富的一个版本,主要用于开发高访问量、大数据量、高并发量的网站,例如美团、去哪儿网的后台都是J2EE。通常所说的JSP开发就是J2EE的一部分。
J2EE包含J2SE中的类,还包含用于开发企业级应用的类,例如EJB、servlet、JSP、XML、事务控制等。
J2EE也可以用来开发技术比较庞杂的管理软件,例如ERP系统(Enterprise Resource Planning,企业资源计划系统)。
J2ME(Java 2 Platform Micro Edition) 微型版
J2ME 只包含J2SE中的一部分类,受平台影响比较大,主要用于嵌入式系统和移动平台的开发,例如呼机、智能卡、手机(功能机)、机顶盒等。
在智能手机还没有进入公众视野的时候,你是否还记得你的摩托罗拉、诺基亚手机上有很多Java小游戏吗?这就是用J2ME开发的。
Java的初衷就是做这一块的开发。
注意:Android手机有自己的开发组件,不使用J2ME进行开发。
Java5.0版本后,J2SE、J2EE、J2ME分别更名为Java SE、Java EE、Java ME,由于习惯的原因,我们依然称之为J2SE、J2EE、J2ME。
1.2 Java类库及其组织结构(Java API)
Java 官方为开发者提供了很多功能强大的类,这些类被分别放在各个包中,随JDK一起发布,称为Java类库或Java API。
API(Application Programming Interface, 应用程序编程接口)是一个通用概念。
例如我编写了一个类,可以获取计算机的各种硬件信息,它很强大很稳定,如果你的项目也需要这样一个功能,那么你就无需再自己编写代码,将我的类拿来直接用就可以。但是,我的类代码很复杂,让你读完这些代码不太现实,而且我也不希望你看到我的代码(你也没必要也不希望读懂这些晦涩的代码),我要保护我的版权,怎么办呢?
我可以先将我的类编译,并附带一个文档,告诉你我的类怎么使用,有哪些方法和属性,你只需要按照文档的说明来调用就完全没问题,既节省了你阅读代码的时间,也保护了我的版权。例如,获取CPU信息的方法:
getCpuInfo(int cpuType);
这就是一个API。也就是说,该文档中描述的类的使用方法,就叫做API。
我也可以开发一个软件,用来清理计算机中的垃圾文件,我比较有公益心,希望让更多的开发人员使用我的软件,我就会在发布软件的同时附带一个说明文档,告诉你怎样在自己的程序中调用,这也叫做API。
Java API也有一个说明文档,入口地址:http://www.oracle.com/technetwork/java/api
选择对应版本的Java,点击链接进入即可。J2SE 1.7 的API地址为:http://docs.oracle.com/javase/7/docs/api/
这个文档是在线的,官方会随时更新。当然你也可以下载到本地,请大家自己百度怎么下载。
打开J2SE 1.7 的API文档,如下图所示:

图1 API 文档
Java类库中有很多包:
- 以 java.* 开头的是Java的核心包,所有程序都会使用这些包中的类;
- 以 javax.* 开头的是扩展包,x 是 extension 的意思,也就是扩展。虽然 javax.* 是对 java.* 的优化和扩展,但是由于 javax.* 使用的越来越多,很多程序都依赖于 javax.*,所以 javax.* 也是核心的一部分了,也随JDK一起发布。
- 以 org.* 开头的是各个机构或组织发布的包,因为这些组织很有影响力,它们的代码质量很高,所以也将它们开发的部分常用的类随JDK一起发布。
在包的命名方面,为了防止重名,有一个惯例:大家都以自己域名的倒写形式作为开头来为自己开发的包命名,例如百度发布的包会以 com.baidu.* 开头,w3c组织发布的包会以 org.w3c.* 开头,微学苑发布的包会以 net.weixueyuan.* 开头……
组织机构的域名后缀一般为 org,公司的域名后缀一般为 com,可以认为 org.* 开头的包为非盈利组织机构发布的包,它们一般是开源的,可以免费使用在自己的产品中,不用考虑侵权问题,而以 com.* 开头的包往往由盈利性的公司发布,可能会有版权问题,使用时要注意。
java中常用的几个包介绍:
| 包名 | 说明 |
|---|---|
| java.lang | 该包提供了Java编程的基础类,例如 Object、Math、String、StringBuffer、System、Thread等,不使用该包就很难编写Java代码了。 |
| java.util | 该包提供了包含集合框架、遗留的集合类、事件模型、日期和时间实施、国际化和各种实用工具类(字符串标记生成器、随机数生成器和位数组)。 |
| java.io | 该包通过文件系统、数据流和序列化提供系统的输入与输出。 |
| java.net | 该包提供实现网络应用与开发的类。 |
| java.sql | 该包提供了使用Java语言访问并处理存储在数据源(通常是一个关系型数据库)中的数据API。 |
| java.awt | 这两个包提供了GUI设计与开发的类。java.awt包提供了创建界面和绘制图形图像的所有类,而javax.swing包提供了一组“轻量级”的组件,尽量让这些组件在所有平台上的工作方式相同。 |
| javax.swing | |
| java.text | 提供了与自然语言无关的方式来处理文本、日期、数字和消息的类和接口。 |
更多的包和说明请参考API文档。
1.3 Java import以及Java类的搜索路径
如果你希望使用Java包中的类,就必须先使用import语句导入。
import语句与C语言中的 #include 有些类似,语法为:
import package1[.package2…].classname;
package 为包名,classname 为类名。例如:☆☆☆
import java.util.Date; // 导入 java.util 包下的 Date 类 import java.util.Scanner; // 导入 java.util 包下的 Scanner 类 import javax.swing.*; // 导入 javax.swing 包下的所有类,* 表示所有类
注意:
- import 只能导入包所包含的类,而不能导入包。
- 为方便起见,我们一般不导入单独的类,而是导入包下所有的类,例如 import java.util.*;。
Java 编译器默认为所有的 Java 程序导入了 JDK 的 java.lang 包中所有的类(import java.lang.*;),其中定义了一些常用类,如 System、String、Object、Math 等,因此我们可以直接使用这些类而不必显式导入。但是使用其他类必须先导入。
前面讲到的”Hello World“程序使用了System.out.println(); 语句,System 类位于 java.lang 包,虽然我们没有显式导入这个包中的类,但是Java 编译器默认已经为我们导入了,否则程序会执行失败。
Java类的搜索路径
Java程序运行时要导入相应的类,也就是加载 .class 文件的过程。
假设有如下的 import 语句:
import p1.Test;
该语句表明要导入 p1 包中的 Test 类。
安装JDK时,我们已经设置了环境变量 CLASSPATH 来指明类库的路径,它的值为 .;%JAVA_HOME%\lib,而 JAVA_HOME 又为 D:\Program Files\jdk1.7.0_71,所以 CLASSPATH 等价于 .;D:\Program Files\jdk1.7.0_71\lib。
Java 运行环境将依次到下面的路径寻找并载入字节码文件 Test.class:
- .p1\Test.class("."表示当前路径)
- D:\Program Files\jdk1.7.0_71\lib\p1\Test.class
如果在第一个路径下找到了所需的类文件,则停止搜索,否则继续搜索后面的路径,如果在所有的路径下都未能找到所需的类文件,则编译或运行出错。
你可以在CLASSPATH变量中增加搜索路径,例如 .;%JAVA_HOME%\lib;C:\javalib,那么你就可以将类文件放在 C:\javalib 目录下,Java运行环境一样会找到。
二◐ java语法基础
2.1java数据类型以及变量的定义
Java 是一种强类型的语言,声明变量时必须指明数据类型。变量(variable)的值占据一定的内存空间。不同类型的变量占据不同的大小。
Java中共有8种基本数据类型,包括4 种整型、2 种浮点型、1 种字符型、1 种布尔型,请见下表。
| 数据类型 | 说明 | 所占内存 | 举例 | 备注 |
|---|---|---|---|---|
| byte | 字节型 | 1 byte | 3, 127 | |
| short | 短整型 | 2 bytes | 3, 32767 | |
| int | 整型 | 4 bytes | 3, 21474836 | |
| long | 长整型 | 8 bytes | 3L, 92233720368L | long最后要有一个L字母(大小写无所谓)。 |
| float | 单精度浮点型 | 4 bytes | 1.2F, 223.56F | float最后要有一个F字母(大小写无所谓)。 |
| double | 双精度浮点型 | 8 bytes | 1.2, 1.2D, 223.56, 223.56D | double最后最好有一个D字母(大小写无所谓)。 |
| char | 字符型 | 2 bytes | 'a', ‘A’ | 字符型数据只能是一个字符,由单引号包围。 |
| boolean | 布尔型 | 1 bit | true, false |
对于整型数据,通常情况下使用 int 类型。但如果表示投放广岛长崎的原子弹释放出的能量,就需要使用 long 类型了。byte 和 short 类型主要用于特定的应用场合,例如,底层的文件处理或者需要控制占用存储空间量的大数组。
在Java中,整型数据的长度与平台无关,这就解决了软件从一个平台移植到另一个平台时给程序员带来的诸多问题。与此相反,C/C++ 整型数据的长度是与平台相关的,程序员需要针对不同平台选择合适的整型,这就可能导致在64位系统上稳定运行的程序在32位系统上发生整型溢出。
八进制有一个前缀 0,例如 010 对应十进制中的 8;十六进制有一个前缀 0x,例如 0xCAFE;从 Java 7 开始,可以使用前缀 0b 来表示二进制数据,例如 0b1001 对应十进制中的 9。同样从 Java 7 开始,可以使用下划线来分隔数字,类似英文数字写法,例如 1_000_000 表示 1,000,000,也就是一百万。下划线只是为了让代码更加易读,编译器会删除这些下划线。
另外,不像 C/C++,Java 不支持无符号类型(unsigned)。
float 类型有效数字最长为 7 位,有效数字长度包括了整数部分和小数部分。例如:
float x = 223.56F; float y = 100.00f;
注意:每个float类型后面都有一个标志“F”或“f”,有这个标志就代表是float类型。
double 类型有效数字最长为 15 位。与 float 类型一样,double 后面也带有标志“D”或“d”。例如:
double x = 23.45D; double y = 422.22d; double z = 562.234;
注意:不带任何标志的浮点型数据,系统默认是 double 类型。
大多数情况下都是用 double 类型,float 的精度很难满足需求。
不同数据类型应用举例:
public class Demo { public static void main(String[] args){ // 字符型 char webName1 = '微'; char webName2 = '学'; char webName3 = '苑'; System.out.println("网站的名字是:" + webName1 + webName2 + webName3); // 整型 short x=22; // 十进制 int y=022; // 八进制 long z=0x22L; // 十六进制 System.out.println("转化成十进制:x = " + x + ", y = " + y + ", z = " + z); //"+"前后字符串连接// 浮点型 float m = 22.45f; double n = 10; System.out.println("计算乘积:" + m + " * " + n + "=" + m*n); } }
运行结果:
网站的名字是:微学苑
转化成十进制:x = 22, y = 18, z = 34
计算乘积:22.45 * 10.0=224.50000762939453
从运行结果可以看出,即使浮点型数据只有整数没有小数,在控制台上输出时系统也会自动加上小数点,并且小数位全部置为 0。
对布尔型的说明
在C语言中,如果判断条件成立,会返回1,否则返回0,例如:
#include <stdio.h> int main(){ int x = 100>10; int y = 100<10; printf("100>10 = %d\n", x); printf("100<10 = %d\n", y); return 0; }
运行结果:
100>10 = 1
100<10 = 0
但是在Java中不一样,条件成立返回 true,否则返回 false,即布尔类型。例如:
public class Demo { public static void main(String[] args){ // 字符型 boolean a = 100>10; boolean b = 100<10; System.out.println("100>10 = " + a); System.out.println("100<10 = " + b); if(a){ System.out.println("100<10是对的"); }else{ System.out.println("100<10是错的"); } } }
运行结果:
100>10 = true
100<10 = false
100<10是对的
实际上,true 等同于1,false 等同于0,只不过换了个名称,并单独地成为一种数据类型。
2.2 Java数据类型转换(自动转换和强制转换)
数据类型的转换,分为自动转换和强制转换。自动转换是程序在执行过程中“悄然”进行的转换,不需要用户提前声明,一般是从位数低的类型向位数高的类型转换;强制类型转换则必须在代码中声明,转换顺序不受限制。
自动数据类型转换
自动转换按从低到高的顺序转换。不同类型数据间的优先关系如下:
低--------------------------------------------->高
byte,short,char-> int -> long -> float -> double
运算中,不同类型的数据先转化为同一类型,然后进行运算,转换规则如下:
| 操作数1类型 | 操作数2类型 | 转换后的类型 |
|---|---|---|
| byte、short、char | int | int |
| byte、short、char、int | long | long |
| byte、short、char、int、long | float | float |
| byte、short、char、int、long、float | double | double |
强制数据类型转换
强制转换的格式是在需要转型的数据前加上“( )”,然后在括号内加入需要转化的数据类型。有的数据经过转型运算后,精度会丢失,而有的会更加精确,下面的例子可以说明这个问题。
public class Demo { public static void main(String[] args){ int x; double y; x = (int)34.56 + (int)11.2; // 丢失精度 y = (double)x + (double)10 + 1; // 提高精度 System.out.println("x=" + x); System.out.println("y=" + y); } }
运行结果:
x=45
y=56.0
仔细分析上面程序段:由于在 34.56 前有一个 int 的强制类型转化,所以 34.56 就变成了 34。同样 11.2 就变成了 11 了,所以 x 的结果就是 45。在 x 前有一个 double 类型的强制转换,所以 x 的值变为 45.0,而 10 的前面也被强制成 double 类型,所以也变成 10.0,所以最后 y 的值变为 56。
2.3 Java数组的定义和使用
如果希望保存一组有相同类型的数据,可以使用数组。
数组的定义和内存分配
Java 中定义数组的语法有两种:
type arrayName[];
type[] arrayName;
type 为Java中的任意数据类型,包括基本类型和组合类型,arrayName为数组名,必须是一个合法的标识符,[ ] 指明该变量是一个数组类型变量。例如:
int demoArray[]; int[] demoArray;
这两种形式没有区别,使用效果完全一样,读者可根据自己的编程习惯选择。
与C、C++不同,Java在定义数组时并不为数组元素分配内存,因此[ ]中无需指定数组元素的个数,即数组长度。而且对于如上定义的一个数组是不能访问它的任何元素的,我们必须要为它分配内存空间,这时要用到运算符new,其格式如下:
arrayName=new type[arraySize];
其中,arraySize 为数组的长度,type 为数组的类型。如:
demoArray=new int[3];
为一个整型数组分配3个int 型整数所占据的内存空间。
通常,你可以在定义的同时分配空间,语法为:
type arrayName[] = new type[arraySize];
例如:
int demoArray[] = new int[3];
数组的初始化
你可以在声明数组的同时进行初始化(静态初始化),也可以在声明以后进行初始化(动态初始化)。例如:
// 静态初始化 // 静态初始化的同时就为数组元素分配空间并赋值 int intArray[] = {1,2,3,4}; String stringArray[] = {"微学苑", "http://www.weixueyuan.net", "一切编程语言都是纸老虎"}; // 动态初始化 float floatArray[] = new float[3]; floatArray[0] = 1.0f; floatArray[1] = 132.63f; floatArray[2] = 100F;
数组引用
可以通过下标来引用数组:
arrayName[index];
与C、C++不同,Java对数组元素要进行越界检查以保证安全性。
每个数组都有一个length属性来指明它的长度,例如 intArray.length 指明数组 intArray 的长度。
【示例】写一段代码,要求输入任意5个整数,输出它们的和。
import java.util.*; public class Demo { public static void main(String[] args){ int intArray[] = new int[5]; long total = 0; int len = intArray.length; // 给数组元素赋值 System.out.print("请输入" + len + "个整数,以空格为分隔:"); Scanner sc = new Scanner(System.in); for(int i=0; i<len; i++){ intArray[i] = sc.nextInt(); } // 计算数组元素的和 for(int i=0; i<len; i++){ total += intArray[i]; } System.out.println("所有数组元素的和为:" + total); } }
运行结果:
请输入5个整数,以空格为分隔:10 20 15 25 50
所有数组元素的和为:120
数组的遍历
实际开发中,经常需要遍历数组以获取数组中的每一个元素。最容易想到的方法是for循环,例如:
int arrayDemo[] = {1, 2, 4, 7, 9, 192, 100}; for(int i=0,len=arrayDemo.length; i<len; i++){ System.out.println(arrayDemo[i] + ", "); }
输出结果:
1, 2, 4, 7, 9, 192, 100,
不过,Java提供了”增强版“的for循环,专门用来遍历数组,语法为:
for( arrayType varName: arrayName ){ // Some Code }
arrayType 为数组类型(也是数组元素的类型);varName 是用来保存当前元素的变量,每次循环它的值都会改变;arrayName 为数组名称。
每循环一次,就会获取数组中下一个元素的值,保存到 varName 变量,直到数组结束。即,第一次循环 varName 的值为第0个元素,第二次循环为第1个元素......例如:
int arrayDemo[] = {1, 2, 4, 7, 9, 192, 100}; for(int x: arrayDemo){ System.out.println(x + ", "); }
输出结果与上面相同。
这种增强版的for循环也被称为”foreach循环“,它是普通for循环语句的特殊简化版。所有的foreach循环都可以被改写成for循环。
但是,如果你希望使用数组的索引,那么增强版的 for 循环无法做到。
二维数组
二维数组的声明、初始化和引用与一维数组相似:
int intArray[ ][ ] = { {1,2}, {2,3}, {4,5} }; int a[ ][ ] = new int[2][3]; //与c c++不同之处是定义的时候不占内存,需要重新分配空间 a[0][0] = 12; a[0][1] = 34; // ...... a[1][2] = 93;
Java语言中,由于把二维数组看作是数组的数组,数组空间不是连续分配的,所以不要求二维数组每一维的大小相同。例如:
int intArray[ ][ ] = { {1,2}, {2,3}, {3,4,5} }; int a[ ][ ] = new int[2][ ]; a[0] = new int[3]; a[1] = new int[5];
【示例】通过二维数组计算两个矩阵的乘积。
public class Demo { public static void main(String[] args){ // 第一个矩阵(动态初始化一个二维数组) int a[][] = new int[2][3]; // 第二个矩阵(静态初始化一个二维数组) int b[][] = { {1,5,2,8}, {5,9,10,-3}, {2,7,-5,-18} }; // 结果矩阵 int c[][] = new int[2][4]; // 初始化第一个矩阵 for(int i=0; i<2; i++) for(int j=0; j<3 ;j++) a[i][j] = (i+1) * (j+2); // 计算矩阵乘积 for (int i=0; i<2; i++){ for (int j=0; j<4; j++){ c[i][j]=0; for(int k=0; k<3; k++) c[i][j] += a[i][k] * b[k][j]; } } // 输出结算结果 for(int i=0; i<2; i++){ for (int j=0; j<4; j++) System.out.printf("%-5d", c[i][j]); System.out.println(); } } }
运行结果:
25 65 14 -65
50 130 28 -130
几点说明:
- 上面讲的是静态数组。静态数组一旦被声明,它的容量就固定了,不容改变。所以在声明数组时,一定要考虑数组的最大容量,防止容量不够的现象。
- 如果想在运行程序时改变容量,就需要用到数组列表(ArrayList,也称动态数组)或向量(Vector)。
- 正是由于静态数组容量固定的缺点,实际开发中使用频率不高,被 ArrayList 或 Vector 代替,因为实际开发中经常需要向数组中添加或删除元素,而它的容量不好预估。
2.4 Java StringBuffer与StringBuider
String 的值是不可变的,每次对String的操作都会生成新的String对象,不仅效率低,而且耗费大量内存空间。
StringBuffer类和String类一样,也用来表示字符串,但是StringBuffer的内部实现方式和String不同,在进行字符串处理时,不生成新的对象,在内存使用上要优于String。
StringBuffer 默认分配16字节长度的缓冲区,当字符串超过该大小时,会自动增加缓冲区长度,而不是生成新的对象。
StringBuffer不像String,只能通过 new 来创建对象,不支持简写方式,例如:
StringBuffer str1 = new StringBuffer(); // 分配16个字节长度的缓冲区 StringBuffer str2 = =new StringBuffer(512); // 分配512个字节长度的缓冲区 // 在缓冲区中存放了字符串,并在后面预留了16个字节长度的空缓冲区 StringBuffer str3 = new StringBuffer("www.weixueyuan.net");
StringBuffer类的主要方法
StringBuffer类中的方法主要偏重于对于字符串的操作,例如追加、插入和删除等,这个也是StringBuffer类和String类的主要区别。实际开发中,如果需要对一个字符串进行频繁的修改,建议使用 StringBuffer。
1) append() 方法
append() 方法用于向当前字符串的末尾追加内容,类似于字符串的连接。调用该方法以后,StringBuffer对象的内容也发生改变,例如:
StringBuffer str = new StringBuffer(“biancheng100”); str.append(true);
则对象str的值将变成”biancheng100true”。注意是str指向的内容变了,不是str的指向变了。
字符串的”+“操作实际上也是先创建一个StringBuffer对象,然后调用append()方法将字符串片段拼接起来,最后调用toString()方法转换为字符串。
这样看来,String的连接操作就比StringBuffer多出了一些附加操作,效率上必然会打折扣。
但是,对于长度较小的字符串,”+“操作更加直观,更具可读性,有些时候可以稍微牺牲一下效率。
2) deleteCharAt()
deleteCharAt() 方法用来删除指定位置的字符,并将剩余的字符形成新的字符串。例如:
StringBuffer str = new StringBuffer("abcdef"); str. deleteCharAt(3);
该代码将会删除索引值为3的字符,即”d“字符。
你也可以通过delete()方法一次性删除多个字符,例如:
StringBuffer str = new StringBuffer("abcdef"); str.delete(1, 4);
该代码会删除索引值为1~4之间的字符,包括索引值1,但不包括4。
3) insert() 方法
insert() 用来在指定位置插入字符串,可以认为是append()的升级版。例如:
StringBuffer str = new StringBuffer("abcdef"); str.insert(3, "xyz");
最后str所指向的字符串为 abcdxyzef。
4) setCharAt() 方法
setCharAt() 方法用来修改指定位置的字符。例如:
StringBuffer str = new StringBuffer("abcdef"); str.setCharAt(3, 'z');
该代码将把索引值为3的字符修改为 z,最后str所指向的字符串为 abczef。
以上仅仅是部分常用方法的简单说明,更多方法和解释请查阅API文档。
String和StringBuffer的效率对比
为了更加明显地看出它们的执行效率,下面的代码,将26个英文字母加了10000次。
public class Demo { public static void main(String[] args){ String fragment = "abcdefghijklmnopqrstuvwxyz"; int times = 10000; // 通过String对象 long timeStart1 = System.currentTimeMillis(); String str1 = ""; for (int i=0; i<times; i++) { str1 += fragment; } long timeEnd1 = System.currentTimeMillis(); System.out.println("String: " + (timeEnd1 - timeStart1) + "ms"); // 通过StringBuffer long timeStart2 = System.currentTimeMillis(); StringBuffer str2 = new StringBuffer(); for (int i=0; i<times; i++) { str2.append(fragment); } long timeEnd2 = System.currentTimeMillis(); System.out.println("StringBuffer: " + (timeEnd2 - timeStart2) + "ms"); } }
运行结果:
String: 5287ms
StringBuffer: 3ms
结论很明显,StringBuffer的执行效率比String快上千倍,这个差异随着叠加次数的增加越来越明显,当叠加次数达到30000次的时候,运行结果为:
String: 35923ms
StringBuffer: 8ms
所以,强烈建议在涉及大量字符串操作时使用StringBuffer。
StringBuilder类
StringBuilder类和StringBuffer类功能基本相似,方法也差不多,主要区别在于StringBuffer类的方法是多线程安全的,而StringBuilder不是线程安全的,相比而言,StringBuilder类会略微快一点。
StringBuffer、StringBuilder、String中都实现了CharSequence接口。
CharSequence是一个定义字符串操作的接口,它只包括length()、charAt(int index)、subSequence(int start, int end) 这几个API。
StringBuffer、StringBuilder、String对CharSequence接口的实现过程不一样,如下图所示:
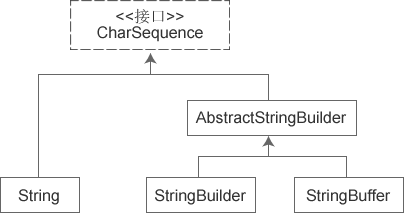
图1 对CharSequence接口的实现
可见,String直接实现了CharSequence接口;StringBuilder 和 StringBuffer都是可变的字符序列,它们都继承于AbstractStringBuilder,实现了CharSequence接口。
总结
线程安全:
- StringBuffer:线程安全
- StringBuilder:线程不安全
速度:
一般情况下,速度从快到慢为 StringBuilder > StringBuffer > String,当然这是相对的,不是绝对的。
使用环境:
- 操作少量的数据使用 String;
- 单线程操作大量数据使用 StringBuilder;
- 多线程操作大量数据使用 StringBuffer。
三◐ java类和对象
3.1 Java类的定义及其实例化
类必须先定义才能使用。类是创建对象的模板,创建对象也叫类的实例化。所谓的 实例化 说白了就是 创建对象
实例化之后的对象 叫做实例
下面通过一个简单的例子来理解Java中类的定义:
public class Dog{ String name; int age; void bark(){ // 汪汪叫 System.out.println("汪汪,不要过来"); } void hungry(){ // 饥饿 System.out.println("主人,我饿了"); } }
对示例的说明:
- public 是类的修饰符,表明该类是公共类,可以被其他类访问。修饰符将在下节讲解。
- class 是定义类的关键字。
- Dog 是类名称。
- name、age 是类的成员变量,也叫属性;bark()、hungry() 是类中的函数,也叫方法。
一个类可以包含以下类型变量:
- 局部变量:在方法或者语句块中定义的变量被称为局部变量。变量声明和初始化都是在方法中,方法结束后,变量就会自动销毁。
- 成员变量:成员变量是定义在类中、方法体之外的变量。这种变量在创建对象的时候实例化(分配内存)。成员变量可以被类中的方法和特定类的语句访问。
- 类变量:类变量也声明在类中,方法体之外,但必须声明为static类型。static 也是修饰符的一种,将在下节讲解。
构造方法
在类实例化的过程中自动执行的方法叫做构造方法,它不需要你手动调用。构造方法可以在类实例化的过程中做一些初始化的工作。
构造方法的名称必须与类的名称相同,并且没有返回值。
每个类都有构造方法。如果没有显式地为类定义构造方法,Java编译器将会为该类提供一个默认的构造方法。
下面是一个构造方法示例:
public class Dog{ String name; int age; // 构造方法,没有返回值 Dog(String name1, int age1){ name = name1; age = age1; System.out.println("感谢主人领养了我"); } // 普通方法,必须有返回值 void bark(){ System.out.println("汪汪,不要过来"); } void hungry(){ System.out.println("主人,我饿了"); } public static void main(String arg[]){ // 创建对象时传递的参数要与构造方法参数列表对应 Dog myDog = new Dog("花花", 3); } }
运行结果:
感谢主人领养了我
说明:
- 构造方法不能被显示调用。
- 构造方法不能有返回值,因为没有变量来接收返回值。
创建对象
对象是类的一个实例,创建对象的过程也叫类的实例化。对象是以类为模板来创建的。
在Java中,使用new关键字来创建对象,一般有以下三个步骤:
- 声明:声明一个对象,包括对象名称和对象类型。
- 实例化:使用关键字new来创建一个对象。
- 初始化:使用new创建对象时,会调用构造方法初始化对象。
例如:
Dog myDog; // 声明一个对象 myDog = new Dog("花花", 3); // 实例化 声明并没有分配空间,只有实例化后,才有了自己的空间
也可以在声明的同时进行初始化:
Dog myDog = new Dog("花花", 3);
访问成员变量和方法
通过已创建的对象来访问成员变量和成员方法,例如:
// 实例化 Dog myDog = new Dog("花花", 3); // 通过点号访问成员变量 myDog.name; // 通过点号访问成员方法 myDog.bark();
下面的例子演示了如何访问成员变量和方法:
public class Dog{ String name; int age; Dog(String name1, int age1){ name = name1; age = age1; System.out.println("感谢主人领养了我"); } void bark(){ System.out.println("汪汪,不要过来"); } void hungry(){ System.out.println("主人,我饿了"); } public static void main(String arg[]){ Dog myDog = new Dog("花花", 3); // 访问成员变量 String name = myDog.name; int age = myDog.age; System.out.println("我是一只小狗,我名字叫" + name + ",我" + age + "岁了"); // 访问方法 myDog.bark(); myDog.hungry(); } }
运行结果:
感谢主人领养了我
我是一只小狗,我名字叫花花,我3岁了
汪汪,不要过来
主人,我饿了
3.2 Java访问修饰符(访问控制符)
Java 通过修饰符来控制类、属性和方法的访问权限和其他功能,通常放在语句的最前端。例如:
public class className { // body of class } private boolean myFlag; static final double weeks = 9.5; protected static final int BOXWIDTH = 42; public static void main(String[] arguments) { // body of method }
Java 的修饰符很多,分为访问修饰符和非访问修饰符。本节仅介绍访问修饰符,非访问修饰符会在后续介绍。
访问修饰符也叫访问控制符,是指能够控制类、成员变量、方法的使用权限的关键字。
在面向对象编程中,访问控制符是一个很重要的概念,可以使用它来保护对类、变量、方法和构造方法的访问。
Java支持四种不同的访问权限:
| 修饰符 | 说明 |
|---|---|
| public | 共有的,对所有类可见。 |
| protected | 受保护的,对同一包内的类和所有子类可见。 |
| private | 私有的,在同一类内可见。 |
| 默认的 | 在同一包内可见。默认不使用任何修饰符。 |
public:公有的
被声明为public的类、方法、构造方法和接口能够被任何其他类访问。
如果几个相互访问的public类分布在不用的包中,则需要导入相应public类所在的包。由于类的继承性,类所有的公有方法和变量都能被其子类继承。
下面的方法使用了公有访问控制:
public static void main(String[] arguments) { // body of method }
Java程序的main() 方法必须设置成公有的,否则,Java解释器将不能运行该类。
protected:受保护的
被声明为protected的变量、方法和构造方法能被同一个包中的任何其他类访问,也能够被不同包中的子类访问。
protected访问修饰符不能修饰类和接口,方法和成员变量能够声明为protected,但是接口的成员变量和成员方法不能声明为protected。
子类能访问protected修饰符声明的方法和变量,这样就能保护不相关的类使用这些方法和变量。
下面的父类使用了protected访问修饰符,子类重载了父类的bark()方法。
public class Dog{ protected void bark() { System.out.println("汪汪,不要过来"); } } class Teddy extends Dog{ // 泰迪 void bark() { System.out.println("汪汪,我好怕,不要跟着我"); } }
如果把bark()方法声明为private,那么除了Dog之外的类将不能访问该方法。如果把bark()声明为public,那么所有的类都能够访问该方法。如果我们只想让该方法对其所在类的子类可见,则将该方法声明为protected。
private:私有的
私有访问修饰符是最严格的访问级别,所以被声明为private的方法、变量和构造方法只能被所属类访问,并且类和接口不能声明为private。
声明为私有访问类型的变量只能通过类中公共的Getter/Setter方法被外部类访问。
private访问修饰符的使用主要用来隐藏类的实现细节和保护类的数据。
下面的类使用了私有访问修饰符:
public class Dog{ private String name; private int age; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } }
例子中,Dog类中的name、age变量为私有变量,所以其他类不能直接得到和设置该变量的值。为了使其他类能够操作该变量,定义了两对public方法,getName()/setName() 和 getAge()/setAge(),它们用来获取和设置私有变量的值。
this 是Java中的一个关键字,本章会讲到,你可以点击 Java this关键字详解 预览。
在类中定义访问私有变量的方法,习惯上是这样命名的:在变量名称前面加“get”或“set”,并将变量的首字母大写。例如,获取私有变量 name 的方法为 getName(),设置 name 的方法为 setName()。这些方法经常使用,也有了特定的称呼,称为 Getter 和 Setter 方法。
默认的:不使用任何关键字
不使用任何修饰符声明的属性和方法,对同一个包内的类是可见的。接口里的变量都隐式声明为public static final,而接口里的方法默认情况下访问权限为public。
如下例所示,类、变量和方法的定义没有使用任何修饰符:
class Dog{ String name; int age; void bark(){ // 汪汪叫 System.out.println("汪汪,不要过来"); } void hungry(){ // 饥饿 System.out.println("主人,我饿了"); } }
访问控制和继承
请注意以下方法继承(不了解继承概念的读者可以跳过这里,或者点击 Java继承和多态 预览)的规则:
-
父类中声明为public的方法在子类中也必须为public。
-
父类中声明为protected的方法在子类中要么声明为protected,要么声明为public。不能声明为private。
-
父类中默认修饰符声明的方法,能够在子类中声明为private。
-
父类中声明为private的方法,不能够被继承。
如何使用访问控制符
访问控制符可以让我们很方便的控制代码的权限:
- 当需要让自己编写的类被所有的其他类访问时,就可以将类的访问控制符声明为 public。
- 当需要让自己的类只能被自己的包中的类访问时,就可以省略访问控制符。
- 当需要控制一个类中的成员数据时,可以将这个类中的成员数据访问控制符设置为 public、protected,或者省略。
3.3 Java变量的作用域
在Java中,变量的作用域分为四个级别:类级、对象实例级、方法级、块级。
类级变量又称全局级变量或静态变量,需要使用static关键字修饰,你可以与 C/C++ 中的 static 变量对比学习。类级变量在类定义后就已经存在,占用内存空间,可以通过类名来访问,不需要实例化。
对象实例级变量就是成员变量,实例化后才会分配内存空间,才能访问。
方法级变量就是在方法内部定义的变量,就是局部变量。
块级变量就是定义在一个块内部的变量,变量的生存周期就是这个块,出了这个块就消失了,比如 if、for 语句的块。块是指由大括号包围的代码,例如:
{ int age = 3; String name = "www.weixueyuan.net"; // 正确,在块内部可以访问 age 和 name 变量 System.out.println( name + "已经" + age + "岁了"); } // 错误,在块外部无法访问 age 和 name 变量 System.out.println( name + "已经" + age + "岁了");
说明:
- 方法内部除了能访问方法级的变量,还可以访问类级和实例级的变量。
- 块内部能够访问类级、实例级变量,如果块被包含在方法内部,它还可以访问方法级的变量。
- 方法级和块级的变量必须被显示地初始化,否则不能访问。
演示代码:
public class Demo{ public static String name = "微学苑"; // 类级变量 public int i; // 对象实例级变量 // 属性块,在类初始化属性时候运行 { int j = 2;// 块级变量 } public void test1() { int j = 3; // 方法级变量 if(j == 3) { int k = 5; // 块级变量 } // 这里不能访问块级变量,块级变量只能在块内部访问 System.out.println("name=" + name + ", i=" + i + ", j=" + j); } public static void main(String[] args) { // 不创建对象,直接通过类名访问类级变量 System.out.println(Demo.name); // 创建对象并访问它的方法 Demo t = new Demo(); t.test1(); } }
运行结果:
微学苑
name=微学苑, i=0, j=3
(this关键字和C++用法一样)
(java方法重载和C++用法一样)
3.4 Java类的基本运行顺序
我们以下面的类来说明一个基本的 Java 类的运行顺序:
public class Demo{ private String name; private int age; public Demo(){ name = "微学苑"; age = 3; } public static void main(String[] args){ Demo obj = new Demo(); System.out.println(obj.name + "的年龄是" + obj.age); } }
基本运行顺序是:
- 先运行到第 9 行,这是程序的入口。
- 然后运行到第 10 行,这里要 new 一个Demo,就要调用 Demo 的构造方法。
- 就运行到第 5 行,注意:可能很多人觉得接下来就应该运行第 6 行了,错!初始化一个类,必须先初始化它的属性。
- 因此运行到第 2 行,然后是第 3 行。
- 属性初始化完过后,才回到构造方法,执行里面的代码,也就是第 6 行、第 7 行。
- 然后是第8行,表示 new 一个Demo实例完成。
- 然后回到 main 方法中执行第 11 行。
- 然后是第 12 行,main方法执行完毕。
作为程序员,应该清楚程序的基本运行过程,否则糊里糊涂的,不利于编写代码,也不利于技术上的发展。
3.5 Java包装类、拆箱和装箱详解 (类型转换)
虽然 Java 语言是典型的面向对象编程语言,但其中的八种基本数据类型并不支持面向对象编程,基本类型的数据不具备“对象”的特性——不携带属性、没有方法可调用。 沿用它们只是为了迎合人类根深蒂固的习惯,并的确能简单、有效地进行常规数据处理。
这种借助于非面向对象技术的做法有时也会带来不便,比如引用类型数据均继承了 Object 类的特性,要转换为 String 类型(经常有这种需要)时只要简单调用 Object 类中定义的toString()即可,而基本数据类型转换为 String 类型则要麻烦得多。为解决此类问题 ,Java为每种基本数据类型分别设计了对应的类,称之为包装类(Wrapper Classes),也有教材称为外覆类或数据类型类。
| 基本数据类型 | 对应的包装类 |
|---|---|
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| char | Character |
| float | Float |
| double | Double |
| boolean | Boolean |
以上是基本类型;
下面是C++和java中的一些概念
C++ java
类 类
对象 对象 或 实例 (借用类占对象后的叫类)
类中函数 方法
包 (放功能相似的类的一个文件夹)
每个包装类的对象可以封装一个相应的基本类型的数据,并提供了其它一些有用的方法。包装类对象一经创建,其内容(所封装的基本类型数据值)不可改变。
基本类型和对应的包装类可以相互装换:
装箱:int→Integer
拆箱:Integer→int
- 由基本类型向对应的包装类转换称为装箱,例如把 int 包装成 Integer 类的对象;
- 包装类向对应的基本类型转换称为拆箱,例如把 Integer 类的对象重新简化为 int。
包装类的应用
八个包装类的使用比较相似,下面是常见的应用场景。
1) 实现 int 和 Integer 的相互转换
可以通过 Integer 类的构造方法将 int 装箱,通过 Integer 类的 intValue 方法将 Integer 拆箱。例如:
public class Demo { public static void main(String[] args) { int m = 500; Integer obj = new Integer(m); // 手动装箱 int n = obj.intValue(); // 手动拆箱 System.out.println("n = " + n); Integer obj1 = new Integer(500); //装箱 System.out.println("obj 等价于 obj1?" + obj.equals(obj1));//拆箱 } }
运行结果:
n = 500
obj 等价于 obj1?true
2) 将字符串转换为整数
Integer 类有一个静态的 paseInt() 方法,可以将字符串转换为整数,语法为:
parseInt(String s, int radix);
s 为要转换的字符串,radix 为进制,可选,默认为十进制。
下面的代码将会告诉你什么样的字符串可以转换为整数:
public class Demo { public static void main(String[] args) { String str[] = {"123", "123abc", "abc123", "abcxyz"}; for(String str1 : str){ //怎么理解 try{ int m = Integer.parseInt(str1, 10); System.out.println(str1 + " 可以转换为整数 " + m); }catch(Exception e){ System.out.println(str1 + " 无法转换为整数"); } } } }
运行结果:
123 可以转换为整数 123
123abc 无法转换为整数
abc123 无法转换为整数
abcxyz 无法转换为整数
3) 将整数转换为字符串
Integer 类有一个静态的 toString() 方法,可以将整数转换为字符串。例如:
public class Demo { public static void main(String[] args) { int m = 500; String s = Integer.toString(m); System.out.println("s = " + s); } }
运行结果:
s = 500
自动拆箱和装箱
上面的例子都需要手动实例化一个包装类,称为手动拆箱装箱。Java 1.5(5.0) 之前必须手动拆箱装箱。
Java 1.5 之后可以自动拆箱装箱,也就是在进行基本数据类型和对应的包装类转换时,系统将自动进行,这将大大方便程序员的代码书写。例如:
public class Demo { public static void main(String[] args) { int m = 500; Integer obj = m; // 自动装箱 int n = obj; // 自动拆箱 System.out.println("n = " + n); Integer obj1 = 500; System.out.println("obj 等价于 obj1?" + obj.equals(obj1)); //判断相等运算 } }
运行结果:
n = 500
obj 等价于 obj1?true
自动拆箱装箱是常用的一个功能,读者需要重点掌握。
3.6 再谈Java包
在Java中,为了组织代码的方便,可以将功能相似的类放到一个文件夹内,这个文件夹,就叫做包。
包不但可以包含类,还可以包含接口和其他的包。
目录以"\"来表示层级关系,例如 E:\Java\workspace\Demo\bin\p1\p2\Test.java。
包以"."来表示层级关系,例如 p1.p2.Test 表示的目录为 \p1\p2\Test.class。
如何实现包
通过 package 关键字可以声明一个包,例如:
package p1.p2;
必须将 package 语句放在所有语句的前面,例如:
package p1.p2; public class Test { public Test(){ System.out.println("我是Test类的构造方法"); } }
表明 Test 类位于 p1.p2 包中。
包的调用
在Java中,调用其他包中的类共有两种方式。
方法1) 在每个类名前面加上完整的包名
程序举例:
public class Demo { public static void main(String[] args) { java.util.Date today=new java.util.Date(); System.out.println(today); } }
运行结果:
Wed Dec 03 11:20:13 CST 2014
方法2) 通过 import 语句引入包中的类
程序举例:
import java.util.Date; // 也可以引入 java.util 包中的所有类 // import java.util.*; public class Demo { public static void main(String[] args) { Date today=new Date(); System.out.println(today); } }
运行结果与上面相同。
实际编程中,没有必要把要引入的类写的那么详细,可以直接引入特定包中所有的类,例如 import java.util.*;。
类的路径
Java 在导入类时,必须要知道类的绝对路径。
首先在 E:\Java\workspace\Demo\src\p0\ 目录(E:\Java\workspace\Demo\src\ 是项目源文件的根目录)下创建 Demo.java,输入如下代码:
package p0; import p1.p2.Test; public class Demo{ public static void main(String[] args){ Test obj = new Test(); } }
再在 E:\Java\workspace\Demo\src\p1\p2 目录下创建 Test.java,输入如下代码:
package p1.p2; public class Test { public Test(){ System.out.println("我是Test类的构造方法"); } }
假设我们将 classpath 环境变量设置为 .;D:\Program Files\jdk1.7.0_71\lib,源文件 Demo.java 开头有 import p1.p2.Test; 语句,那么编译器会先检查 E:\Java\workspace\Demo\src\p0\p1\p2\ 目录下是否存在 Test.java 或 Test.class 文件,如果不存在,会继续检索 D:\Program Files\jdk1.7.0_71\lib\p1\p2\ 目录,两个目录下都不存在就会报错。显然,Test.java 位于 E:\Java\workspace\Demo\src\p1\p2\ 目录,编译器找不到,会报错,怎么办呢?
可以通过 javac 命令的 classpath 选项来指定类路径。
打开CMD,进入 Demo.java 文件所在目录,执行 javac 命令,并将 classpath 设置为 E:\Java\workspace\Demo\src,如下图所示:
运行Java程序时,也需要知道类的绝对路径,除了 classpath 环境变量指定的路径,也可以通过 java 命令的 classpath 选项来增加路径,如下图所示: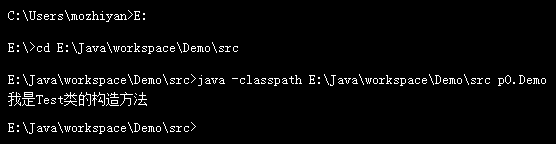
注意 java 命令与 javac 命令的区别,执行 javac 命令需要进入当前目录,而执行 java 命令需要进入当前目录的上级目录,并且类名前面要带上包名。
可以这样来理解,javac是一个平台命令,它对具体的平台文件进行操作,要指明被编译的文件路径。而java是一个虚拟机命令,它对类操作,即对类的描述要用 点 分的描述形式,并且不能加扩展名,还要注意类名的大小写。
这些命令比较繁杂,实际开发都需要借助 Eclipse,在Eclipse下管理包、编译运行程序都非常方便。Eclipse 实际上也是执行这些命令。
包的访问权限
被声明为 public 的类、方法或成员变量,可以被任何包下的任何类使用,而声明为 private 的类、方法或成员变量,只能被本类使用。
没有任何修饰符的类、方法和成员变量,只能被本包中的所有类访问,在包以外任何类都无法访问它。
3.7 Java源文件的声明规则
当在一个源文件中定义多个类,并且还有import语句和package语句时,要特别注意这些规则:
- 一个源文件中只能有一个public类。
- 一个源文件可以有多个非public类。
- 源文件的名称应该和public类的类名保持一致。例如:源文件中public类的类名是Employee,那么源文件应该命名为Employee.java。
- 如果一个类定义在某个包中,那么package语句应该在源文件的首行。
- 如果源文件包含import语句,那么应该放在package语句和类定义之间。如果没有package语句,那么import语句应该在源文件中最前面。
- import语句和package语句对源文件中定义的所有类都有效。在同一源文件中,不能给不同的类不同的包声明。
- 类有若干种访问级别,并且类也分不同的类型:抽象类和final类等。这些将在后续章节介绍。
- 除了上面提到的几种类型,Java还有一些特殊的类,如内部类、匿名类。
一个简单的例子
在该例子中,我们创建两个类 Employee 和 EmployeeTest,分别放在包 p1 和 p2 中。
Employee类有四个成员变量,分别是 name、age、designation和salary。该类显式声明了一个构造方法,该方法只有一个参数。
在Eclipse中,创建一个包,命名为 p1,在该包中创建一个类,命名为 Employee,将下面的代码复制到源文件中:
package p1; public class Employee{ String name; int age; String designation; double salary; // Employee 类的构造方法 public Employee(String name){ this.name = name; } // 设置age的值 public void empAge(int empAge){ age = empAge; } // 设置designation的值 public void empDesignation(String empDesig){ designation = empDesig; } // 设置salary的值 public void empSalary(double empSalary){ salary = empSalary; } // 输出信息 public void printEmployee(){ System.out.println("Name:"+ name ); System.out.println("Age:" + age ); System.out.println("Designation:" + designation ); System.out.println("Salary:" + salary); } }
程序都是从main方法开始执行。为了能运行这个程序,必须包含main方法并且创建一个对象。
下面给出EmployeeTest类,该类创建两个Employee对象,并调用方法设置变量的值。
在Eclipse中再创建一个包,命名为 p2,在该包中创建一个类,命名为 EmployeeTest,将下面的代码复制到源文件中:
package p2; import p1.*; //这些是在EmployeeTest之外 public class EmployeeTest{ public static void main(String args[]){ // 创建两个对象 Employee empOne = new Employee("James Smith"); Employee empTwo = new Employee("Mary Anne"); // 调用这两个对象的成员方法 empOne.empAge(26); empOne.empDesignation("Senior Software Engineer"); empOne.empSalary(1000); empOne.printEmployee(); empTwo.empAge(21); empTwo.empDesignation("Software Engineer"); empTwo.empSalary(500); empTwo.printEmployee(); } }
编译并运行 EmployeeTest 类,可以看到如下的输出结果:
Name:James Smith
Age:26
Designation:Senior Software Engineer
Salary:1000.0
Name:Mary Anne
Age:21
Designation:Software Engineer
Salary:500.0
四◐ java继承和多态
4.1 java中继承的概念与实现
继承是类与类之间的关系,是一个很简单很直观的概念,与现实世界中的继承(例如儿子继承父亲财产)类似。
继承可以理解为一个类从另一个类获取方法和属性的过程。如果类B继承于类A,那么B就拥有A的方法和属性。
继承使用 extends 关键字。
例如我们已经定义了一个类 People:
class People{ String name; int age; int height; void say(){ System.out.println("我的名字是 " + name + ",年龄是 " + age + ",身高是 " + height); } }
如果现在需要定义一个类 Teacher,它也有 name、age、height 属性和 say() 方法,另外还需要增加 school、seniority、subject 属性和 lecturing() 方法,怎么办呢?我们要重新定义一个类吗?
完全没必要,可以先继承 People 类的成员,再增加自己的成员即可,例如:
class Teacher extends People{ //在C++中 class teacher:public student String school; // 所在学校 String subject; // 学科 int seniority; // 教龄 // 覆盖 People 类中的 say() 方法 void say(){ System.out.println("我叫" + name + ",在" + school + "教" + subject + ",有" + seniority + "年教龄"); } void lecturing(){ System.out.println("我已经" + age + "岁了,依然站在讲台上讲课"); } }
对程序的说明
- name 和 age 变量虽然没有在 Teacher 中定义,但是已在 People 中定义,可以直接拿来用。
- Teacher 是 People 的子类,People 是Teacher 类的父类。
- 子类可以覆盖父类的方法。
- 子类可以继承父类除private以为的所有的成员。
- 构造方法不能被继承。
继承是在维护和可靠性方面的一个伟大进步。如果在 People 类中进行修改,那么 Teacher 类就会自动修改,而不需要程序员做任何工作,除了对它进行编译。
单继承性:Java 允许一个类仅能继承一个其它类,即一个类只能有一个父类,这个限制被称做单继承性。后面将会学到接口(interface)的概念,接口允许多继承。(这一点是与C++不同的了,在C++中允许多继承,但没有接口interface这一说)
最后对上面的代码进行整理:
public class Demo { public static void main(String[] args) { Teacher t = new Teacher(); t.name = "小布"; t.age = 70; t.school = "清华大学"; t.subject = "Java"; t.seniority = 12; t.say(); t.lecturing(); } } class People{ String name; int age; int height; void say(){ System.out.println("我的名字是 " + name + ",年龄是 " + age + ",身高是 " + height); } } class Teacher extends People{ String school; // 所在学校 String subject; // 学科 int seniority; // 教龄 // 覆盖 People 类中的 say() 方法 void say(){ System.out.println("我叫" + name + ",在" + school + "教" + subject + ",有" + seniority + "年教龄"); } void lecturing(){ System.out.println("我已经" + age + "岁了,依然站在讲台上讲课"); } }
运行结果:
我叫小布,在清华大学教Java,有12年教龄
我已经70岁了,依然站在讲台上讲课
注意:构造方法不能被继承,掌握这一点很重要。 一个类能得到构造方法,只有两个办法:编写构造方法,或者根本没有构造方法,类有一个默认的构造方法。
4.2 java super 关键字
super 可以用在子类中,通过点号(.)来获取父类的成员变量和方法。super 也可以用在子类的子类中,Java 能自动向上层类追溯。
父类行为被调用,就好象该行为是本类的行为一样,而且调用行为不必发生在父类中,它能自动向上层类追溯。
super 关键字的功能:
- 调用父类中声明为 private 的变量(意味着public成员可以直接调用)。 在C++中 子类是严格不能调用父类中私有成员的!
- 点取已经覆盖了的方法。
- 作为方法名表示父类构造方法。
调用隐藏变量和被覆盖的方法
public class Demo{ public static void main(String[] args) { Dog obj = new Dog(); obj.move(); } } class Animal{ private String desc = "Animals are human's good friends"; // 必须要声明一个 getter 方法 public String getDesc() { return desc; } public void move(){ System.out.println("Animals can move"); } } class Dog extends Animal{ public void move(){ super.move(); // 调用父类的方法 System.out.println("Dogs can walk and run"); // 通过 getter 方法调用父类隐藏变量 System.out.println("Please remember: " + super.getDesc()); } }
Animals can move
Dogs can walk and run
Please remember: Animals are human's good friends
move() 方法也可以定义在某些祖先类中,比如父类的父类,Java 具有追溯性,会一直向上找,直到找到该方法为止。
通过 super 调用父类的隐藏变量,必须要在父类中声明 getter 方法,因为声明为 private 的数据成员对子类是不可见的。
调用父类的构造方法
在许多情况下,使用默认构造方法来对父类对象进行初始化。当然也可以使用 super 来显示调用父类的构造方法。public class Demo{ public static void main(String[] args) { Dog obj = new Dog("花花", 3); obj.say(); } } class Animal{ String name; public Animal(String name){ this.name = name; } } class Dog extends Animal{ int age; public Dog(String name, int age){ super(name); this.age = age; } public void say(){ System.out.println("我是一只可爱的小狗,我的名字叫" + name + ",我" + age + "岁了"); } }
我是一只可爱的小狗,我的名字叫花花,我3岁了
//java public Dog(String name, int age){ super(name); this.age = age; } //C++ Student::Student(char *name, int age, float score): People(name, age){ this->score = score; }
值得注意的是:
- 在构造方法中调用另一个构造方法,调用动作必须置于最起始的位置。
- 不能在构造方法以外的任何方法内调用构造方法。
- 在一个构造方法内只能调用一个构造方法。
如果编写一个构造方法,既没有调用 super() 也没有调用 this(),编译器会自动插入一个调用到父类构造方法中,而且不带参数(和C++一样)。
最后注意 super 与 this 的区别:super 不是一个对象的引用,不能将 super 赋值给另一个对象变量,它只是一个指示编译器调用父类方法的特殊关键字。
在类继承中,子类可以修改从父类继承来的方法,也就是说子类能创建一个与父类方法有不同功能的方法,但具有相同的名称、返回值类型、参数列表。
如果在新类中定义一个方法,其名称、返回值类型和参数列表正好与父类中的相同,那么,新方法被称做覆盖旧方法。
参数列表又叫参数签名,包括参数的类型、参数的个数和参数的顺序,只要有一个不同就叫做参数列表不同。
被覆盖的方法在子类中只能通过super调用。
注意:覆盖不会删除父类中的方法,而是对子类的实例隐藏,暂时不使用。
也就是说,当子类中有雨父类一模一样的方法(函数)时,父类中该函数虽然是public但在子类中却是隐藏的,要想调用父类中这个函数需要用super;
请看下面的例子:
public class Demo{ public static void main(String[] args) { Dog myDog = new Dog("花花"); myDog.say(); // 子类的实例调用子类中的方法 Animal myAnmial = new Animal("贝贝"); myAnmial.say(); // 父类的实例调用父类中的方法 } } class Animal{ String name; public Animal(String name){ this.name = name; } public void say(){ System.out.println("我是一只小动物,我的名字叫" + name + ",我会发出叫声"); } } class Dog extends Animal{ // 构造方法不能被继承,通过super()调用 public Dog(String name){ super(name); } // 覆盖say() 方法 public void say(){ System.out.println("我是一只小狗,我的名字叫" + name + ",我会发出汪汪的叫声"); } }
运行结果:
我是一只小狗,我的名字叫花花,我会发出汪汪的叫声
我是一只小动物,我的名字叫贝贝,我会发出叫声
方法覆盖的原则:
- 覆盖方法的返回类型、方法名称、参数列表必须与原方法的相同。
- 覆盖方法不能比原方法访问性差(即访问权限不允许缩小)。
- 覆盖方法不能比原方法抛出更多的异常。
- 被覆盖的方法不能是final类型,因为final修饰的方法是无法覆盖的。
- 被覆盖的方法不能为private,否则在其子类中只是新定义了一个方法,并没有对其进行覆盖。
- 被覆盖的方法不能为static。如果父类中的方法为静态的,而子类中的方法不是静态的,但是两个方法除了这一点外其他都满足覆盖条件,那么会发生编译错误;反之亦然。即使父类和子类中的方法都是静态的,并且满足覆盖条件,但是仍然不会发生覆盖,因为静态方法是在编译的时候把静态方法和类的引用类型进行匹配。
方法的重载:
前面已经对Java方法重载进行了说明,这里再强调一下,Java父类和子类中的方法都会参与重载,例如,父类中有一个方法是 func(){ ... },子类中有一个方法是 func(int i){ ... },就构成了方法的重载。
覆盖和重载的不同:
- 方法覆盖要求参数列表必须一致,而方法重载要求参数列表必须不一致。
- 方法覆盖要求返回类型必须一致,方法重载对此没有要求。
- 方法覆盖只能用于子类覆盖父类的方法,方法重载用于同一个类中的所有方法(包括从父类中继承而来的方法)。
- 方法覆盖对方法的访问权限和抛出的异常有特殊的要求,而方法重载在这方面没有任何限制。
- 父类的一个方法只能被子类覆盖一次,而一个方法可以在所有的类中可以被重载多次。
4.4 Java多态和动态绑定
在Java中,父类的变量可以引用父类的实例,也可以引用子类的实例。
请读者先看一段代码:
public class Demo { public static void main(String[] args){ Animal obj = new Animal(); obj.cry(); obj = new Cat(); obj.cry(); obj = new Dog(); obj.cry(); } } class Animal{ // 动物的叫声 public void cry(){ System.out.println("不知道怎么叫"); } } class Cat extends Animal{ // 猫的叫声 public void cry(){ System.out.println("喵喵~"); } } class Dog extends Animal{ // 狗的叫声 public void cry(){ System.out.println("汪汪~"); } }
运行结果:
不知道怎么叫
喵喵~
汪汪~
上面的代码,定义了三个类,分别是 Animal、Cat 和 Dog,Cat 和 Dog 类都继承自 Animal 类。obj 变量的类型为 Animal,它既可以指向 Animal 类的实例,也可以指向 Cat 和 Dog 类的实例,这是正确的。也就是说,父类的变量可以引用父类的实例,也可以引用子类的实例。注意反过来是错误的,因为所有的猫都是动物,但不是所有的动物都是猫。
可以看出,obj 既可以是人类,也可以是猫、狗,它有不同的表现形式,这就被称为多态。多态是指一个事物有不同的表现形式或形态。
再比如“人类”,也有很多不同的表达或实现,TA 可以是司机、教师、医生等,你憎恨自己的时候会说“下辈子重新做人”,那么你下辈子成为司机、教师、医生都可以,我们就说“人类”具备了多态性。
多态存在的三个必要条件:要有继承、要有重写、父类变量引用子类对象。
当使用多态方式调用方法时:
- 首先检查父类中是否有该方法,如果没有,则编译错误;如果有,则检查子类是否覆盖了该方法。
- 如果子类覆盖了该方法,就调用子类的方法,否则调用父类方法。
从上面的例子可以看出,多态的一个好处是:当子类比较多时,也不需要定义多个变量,可以只定义一个父类类型的变量来引用不同子类的实例。请再看下面的一个例子:
public class Demo { public static void main(String[] args){ // 借助多态,主人可以给很多动物喂食 Master ma = new Master(); ma.feed(new Animal(), new Food()); ma.feed(new Cat(), new Fish()); ma.feed(new Dog(), new Bone()); } } // Animal类及其子类 class Animal{ public void eat(Food f){ System.out.println("我是一个小动物,正在吃" + f.getFood()); } } class Cat extends Animal{ public void eat(Food f){ System.out.println("我是一只小猫咪,正在吃" + f.getFood()); } } class Dog extends Animal{ public void eat(Food f){ System.out.println("我是一只狗狗,正在吃" + f.getFood()); } } // Food及其子类 class Food{ public String getFood(){ return "事物"; } } class Fish extends Food{ public String getFood(){ return "鱼"; } } class Bone extends Food{ public String getFood(){ return "骨头"; } } // Master类 class Master{ public void feed(Animal an, Food f){ an.eat(f); } }
运行结果:
我是一个小动物,正在吃事物
我是一只小猫咪,正在吃鱼
我是一只狗狗,正在吃骨头
Master 类的 feed 方法有两个参数,分别是 Animal 类型和 Food 类型,因为是父类,所以可以将子类的实例传递给它,这样 Master 类就不需要多个方法来给不同的动物喂食。
动态绑定
为了理解多态的本质,下面讲一下Java调用方法的详细流程。
1) 编译器查看对象的声明类型和方法名。
假设调用 obj.func(param),obj 为 Cat 类的对象。需要注意的是,有可能存在多个名字为func但参数签名不一样的方法。例如,可能存在方法 func(int) 和 func(String)。编译器将会一一列举所有 Cat 类中名为func的方法和其父类 Animal 中访问属性为 public 且名为func的方法。
这样,编译器就获得了所有可能被调用的候选方法列表。
2) 接下来,编泽器将检查调用方法时提供的参数签名。
如果在所有名为func的方法中存在一个与提供的参数签名完全匹配的方法,那么就选择这个方法。这个过程被称为重载解析(overloading resolution)。例如,如果调用 func("hello"),编译器会选择 func(String),而不是 func(int)。由于自动类型转换的存在,例如 int 可以转换为 double,如果没有找到与调用方法参数签名相同的方法,就进行类型转换后再继续查找,如果最终没有匹配的类型或者有多个方法与之匹配,那么编译错误。
这样,编译器就获得了需要调用的方法名字和参数签名。
3) 如果方法的修饰符是private、static、final(static和final将在后续讲解),或者是构造方法,那么编译器将可以准确地知道应该调用哪个方法,我们将这种调用方式 称为静态绑定(static binding)。(说白了是编译器编译那些已经定好了)
与此对应的是,调用的方法依赖于对象的实际类型, 并在运行时实现动态绑。例如调用 func("hello"),编泽器将采用动态绑定的方式生成一条调用 func(String) 的指令。(说白了就是编译的时候编译器有选择的进行编译)
4)当程序运行,并且釆用动态绑定调用方法时,JVM一定会调用与 obj 所引用对象的实际类型最合适的那个类的方法。我们已经假设 obj 的实际类型是 Cat,它是 Animal 的子类,如果 Cat 中定义了 func(String),就调用它,否则将在 Animal 类及其父类中寻找。
每次调用方法都要进行搜索,时间开销相当大,因此,JVM预先为每个类创建了一个方法表(method lable),其中列出了所有方法的名称、参数签名和所属的类。这样一来,在真正调用方法的时候,虚拟机仅查找这个表就行了。在上面的例子中,JVM 搜索 Cat 类的方法表,以便寻找与调用 func("hello") 相匹配的方法。这个方法既有可能是 Cat.func(String),也有可能是 Animal.func(String)。注意,如果调用super.func("hello"),编译器将对父类的方法表迸行搜索。
假设 Animal 类包含cry()、getName()、getAge() 三个方法,那么它的方法表如下:
cry() -> Animal.cry()
getName() -> Animal.getName()
getAge() -> Animal.getAge()
实际上,Animal 也有默认的父类 Object(后续会讲解),会继承 Object 的方法,所以上面列举的方法并不完整。
假设 Cat 类覆盖了 Animal 类中的 cry() 方法,并且新增了一个方法 climbTree(),那么它的参数列表为:
cry() -> Cat.cry()
getName() -> Animal.getName()
getAge() -> Animal.getAge()
climbTree() -> Cat.climbTree()
在运行的时候,调用 obj.cry() 方法的过程如下:
- JVM 首先访问 obj 的实际类型的方法表,可能是 Animal 类的方法表,也可能是 Cat 类及其子类的方法表。
- JVM 在方法表中搜索与 cry() 匹配的方法,找到后,就知道它属于哪个类了。
- JVM 调用该方法。
4.5 Java instanceof 运算符
多态性带来了一个问题,就是如何判断一个变量所实际引用的对象的类型 。 C++使用runtime-type information(RTTI),Java 使用 instanceof 操作符。
instanceof 运算符用来判断一个变量所引用的对象的实际类型,注意是它引用的对象的类型,不是变量的类型。请看下面的代码:
public final class Demo{ public static void main(String[] args) { // 引用 People 类的实例 People obj = new People(); if(obj instanceof Object){ System.out.println("我是一个对象"); } if(obj instanceof People){ System.out.println("我是人类"); } if(obj instanceof Teacher){ System.out.println("我是一名教师"); } if(obj instanceof President){ System.out.println("我是校长"); } System.out.println("-----------"); // 分界线 // 引用 Teacher 类的实例 obj = new Teacher(); if(obj instanceof Object){ System.out.println("我是一个对象"); } if(obj instanceof People){ System.out.println("我是人类"); } if(obj instanceof Teacher){ System.out.println("我是一名教师"); } if(obj instanceof President){ System.out.println("我是校长"); } } } class People{ } class Teacher extends People{ } class President extends Teacher{ }
运行结果:
我是一个对象
我是人类
-----------
我是一个对象
我是人类
我是一名教师
说白了是 前者 instanceof 后者; 前后两者嫡系 前者大于等于后者 前者是实例 后者是类
可以看出,如果变量引用的是当前类或它的子类的实例,instanceof 返回 true,否则返回 false。
4.6 多态对象的类型转换
这里所说的对象类型转换,是指存在继承关系的对象,不是任意类型的对象。当对不存在继承关系的对象进行强制类型转换时,java 运行时将抛出 java.lang.ClassCastException 异常。
在继承链中,我们将子类向父类转换称为“向上转型”,将父类向子类转换称为“向下转型”。
很多时候,我们会将变量定义为父类的类型,却引用子类的对象,这个过程就是向上转型。程序运行时通过动态绑定来实现对子类方法的调用,也就是多态性。
然而有些时候为了完成某些父类没有的功能,我们需要将向上转型后的子类对象再转成子类,调用子类的方法,这就是向下转型。
注意:不能直接将父类的对象强制转换为子类类型,只能将向上转型后的子类对象再次转换为子类类型。也就是说,子类对象必须向上转型后,才能再向下转型。请看下面的代码:
public class Demo { public static void main(String args[]) { SuperClass superObj = new SuperClass(); SonClass sonObj = new SonClass(); // 下面的代码运行时会抛出异常,不能将父类对象直接转换为子类类型 // SonClass sonObj2 = (SonClass)superObj; // 先向上转型,再向下转型 superObj = sonObj; //实际的效果是完成地址转移 SonClass sonObj1 = (SonClass)superObj; } } class SuperClass{ } class SonClass extends SuperClass{ }
将第7行的注释去掉,运行时会抛出异常,但是编译可以通过。
因为向下转型存在风险,所以在接收到父类的一个引用时,请务必使用 instanceof 运算符来判断该对象是否是你所要的子类,请看下面的代码:
public class Demo { public static void main(String args[]) { SuperClass superObj = new SuperClass(); SonClass sonObj = new SonClass(); // superObj 不是 SonClass 类的实例 if(superObj instanceof SonClass){ SonClass sonObj1 = (SonClass)superObj; }else{ System.out.println("①不能转换"); } superObj = sonObj; // superObj 是 SonClass 类的实例 if(superObj instanceof SonClass){ SonClass sonObj2 = (SonClass)superObj; }else{ System.out.println("②不能转换"); } } } class SuperClass{ } class SonClass extends SuperClass{ }
运行结果:
①不能转换
总结:对象的类型转换在程序运行时检查,向上转型会自动进行,向下转型的对象必须是当前引用类型的子类。
4.7 Java static关键字以及Java静态变量和静态方法
static 修饰符能够与变量、方法一起使用,表示是“静态”的。
静态变量和静态方法能够通过类名来访问,不需要创建一个类的对象来访问该类的静态成员,所以static修饰的成员又称作类变量和类方法。静态变量与实例变量不同,实例变量总是通过对象来访问,因为它们的值在对象和对象之间有所不同。
请看下面的例子:
public class Demo { static int i = 10; int j; Demo() { this.j = 20; } public static void main(String[] args) { System.out.println("类变量 i=" + Demo.i); Demo obj = new Demo(); //这样可以直接用 System.out.println("实例变量 j=" + obj.j); } }
运行结果:
类变量 i=10
实例变量 j=20
static 的内存分配
静态变量属于类,不属于任何独立的对象,所以无需创建类的实例就可以访问静态变量。之所以会产生这样的结果,是因为编译器只为整个类创建了一个静态变量的副本,也就是只分配一个内存空间,虽然有多个实例,但这些实例共享该内存。实例变量则不同,每创建一个对象,都会分配一次内存空间,不同变量的内存相互独立,互不影响,改变 a 对象的实例变量不会影响 b 对象。
请看下面的代码:
public class Demo { static int i; //i只占一块固定的内存 int j; public static void main(String[] args) { Demo obj1 = new Demo(); obj1.i = 10; obj1.j = 20; Demo obj2 = new Demo(); System.out.println("obj1.i=" + obj1.i + ", obj1.j=" + obj1.j); System.out.println("obj2.i=" + obj2.i + ", obj2.j=" + obj2.j); } }
运行结果:
obj1.i=10, obj1.j=20
obj2.i=10, obj2.j=0
注意:静态变量虽然也可以通过对象来访问,但是不被提倡,编译器也会产生警告。
上面的代码中,i 是静态变量,通过 obj1 改变 i 的值,会影响到 obj2;j 是实例变量,通过 obj1 改变 j 的值,不会影响到 obj2。这是因为 obj1.i 和 obj2.i 指向同一个内存空间,而 obj1.j 和 obj2.j 指向不同的内存空间,请看下图:
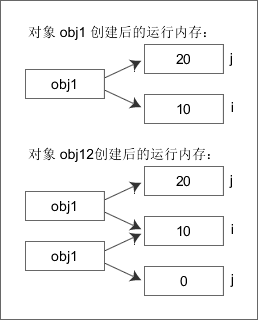
图1 静态变量内存分配
注意:static 的变量是在类装载的时候就会被初始化。也就是说,只要类被装载,不管你是否使用了这个static 变量,它都会被初始化。
小结:类变量(class variables)用关键字 static 修饰,在类加载的时候,分配类变量的内存,以后再生成类的实例对象时,将共享这块内存(类变量),任何一个对象对类变量的修改,都会影响其它对象。外部有两种访问方式:通过对象来访问或通过类名来访问。
静态方法
静态方法是一种不能向对象实施操作的方法。例如,Math 类的 pow() 方法就是一个静态方法,语法为 Math.pow(x, a),用来计算 x 的 a 次幂,在使用时无需创建任何 Math 对象。
因为静态方法不能操作对象,所以不能在静态方法中访问实例变量,只能访问自身类的静态变量。
以下情形可以使用静态方法:
- 一个方法不需要访问对象状态,其所需参数都是通过显式参数提供(例如 Math.pow())。
- 一个方法只需要访问类的静态变量。
读者肯定注意到,main() 也是一个静态方法,不对任何对象进行操作。实际上,在程序启动时还没有任何对象,main() 方法是程序的入口,将被执行并创建程序所需的对象。
关于静态变量和静态方法的总结:
- 一个类的静态方法只能访问静态变量;
- 一个类的静态方法不能够直接调用非静态方法;
- 如访问控制权限允许,静态变量和静态方法也可以通过对象来访问,但是不被推荐;
- 静态方法中不存在当前对象,因而不能使用 this,当然也不能使用 super;
- 静态方法不能被非静态方法覆盖;
- 构造方法不允许声明为 static 的;
- 局部变量不能使用static修饰。
静态方法举例:
public class Demo { static int sum(int x, int y){ return x + y; } public static void main(String[] args) {
//这里没有任何 “实例化” 下面是直接调用 int sum = Demo.sum(10, 10); System.out.println("10+10=" + sum); } }
运行结果:
10+10=20
static 方法不需它所属的类的任何实例就会被调用,因此没有 this 值,不能访问实例变量,否则会引起编译错误。
注意:实例变量只能通过对象来访问,不能通过类访问。
静态初始器(静态块)
块是由大括号包围的一段代码。静态初始器(Static Initializer)是一个存在于类中、方法外面的静态块。静态初始器仅仅在类装载的时候(第一次使用类的时候)执行一次,往往用来初始化静态变量。
示例代码:
public class Demo { public static int i; static{ i = 10; System.out.println("Now in static block."); } public void test() { System.out.println("test method: i=" + i); } public static void main(String[] args) { System.out.println("Demo.i=" + Demo.i); new Demo().test(); } }
运行结果是:
Now in static block.
Demo.i=10
test method: i=10
静态导入
静态导入是 Java 5 的新增特性,用来导入类的静态变量和静态方法。
一般我们导入类都这样写:
import packageName.className; // 导入某个特定的类
或
import packageName.*; // 导入包中的所有类
而静态导入可以这样写:
import static packageName.className.methonName; // 导入某个特定的静态方法
或
import static packageName.className.*; // 导入类中的所有静态成员
导入后,可以在当前类中直接用方法名调用静态方法,不必再用 className.methodName 来访问。
对于使用频繁的静态变量和静态方法,可以将其静态导入。静态导入的好处是可以简化一些操作,例如输出语句 System.out.println(); 中的 out 就是 System 类的静态变量,可以通过 import static java.lang.System.*; 将其导入,下次直接调用 out.println() 就可以了。
请看下面的代码:
import static java.lang.System.*; import static java.lang.Math.random; public class Demo { public static void main(String[] args) { out.println("产生的一个随机数:" + random()); } }
运行结果:
产生的一个随机数:0.05800891549018705
4.8 Java final关键字:阻止继承和多态
在 Java 中,声明类、变量和方法时,可使用关键字 final 来修饰。final 所修饰的数据具有“终态”的特征,表示“最终的”意思。具体规定如下:
- final 修饰的类不能被继承。
- final 修饰的方法不能被子类重写。
- final 修饰的变量(成员变量或局部变量)即成为常量,只能赋值一次。
- final 修饰的成员变量必须在声明的同时赋值,如果在声明的时候没有赋值,那么只有 一次赋值的机会,而且只能在构造方法中显式赋值,然后才能使用。
- final 修饰的局部变量可以只声明不赋值,然后再进行一次性的赋值。
final 一般用于修饰那些通用性的功能、实现方式或取值不能随意被改变的数据,以避免被误用,例如实现数学三角方法、幂运算等功能的方法,以及数学常量π=3.141593、e=2.71828 等。
事实上,为确保终态性,提供了上述方法和常量的 java.lang.Math 类也已被定义为final 的。
需要注意的是,如果将引用类型(任何类的类型)的变量标记为 final,那么该变量不能指向任何其它对象。但可以改变对象的内容,因为只有引用本身是 final 的。
如果变量被标记为 final,其结果是使它成为常数。想改变 final 变量的值会导致一个编译错误。下面是一个正确定义 final 变量的例子:
public final int MAX_ARRAY_SIZE = 25; // 常量名一般大写
常量因为有 final 修饰,所以不能被继承。
请看下面的代码:
public final class Demo{ public static final int TOTAL_NUMBER = 5; public int id; public Demo() { // 非法,对final变量TOTAL_NUMBER进行二次赋值了 // 因为++TOTAL_NUMBER相当于 TOTAL_NUMBER=TOTAL_NUMBER+1 id = ++TOTAL_NUMBER; } public static void main(String[] args) { final Demo t = new Demo(); final int i = 10; final int j; j = 20; j = 30; // 非法,对final变量进行二次赋值 } }
final 也可以用来修饰类(放在 class 关键字前面),阻止该类再派生出子类,例如 Java.lang.String 就是一个 final 类。这样做是出于安全原因,因为要保证一旦有字符串的引用,就必须是类 String 的字符串,而不是某个其它类的字符串(String 类可能被恶意继承并篡改)。
方法也可以被 final 修饰,被 final 修饰的方法不能被覆盖;变量也可以被 final 修饰,被 final 修饰的变量在创建对象以后就不允许改变它们的值了。一旦将一个类声明为 final,那么该类包含的方法也将被隐式地声明为 final,但是变量不是。
被 final 修饰的方法为静态绑定,不会产生多态(动态绑定),程序在运行时不需要再检索方法表,能够提高代码的执行效率。在Java中,被 static 或 private 修饰的方法会被隐式的声明为 final,因为动态绑定没有意义。
由于动态绑定会消耗资源并且很多时候没有必要,所以有一些程序员认为:除非有足够的理由使用多态性,否则应该将所有的方法都用 final 修饰。
这样的认识未免有些偏激,因为 JVM 中的即时编译器能够实时监控程序的运行信息,可以准确的知道类之间的继承关系。如果一个方法没有被覆盖并且很短,编译器就能够对它进行优化处理,这个过程为称为内联(inlining)。例如,内联调用 e.getName() 将被替换为访问 e.name 变量。这是一项很有意义的改进,这是由于CPU在处理调用方法的指令时,使用的分支转移会扰乱预取指令的策略,所以,这被视为不受欢迎的。然而,如果 getName() 在另外一个类中被覆盖,那么编译器就无法知道覆盖的代码将会做什么操作,因此也就不能对它进行内联处理了。
4.9 java Object类
Object 类位于 java.lang 包中,是所有 Java 类的祖先,Java 中的每个类都由它扩展而来。
定义Java类时如果没有显示的指明父类,那么就默认继承了 Object 类。例如:
public class Demo{ // ... }
实际上是下面代码的简写形式:
public class Demo extends Object{ // ... }
在Java中,只有基本类型不是对象,例如数值、字符和布尔型的值都不是对象,所有的数组类型,不管是对象数组还是基本类型数组都是继承自 Object 类。
Object 类定义了一些有用的方法(如下),由于是根类,这些方法在其他类中都存在,一般是进行了重载或覆盖,实现了各自的具体功能。
equals() 方法
Object 类中的 equals() 方法用来检测一个对象是否等价于另外一个对象,语法为:
public boolean equals(Object obj)
例如:
obj1.equals(obj2);
在Java中,数据等价的基本含义是指两个数据的值相等。在通过 equals() 和“==”进行比较的时候,引用类型数据比较的是引用,即内存地址,基本数据类型比较的是值。
注意:
- equals()方法只能比较引用类型,“==”可以比较引用类型及基本类型。
- 当用 equals() 方法进行比较时,对类 File、String、Date 及包装类来说,是比较类型及内容而不考虑引用的是否是同一个实例。
- 用“==”进行比较时,符号两边的数据类型必须一致(可自动转换的数据类型除外),否则编译出错,而用 equals 方法比较的两个数据只要都是引用类型即可。
hashCode() 方法
散列码(hashCode)是按照一定的算法由对象得到的一个数值,散列码没有规律。如果 x 和 y 是不同的对象,x.hashCode() 与 y.hashCode() 基本上不会相同。
hashCode() 方法主要用来在集合中实现快速查找等操作,也可以用于对象的比较。
在 Java 中,对 hashCode 的规定如下:
- 在同一个应用程序执行期间,对同一个对象调用 hashCode(),必须返回相同的整数结果——前提是 equals() 所比较的信息都不曾被改动过。至于同一个应用程序在不同执行期所得的调用结果,无需一致。
- 如果两个对象被 equals() 方法视为相等,那么对这两个对象调用 hashCode() 必须获得相同的整数结果。
- 如果两个对象被 equals() 方法视为不相等,那么对这两个对象调用 hashCode() 不必产生不同的整数结果。然而程序员应该意识到,对不同对象产生不同的整数结果,有可能提升hashTable(后面会学到,集合框架中的一个类)的效率。
简单地说:如果两个对象相同,那么它们的 hashCode 值一定要相同;如果两个对象的 hashCode 值相同,它们并不一定相同。在 Java 规范里面规定,一般是覆盖 equals() 方法应该连带覆盖 hashCode() 方法。
toString() 方法
toString() 方法是 Object 类中定义的另一个重要方法,是对象的字符串表现形式,语法为:
public String toString()
返回值是 String 类型,用于描述当前对象的有关信息。Object 类中实现的 toString() 方法是返回当前对象的类型和内存地址信息,但在一些子类(如 String、Date 等)中进行了 重写,也可以根据需要在用户自定义类型中重写 toString() 方法,以返回更适用的信息。
除显式调用对象的 toString() 方法外,在进行 String 与其它类型数据的连接操作时,会自动调用 toString() 方法。
以上几种方法,在Java中是经常用到的,这里仅作简单介绍,让大家对Object类和其他类有所了解,详细说明请参考 Java API 文档。
五◐ 面向对象高级特性
5.1 Java内部类及其实例化
在 Java 中,允许在一个类(或方法、语句块)的内部定义另一个类,称为内部类(Inner Class),有时也称为嵌套类(Nested Class)。
内部类和外层封装它的类之间存在逻辑上的所属关系,一般只用在定义它的类或语句块之内,实现一些没有通用意义的功能逻辑,在外部引用它时必须给出完整的名称。
使用内部类的主要原因有:
- 内部类可以访问外部类中的数据,包括私有的数据。
- 内部类可以对同一个包中的其他类隐藏起来。
- 当想要定义一个回调函数且不想编写大量代码时,使用匿名(anonymous)内部类比较便捷。
- 减少类的命名冲突。
请看下面的例子:
public class Outer { private int size; public class Inner { private int counter = 10; public void doStuff() { size++; } } public static void main(String args[]) { Outer outer = new Outer(); Inner inner = outer.new Inner(); //请记住此处定义方法 inner.doStuff(); System.out.println(outer.size); System.out.println(inner.counter); // 编译错误,外部类不能访问内部类的变量 System.out.println(counter); //是这句错 } }
这段代码定义了一个外部类 Outer,它包含了一个内部类 Inner。将错误语句注释掉,编译,会生成两个 .class 文件:Outer.class 和 Outer$Inner.class。也就是说,内部类会被编译成独立的字节码文件。
内部类是一种编译器现象,与虚拟机无关。编译器将会把内部类翻译成用 $ 符号分隔外部类名与内部类名的常规类文件,而虚拟机则对此一无所知。
注意:必须先有外部类的对象才能生成内部类的对象,因为内部类需要访问外部类中的成员变量,成员变量必须实例化才有意义。
内部类是 Java 1.1 的新增特性,有些程序员认为这是一个值得称赞的进步,但是内部类的语法很复杂,严重破坏了良好的代码结构, 违背了Java要比C++更加简单的设计理念。
内部类看似增加了—些优美有趣,实属没必要的特性,这是不是也让Java开始走上了许多语言饱受折磨的毁灭性道路呢?本教程并不打算就这个问题给予一个肯定的答案。
5.2 java 静态内部类、匿名内部类、成员式内部类和局部内部类
内部类可以是静态(static)的,可以使用 public、protected 和 private 访问控制符,而外部类只能使用 public,或者默认。
成员式内部类
在外部类内部直接定义(不在方法内部或代码块内部)的类就是成员式内部类,它可以直接使用外部类的所有变量和方法,即使是 private 的。外部类要想访问内部类的成员变量和方法,则需要通过内部类的对象来获取。
请看下面的代码:
public class Outer{ private int size; public class Inner { public void dostuff() { size++; } } public void testTheInner() { Inner in = new Inner(); in.dostuff(); } }
成员式内部类如同外部类的一个普通成员。
成员式内部类可以使用各种修饰符,包括 public、protected、private、static、final 和 abstract,也可以不写。
若有 static 修饰符,就为类级,否则为对象级。类级可以通过外部类直接访问,对象级需要先生成外部的对象后才能访问。
非静态内部类中不能声明任何 static 成员。
内部类可以相互调用,例如:
class A { // B、C 间可以互相调用 class B {} class C {} }
成员式内部类的访问
内部类的对象以成员变量的方式记录其所依赖的外层类对象的引用,因而可以找到该外层类对象并访问其成员。该成员变量是系统自动为非 static 的内部类添加的,名称约定为“outClassName.this”。
1) 使用内部类中定义的非静态变量和方法时,要先创建外部类的对象,再由“outObjectName.new”操作符创建内部类的对象,再调用内部类的方法,如下所示:
public class Demo{ public static void main(String[] args) { Outer outer = new Outer(); Outer.Inner inner = outer.new Inner(); //这句 inner.dostuff(); } } class Outer{ private int size; class Inner{ public void dostuff() { size++; } } }
2) static 内部类相当于其外部类的 static 成员,它的对象与外部类对象间不存在依赖关系,因此可直接创建。示例如下:
public class Demo{ public static void main(String[] args) { Outer.Inner inner = new Outer.Inner(); // inner.dostuff(); } } class Outer{ private static int size; static class Inner { public void dostuff() { size++; System.out.println("size=" + size); } } }
运行结果:
size=1
3) 由于内部类可以直接访问其外部类的成分,因此当内部类与其外部类中存在同名属性或方法时,也将导致命名冲突。所以在多层调用时要指明,如下所示:
public class Outer{ private int size; public class Inner{ private int size; public void dostuff(int size){ size++; // 局部变量 size; this.size; // 内部类的 size Outer.this.size++; // 外部类的 size } } }//这里你可以看到this的强大之处
局部内部类
局部内部类(Local class)是定义在代码块中的类。它们只在定义它们的代码块中是可见的。
局部类有几个重要特性:
- 仅在定义了它们的代码块中是可见的;
- 可以使用定义它们的代码块中的任何局部 final 变量;
- 局部类不可以是 static 的,里边也不能定义 static 成员;
- 局部类不可以用 public、private、protected 修饰,只能使用缺省的;
- 局部类可以是 abstract 的。
请看下面的代码:
public class Outer { public static final int TOTAL_NUMBER = 5; //此处可以记好关键词使用的先后顺序 public int id = 123; public void func() { final int age = 15; String str = "http://www.weixueyuan.net"; class Inner { public void innerTest() { System.out.println(TOTAL_NUMBER); System.out.println(id); // System.out.println(str);不合法,只能访问本地方法的final变量 ??? System.out.println(age); } } new Inner().innerTest(); } public static void main(String[] args) { Outer outer = new Outer(); outer.func(); } }
运行结果:
5
123
15
匿名内部类
1 abstract类中必须有abstract方法 ×
2 abstract方法所在的类必须用abstract修饰 √
abstract类 及 抽象类
抽象类中可以没有抽象的方法,只是抽象类不能实例化。
但是一旦一个类中有抽象方法,所在class必定要是abstract,否则会有编译错误
匿名内部类是局部内部类的一种特殊形式,也就是没有变量名指向这个类的实例,而且具体的类实现会写在这个内部类里面。
注意:匿名类必须继承一个父类或实现一个接口。
不使用匿名内部类来实现抽象方法:
abstract class Person { public abstract void eat(); } class Child extends Person { public void eat() { System.out.println("eat something"); } } public class Demo { public static void main(String[] args) { Person p = new Child(); p.eat(); } }
运行结果:
eat something
可以看到,我们用Child继承了Person类,然后实现了Child的一个实例,将其向上转型为Person类的引用。但是,如果此处的Child类只使用一次,那么将其编写为独立的一个类岂不是很麻烦?
这个时候就引入了匿名内部类。使用匿名内部类实现:
可以看到,匿名类继承了 Person 类并在大括号中实现了抽象类的方法。
内部类的语法比较复杂,实际开发中也较少用到,本教程不打算进行深入讲解,各位读者也不应该将内部类作为学习Java的重点。
5.3 Java抽象类的概念和使用
在自上而下的继承层次结构中,位于上层的类更具有通用性,甚至可能更加抽象。从某种角度看,祖先类更加通用,它只包含一些最基本的成员,人们只将它作为派生其他类的基类,而不会用来创建对象。甚至,你可以只给出方法的定义而不实现,由子类根据具体需求来具体实现。
这种只给出方法定义而不具体实现的方法被称为抽象方法,抽象方法是没有方法体的,在代码的表达上就是没有“{}”。包含一个或多个抽象方法的类也必须被声明为抽象类。
使用 abstract 修饰符来表示抽象方法和抽象类。 (抽象类相当于C++中的基类)但C++基类可以直接使用;
抽象类除了包含抽象方法外,还可以包含具体的变量和具体的方法。类即使不包含抽象方法,也可以被声明为抽象类,防止被实例化。
抽象类不能被实例化,抽象方法必须在子类中被实现。请看下面的代码:
import static java.lang.System.*; public final class Demo{ public static void main(String[] args) { Teacher t = new Teacher(); t.setName("王明"); t.work(); Driver d = new Driver(); d.setName("小陈"); d.work(); } } // 定义一个抽象类 abstract class People{ private String name; // 实例变量 // 共有的 setter 和 getter 方法 public void setName(String name){ this.name = name; } public String getName(){ return this.name; } // 抽象方法 public abstract void work(); //空的; } class Teacher extends People{ // 必须实现该方法 public void work(){ out.println("我的名字叫" + this.getName() + ",我正在讲课,请大家不要东张西望..."); } } class Driver extends People{ // 必须实现该方法 public void work(){ out.println("我的名字叫" + this.getName() + ",我正在开车,不能接听电话..."); } }
运行结果:
我的名字叫王明,我正在讲课,请大家不要东张西望...
我的名字叫小陈,我正在开车,不能接听电话...
关于抽象类的几点说明:
- 抽象类不能直接使用,必须用子类去实现抽象类,然后使用其子类的实例。然而可以创建一个变量,其类型是一个抽象类,并让它指向具体子类的一个实例,也就是可以使用抽象类来充当形参,实际实现类作为实参,也就是多态的应用。
- 不能有抽象构造方法或抽象静态方法。
在下列情况下,一个类将成为抽象类:
- 当一个类的一个或多个方法是抽象方法时;
- 当类是一个抽象类的子类,并且不能为任何抽象方法提供任何实现细节或方法主体时;
- 当一个类实现一个接口,并且不能为任何抽象方法提供实现细节或方法主体时;注意:
- 这里说的是这些情况下一个类将成为抽象类,没有说抽象类一定会有这些情况。
- 一个典型的错误:抽象类一定包含抽象方法。 但是反过来说“包含抽象方法的类一定是抽象类”就是正确的。
- 事实上,抽象类可以是一个完全正常实现的类
5.4 Java接口(interface)的概念及使用
在抽象类中,可以包含一个或多个抽象方法;但在接口(interface)中,所有的方法必须都是抽象的,不能有方法体,它比抽象类更加“抽象”。
接口使用 interface 关键字来声明,可以看做是一种特殊的抽象类,可以指定一个类必须做什么,而不是规定它如何去做。
现实中也有很多接口的实例,比如说串口电脑硬盘,Serial ATA委员会指定了Serial ATA 2.0规范,这种规范就是接口。Serial ATA委员会不负责生产硬盘,只是指定通用的规范。
希捷、日立、三星等生产厂家会按照规范生产符合接口的硬盘,这些硬盘就可以实现通用化,如果正在用一块160G日立的串口硬盘,现在要升级了,可以购买一块320G的希捷串口硬盘,安装上去就可以继续使用了。
下面的代码可以模拟Serial ATA委员会定义以下串口硬盘接口:
//串行硬盘接口 public interface SataHdd{ //连接线的数量 public static final int CONNECT_LINE=4; //写数据 public void writeData(String data); //读数据 public String readData(); }
注意:接口中声明的成员变量默认都是 public static final 的,必须显示的初始化。因而在常量声明时可以省略这些修饰符。
接口是若干常量和抽象方法的集合,目前看来和抽象类差不多。确实如此,接口本就是从抽象类中演化而来的,因而除特别规定,接口享有和类同样的“待遇”。比如,源程序中可以定义多个类或接口,但最多只能有一个public 的类或接口,如果有则源文件必须取和public的类和接口相同的名字。和类的继承格式一样,接口之间也可以继承,子接口可以继承父接口中的常量和抽象方法并添加新的抽象方法等。
但接口有其自身的一些特性,归纳如下。
1) 接口中只能定义抽象方法,这些方法默认为 public abstract 的,因而在声明方法时可以省略这些修饰符。试图在接口中定义实例变量、非抽象的实例方法及静态方法,都是非法的。例如:
public interface SataHdd{ //连接线的数量 public int connectLine; //编译出错,connectLine被看做静态常量,必须显式初始化 //写数据 protected void writeData(String data); //编译出错,必须是public类型 //读数据 public static String readData(){ //编译出错,接口中不能包含静态方法 return "数据"; //编译出错,接口中只能包含抽象方法, } }
3) 接口中没有构造方法,不能被实例化。
4) 一个接口不实现另一个接口,但可以继承多个其他接口。接口的多继承特点弥补了类的单继承。例如:
//串行硬盘接口 public interface SataHdd extends A,B{ // 连接线的数量 public static final int CONNECT_LINE = 4; // 写数据 public void writeData(String data); // 读数据 public String readData(); } interface A{ public void a(); } interface B{ public void b(); }
为什么使用接口
大型项目开发中,可能需要从继承链的中间插入一个类,让它的子类具备某些功能而不影响它们的父类。例如 A -> B -> C -> D -> E,A 是祖先类,如果需要为C、D、E类添加某些通用的功能,最简单的方法是让C类再继承另外一个类。但是问题来了,Java 是一种单继承的语言,不能再让C继承另外一个父类了,只到移动到继承链的最顶端,让A再继承一个父类。这样一来,对C、D、E类的修改,影响到了整个继承链,不具备可插入性的设计。
接口是可插入性的保证。在一个继承链中的任何一个类都可以实现一个接口,这个接口会影响到此类的所有子类,但不会影响到此类的任何父类。此类将不得不实现这个接口所规定的方法,而子类可以从此类自动继承这些方法,这时候,这些子类具有了可插入性。
我们关心的不是哪一个具体的类,而是这个类是否实现了我们需要的接口。
接口提供了关联以及方法调用上的可插入性,软件系统的规模越大,生命周期越长,接口使得软件系统的灵活性和可扩展性,可插入性方面得到保证。
接口在面向对象的 Java 程序设计中占有举足轻重的地位。事实上在设计阶段最重要的任务之一就是设计出各部分的接口,然后通过接口的组合,形成程序的基本框架结构。
接口的使用
接口的使用与类的使用有些不同。在需要使用类的地方,会直接使用new关键字来构建一个类的实例,但接口不可以这样使用,因为接口不能直接使用 new 关键字来构建实例。
接口必须通过类来实现(implements)它的抽象方法,然后再实例化类。类实现接口的关键字为implements。
如果一个类不能实现该接口的所有抽象方法,那么这个类必须被定义为抽象方法。
不允许创建接口的实例,但允许定义接口类型的引用变量,该变量指向了实现接口的类的实例。
一个类只能继承一个父类,但却可以实现多个接口。
实现接口的格式如下:
修饰符 class 类名 extends 父类 implements 多个接口 {
实现方法
}
请看下面的例子:
import static java.lang.System.*; public class Demo{ public static void main(String[] args) { SataHdd sh1=new SeagateHdd(); //初始化希捷硬盘 可以直接初始化,也就是可以直接用了,这是和 ???这难道不是实例化了吗 SataHdd sh2=new SamsungHdd(); //初始化三星硬盘 } } //串行硬盘接口 interface SataHdd{ //连接线的数量 public static final int CONNECT_LINE=4; //写数据 public void writeData(String data); //读数据 public String readData(); } // 维修硬盘接口 interface fixHdd{ // 维修地址 String address = "北京市海淀区"; // 开始维修 boolean doFix(); } //希捷硬盘 class SeagateHdd implements SataHdd, fixHdd{ //这里 //希捷硬盘读取数据 public String readData(){ return "数据"; } //希捷硬盘写入数据 public void writeData(String data) { out.println("写入成功"); } // 维修希捷硬盘 public boolean doFix(){ return true; } } //三星硬盘 class SamsungHdd implements SataHdd{ //三星硬盘读取数据 public String readData(){ return "数据"; } //三星硬盘写入数据 public void writeData(String data){ out.println("写入成功"); } } //某劣质硬盘,不能写数据 abstract class XXHdd implements SataHdd{ //硬盘读取数据 public String readData() { return "数据"; } }
接口作为类型使用
接口作为引用类型来使用,任何实现该接口的类的实例都可以存储在该接口类型的变量中,通过这些变量可以访问类中所实现的接口中的方法,Java 运行时系统会动态地确定应该使用哪个类中的方法,实际上是调用相应的实现类的方法。
示例如下:
public class Demo{ public void test1(A a) { a.doSth(); } public static void main(String[] args) { Demo d = new Demo(); A a = new B(); //这一步影响了; d.test1(a); } } interface A { public int doSth(); } class B implements A { public int doSth() { System.out.println("now in B"); return 123; } }
运行结果:
now in B
大家看到接口可以作为一个类型来使用,把接口作为方法的参数和返回类型。
5.5 Java接口和抽象类的区别
类是对象的模板,抽象类和接口可以看做是具体的类的模板。
由于从某种角度讲,接口是一种特殊的抽象类,它们的渊源颇深,有很大的相似之处,所以在选择使用谁的问题上很容易迷糊。我们首先分析它们具有的相同点。
- 都代表类树形结构的抽象层。在使用引用变量时,尽量使用类结构的抽象层,使方法的定义和实现分离,这样做对于代码有松散耦合的好处。
- 都不能被实例化。
- 都能包含抽象方法。抽象方法用来描述系统提供哪些功能,而不必关心具体的实现。
下面说一下抽象类和接口的主要区别。
1) 抽象类可以为部分方法提供实现,避免了在子类中重复实现这些方法,提高了代码的可重用性,这是抽象类的优势;而接口中只能包含抽象方法,不能包含任何实现。
public abstract class A{ public abstract void method1(); public void method2(){ //A method2 } } public class B extends A{ public void method1(){ //B method1 } } public class C extends A{ public void method1(){ //C method1 } }
抽象类A有两个子类B、C,由于A中有方法method2的实现,子类B、C中不需要重写method2方法,我们就说A为子类提供了公共的功能,或A约束了子类的行为。method2就是代码可重用的例子。A 并没有定义 method1的实现,也就是说B、C 可以根据自己的特点实现method1方法,这又体现了松散耦合的特性。
再换成接口看看:
public interface A{ public void method1(); //也就是说method1(),method2()不能有自己的函数体,函数体需要在调用它的子类中书写 public void method2(); } public class B implements A{ public void method1(){ //B method1 } public void method2(){ //B method2 } } public class C implements A{ public void method1(){ //C method1 } public void method2(){ //C method2 } }
接口A无法为实现类B、C提供公共的功能,也就是说A无法约束B、C的行为。B、C可以自由地发挥自己的特点现实 method1和 method2方法,接口A毫无掌控能力。
2) 一个类只能继承一个直接的父类(可能是抽象类),但一个类可以实现多个接口,这个就是接口的优势。
interface A{ public void method2(); } interface B{ public void method1(); } class C implements A,B{ public void method1(){ //C method1 } public void method2(){ //C method2 } } //可以如此灵活的使用C,并且C还有机会进行扩展,实现其他接口 A a=new C(); B b=new C(); abstract class A{ public abstract void method1(); } abstract class B extends A{ public abstract void method2(); } class C extends B{ public void method1(){ //C method1 } public void method2() { //C method2 } }
对于C类,将没有机会继承其他父类了。
综上所述,接口和抽象类各有优缺点,在接口和抽象类的选择上,必须遵守这样一个原则:
- 行为模型应该总是通过接口而不是抽象类定义,所以通常是优先选用接口,尽量少用抽象类。
- 选择抽象类的时候通常是如下情况:需要定义子类的行为,又要为子类提供通用的功能。
5.6 java泛型
我们知道,使用变量之前要定义,定义一个变量时必须要指明它的数据类型,什么样的数据类型赋给什么样的值。
假如我们现在要定义一个类来表示坐标,要求坐标的数据类型可以是整数、小数和字符串,例如:
- x = 10、y = 10
- x = 12.88、y = 129.65
- x = "东京180度"、y = "北纬210度"
针对不同的数据类型,除了借助方法重载,还可以借助自动装箱和向上转型。我们知道,基本数据类型可以自动装箱,被转换成对应的包装类;Object 是所有类的祖先类,任何一个类的实例都可以向上转型为 Object 类型,例如:
- int --> Integer --> Object
- double -->Double --> Object
- String --> Object
这样,只需要定义一个方法,就可以接收所有类型的数据。请看下面的代码:
public class Demo { public static void main(String[] args){ Point p = new Point(); p.setX(10); // int -> Integer -> Object p.setY(20); int x = (Integer)p.getX(); // 必须向下转型 int y = (Integer)p.getY(); System.out.println("This point is:" + x + ", " + y); p.setX(25.4); // double -> Integer -> Object p.setY("东京180度"); double m = (Double)p.getX(); // 必须向下转型 double n = (Double)p.getY(); // 运行期间抛出异常 System.out.println("This point is:" + m + ", " + n); } } class Point{ Object x = 0; Object y = 0; public Object getX() { return x; } public void setX(Object x) { this.x = x; } public Object getY() { return y; } public void setY(Object y) { this.y = y; } }
上面的代码中,生成坐标时不会有任何问题,但是取出坐标时,要向下转型,在 Java多态对象的类型转换 一文中我们讲到,向下转型存在着风险,而且编译期间不容易发现,只有在运行期间才会抛出异常,所以要尽量避免使用向下转型。运行上面的代码,第12行会抛出 java.lang.ClassCastException 异常。
那么,有没有更好的办法,既可以不使用重载(有重复代码),又能把风险降到最低呢?
有,可以使用泛型类(Java Class),它可以接受任意类型的数据。所谓“泛型”,就是“宽泛的数据类型”,任意的数据类型。
更改上面的代码,使用泛型类:
public class Demo { public static void main(String[] args){ // 实例化泛型类 Point<Integer, Integer> p1 = new Point<Integer, Integer>(); //指出类型 p1.setX(10); p1.setY(20); int x = p1.getX(); int y = p1.getY(); System.out.println("This point is:" + x + ", " + y); Point<Double, String> p2 = new Point<Double, String>(); p2.setX(25.4); p2.setY("东京180度"); double m = p2.getX(); String n = p2.getY(); System.out.println("This point is:" + m + ", " + n); } } // 定义泛型类 class Point<T1, T2>{ T1 x; T2 y; public T1 getX() { return x; } public void setX(T1 x) { this.x = x; } public T2 getY() { return y; } public void setY(T2 y) { this.y = y; } }
运行结果:
This point is:10, 20
This point is:25.4, 东京180度
与普通类的定义相比,上面的代码在类名后面多出了 <T1, T2>,T1, T2 是自定义的标识符,也是参数,用来传递数据的类型,而不是数据的值,我们称之为类型参数。在泛型中,不但数据的值可以通过参数传递,数据的类型也可以通过参数传递。T1, T2 只是数据类型的占位符,运行时会被替换为真正的数据类型。
传值参数(我们通常所说的参数)由小括号包围,如 (int x, double y),类型参数(泛型参数)由尖括号包围,多个参数由逗号分隔,如 <T> 或 <T, E>。
类型参数需要在类名后面给出。一旦给出了类型参数,就可以在类中使用了。类型参数必须是一个合法的标识符,习惯上使用单个大写字母,通常情况下,K 表示键,V 表示值,E 表示异常或错误,T 表示一般意义上的数据类型(这些都是泛类型能用的)。
泛型类在实例化时必须指出具体的类型,也就是向类型参数传值,格式为:
className variable<dataType1, dataType2> = new className<dataType1, dataType2>();
也可以省略等号右边的数据类型,但是会产生警告,即:
className variable<dataType1, dataType2> = new className();
因为在使用泛型类时指明了数据类型,赋给其他类型的值会抛出异常,既不需要向下转型,也没有潜在的风险,比本文一开始介绍的自动装箱和向上转型要更加实用。
注意:
- 泛型是 Java 1.5 的新增特性,它以C++模板为参照,本质是参数化类型(Parameterized Type)的应用。
- 类型参数只能用来表示引用类型,不能用来表示基本类型,如 int、double、char 等。但是传递基本类型不会报错,因为它们会自动装箱成对应的包装类。
泛型方法
除了定义泛型类,还可以定义泛型方法,例如,定义一个打印坐标的泛型方法:
public class Demo { public static void main(String[] args){ // 实例化泛型类 Point<Integer, Integer> p1 = new Point<Integer, Integer>(); p1.setX(10); p1.setY(20); p1.printPoint(p1.getX(), p1.getY()); Point<Double, String> p2 = new Point<Double, String>(); p2.setX(25.4); p2.setY("东京180度"); p2.printPoint(p2.getX(), p2.getY()); } } // 定义泛型类 class Point<T1, T2>{ T1 x; T2 y; public T1 getX() { return x; } public void setX(T1 x) { this.x = x; } public T2 getY() { return y; } public void setY(T2 y) { this.y = y; } // 定义泛型方法 public <T1, T2> void printPoint(T1 x, T2 y){ T1 m = x; T2 n = y; System.out.println("This point is:" + m + ", " + n); } }
运行结果:
This point is:10, 20
This point is:25.4, 东京180度
上面的代码中定义了一个泛型方法 printPoint(),既有普通参数,也有类型参数,类型参数需要放在修饰符后面、返回值类型前面。一旦定义了类型参数,就可以在参数列表、方法体和返回值类型中使用了。
与使用泛型类不同,使用泛型方法时不必指明参数类型,编译器会根据传递的参数自动查找出具体的类型。泛型方法除了定义不同,调用就像普通方法一样。
注意:泛型方法与泛型类没有必然的联系,泛型方法有自己的类型参数,在普通类中也可以定义泛型方法。泛型方法 printPoint() 中的类型参数 T1, T2 与泛型类 Point 中的 T1, T2 没有必然的联系,也可以使用其他的标识符代替:
public static <V1, V2> void printPoint(V1 x, V2 y){ V1 m = x; V2 n = y; System.out.println("This point is:" + m + ", " + n); }
泛型接口
在Java中也可以定义泛型接口,这里不再赘述,仅仅给出示例代码:
public class Demo { public static void main(String arsg[]) { Info<String> obj = new InfoImp<String>("www.weixueyuan.net"); System.out.println("Length Of String: " + obj.getVar().length()); } } //定义泛型接口 interface Info<T> { public T getVar(); } //实现接口 class InfoImp<T> implements Info<T> { private T var; // 定义泛型构造方法 public InfoImp(T var) { this.setVar(var); } public void setVar(T var) { this.var = var; } public T getVar() { return this.var; } }
运行结果:
Length Of String: 18
类型擦除
如果在使用泛型时没有指明数据类型,那么就会擦除泛型类型,请看下面的代码:
public class Demo { public static void main(String[] args){ Point p = new Point(); // 类型擦除 并没有指明类型 p.setX(10); p.setY(20.8); int x = (Integer)p.getX(); // 向下转型 double y = (Double)p.getY(); System.out.println("This point is:" + x + ", " + y); } } class Point<T1, T2>{ T1 x; T2 y; public T1 getX() { return x; } public void setX(T1 x) { this.x = x; } public T2 getY() { return y; } public void setY(T2 y) { this.y = y; } }
运行结果:
This point is:10, 20.8
因为在使用泛型时没有指明数据类型,为了不出现错误,编译器会将所有数据向上转型为 Object,所以在取出坐标使用时要向下转型,这与本文一开始不使用泛型没什么两样。
限制泛型的可用类型
在上面的代码中,类型参数可以接受任意的数据类型,只要它是被定义过的。但是,很多时候我们只需要一部分数据类型就够了,用户传递其他数据类型可能会引起错误。例如,编写一个泛型函数用于返回不同类型数组(Integer 数组、Double 数组、Character 数组等)中的最大值:
public <T> T getMax(T array[]){ T max = null; for(T element : array){ max = element.doubleValue() > max.doubleValue() ? element : max; } return max; }
上面的代码会报错,doubleValue() 是 Number 类的方法,不是所有的类都有该方法,所以我们要限制类型参数 T,让它只能接受 Number 及其子类(Integer、Double、Character 等)。
通过 extends 关键字可以限制泛型的类型,改进上面的代码:
public <T extends Number> T getMax(T array[]){ T max = null; for(T element : array){ max = element.doubleValue() > max.doubleValue() ? element : max; } return max; }
<T extends Number> 表示 T 只接受 Number 及其子类,传入其他类型的数据会报错。这里的限定使用关键字 extends,后面可以是类也可以是接口。但这里的 extends 已经不是继承的含义了,应该理解为 T 是继承自 Number 类的类型,或者 T 是实现了 XX 接口的类型。
注意:一般的应用开发中泛型使用较少,多用在框架或者库的设计中,这里不再深入讲解,主要让大家对泛型有所认识,为后面的教程做铺垫。
5.7 java泛型通配符合类型参数的范围
通配符(?)
上一节的例子中提到要定义一个泛型类来表示坐标,坐标可以是整数、小数或字符串,请看下面的代码:
class Point<T1, T2>{ T1 x; T2 y; public T1 getX() { return x; } public void setX(T1 x) { this.x = x; } public T2 getY() { return y; } public void setY(T2 y) { this.y = y; } }
现在要求在类的外部定义一个 printPoint() 方法用于输出坐标,怎么办呢?
可以这样来定义方法:
public void printPoint(Point p){ System.out.println("This point is: " + p.getX() + ", " + p.getY()); }
我们知道,如果在使用泛型时没有指名具体的数据类型,就会擦除泛型类型,并向上转型为 Object,这与不使用泛型没什么两样。上面的代码没有指明数据类型,相当于:
public void printPoint(Point<Object, Object> p){ System.out.println("This point is: " + p.getX() + ", " + p.getY()); }
为了避免类型擦除,可以使用通配符(?):
public void printPoint(Point<?, ?> p){ System.out.println("This point is: " + p.getX() + ", " + p.getY()); }
通配符(?)可以表示任意的数据类型。将代码补充完整:
public class Demo { public static void main(String[] args){ Point<Integer, Integer> p1 = new Point<Integer, Integer>(); p1.setX(10); p1.setY(20); printPoint(p1); Point<String, String> p2 = new Point<String, String>(); p2.setX("东京180度"); p2.setY("北纬210度"); printPoint(p2); } public static void printPoint(Point<?, ?> p){ // 使用通配符 //请注意使用的位置,在main之后 , Demo之内; System.out.println("This point is: " + p.getX() + ", " + p.getY()); } } class Point<T1, T2>{ T1 x; T2 y; public T1 getX() { return x; } public void setX(T1 x) { this.x = x; } public T2 getY() { return y; } public void setY(T2 y) { this.y = y; } }
运行结果:
This point is: 10, 20
This point is: 东京180度, 北纬210度
但是,数字坐标与字符串坐标又有区别:数字可以表示x轴或y轴的坐标,字符串可以表示地球经纬度。现在又要求定义两个方法分别处理不同的坐标,一个方法只能接受数字类型的坐标,另一个方法只能接受字符串类型的坐标,怎么办呢?
这个问题的关键是要限制类型参数的范围,请先看下面的代码:
public class Demo { public static void main(String[] args){ Point<Integer, Integer> p1 = new Point<Integer, Integer>(); p1.setX(10); p1.setY(20); printNumPoint(p1); Point<String, String> p2 = new Point<String, String>(); p2.setX("东京180度"); p2.setY("北纬210度"); printStrPoint(p2); } // 借助通配符限制泛型的范围 public static void printNumPoint(Point<? extends Number, ? extends Number> p){ System.out.println("x: " + p.getX() + ", y: " + p.getY()); } public static void printStrPoint(Point<? extends String, ? extends String> p){ System.out.println("GPS: " + p.getX() + "," + p.getY()); } } class Point<T1, T2>{ T1 x; T2 y; public T1 getX() { return x; } public void setX(T1 x) { this.x = x; } public T2 getY() { return y; } public void setY(T2 y) { this.y = y; } }
运行结果:
x: 10, y: 20
GPS: 东京180度,北纬210度
? extends Number 表示泛型的类型参数只能是 Number 及其子类,? extends String 也一样,这与定义泛型类或泛型方法时限制类型参数的范围类似。
不过,使用通配符(?)不但可以限制类型的上限,还可以限制下限。限制下限使用 super 关键字,例如 <? super Number> 表示只能接受 Number 及其父类。
注意:一般的项目中很少会去设计泛型,这里主要是让读者学会如何使用,为后面的教程做铺垫。
六◐ java异常处理
6.1 异常处理基础
Java异常是一个描述在代码段中发生的异常(也就是出错)情况的对象。当异常情况发生,一个代表该异常的对象被创建并且在导致该错误的方法中被抛出(throw)。该方法可以选择自己处理异常或传递该异常。两种情况下,该异常被捕获(caught)并处理。异常可能是由Java运行时系统产生,或者是由你的手工代码产生。被Java抛出的异常与违反语言规范或超出Java执行环境限制的基本错误有关。手工编码产生的异常基本上用于报告方法调用程序的出错状况。
Java异常处理通过5个关键字控制:try、catch、throw、throws和 finally。下面讲述它们如何工作的。程序声明了你想要的异常监控包含在一个try块中。如果在try块中发生异常,它被抛出。你的代码可以捕捉这个异常(用catch)并且用某种合理的方法处理该异常。系统产生的异常被Java运行时系统自动抛出。手动抛出一个异常,用关键字throw。任何被抛出方法的异常都必须通过throws子句定义。任何在方法返回前绝对被执行的代码被放置在finally块中。
下面是一个异常处理块的通常形式:
try { // block of code to monitor for errors } catch (ExceptionType1 exOb) { // exception handler for ExceptionType1 } catch (ExceptionType2 exOb) { // exception handler for ExceptionType2 } // ... finally { // block of code to be executed before try block ends }
这里,ExceptionType 是发生异常的类型。下面将介绍怎样应用这个框架。
6.2 异常类型
所有异常类型都是内置类Throwable的子类。因此,Throwable在异常类层次结构的顶层。紧接着Throwable下面的是两个把异常分成两个不同分支的子类。一个分支是Exception。
该类用于用户程序可能捕捉的异常情况。它也是你可以用来创建你自己用户异常类型子类的类。在Exception分支中有一个重要子类RuntimeException。该类型的异常自动为你所编写的程序定义并且包括被零除和非法数组索引这样的错误。
另一类分支由Error作为顶层,Error定义了在通常环境下不希望被程序捕获的异常。Error类型的异常用于Java运行时系统来显示与运行时系统本身有关的错误。堆栈溢出是这种错误的一例。本章将不讨论关于Error类型的异常处理,因为它们通常是灾难性的致命错误,不是你的程序可以控制的。
6.3 Java未被捕获的异常
在你学习在程序中处理异常之前,看一看如果你不处理它们会有什么情况发生是很有好处的。下面的小程序包括一个故意导致被零除错误的表达式。
class Exc0 { public static void main(String args[]) { int d = 0; int a = 42 / d; } }
当Java运行时系统检查到被零除的情况,它构造一个新的异常对象然后抛出该异常。这导致Exc0的执行停止,因为一旦一个异常被抛出,它必须被一个异常处理程序捕获并且被立即处理。该例中,我们没有提供任何我们自己的异常处理程序,所以异常被Java运行时系统的默认处理程序捕获。任何不是被你程序捕获的异常最终都会被该默认处理程序处理。默认处理程序显示一个描述异常的字符串,打印异常发生处的堆栈轨迹并且终止程序。
下面是由标准javaJDK运行时解释器执行该程序所产生的输出:
java.lang.ArithmeticException: / by zero
at Exc0.main(Exc0.java:4)
注意,类名Exc0,方法名main,文件名Exc0.java和行数4是怎样被包括在一个简单的堆栈使用轨迹中的。还有,注意抛出的异常类型是Exception的一个名为ArithmeticException的子类,该子类更明确的描述了何种类型的错误方法。本章后面部分将讨论,Java提供多个内置的与可能产生的不同种类运行时错误相匹配的异常类型。
堆栈轨迹将显示导致错误产生的方法调用序列。例如,下面是前面程序的另一个版本,它介绍了相同的错误,但是错误是在main( )方法之外的另一个方法中产生的:
class Exc1 { static void subroutine() { int d = 0; int a = 10 / d; } public static void main(String args[]) { Exc1.subroutine(); } }
默认异常处理器的堆栈轨迹结果表明了整个调用栈是怎样显示的:
java.lang.ArithmeticException: / by zero at Exc1.subroutine(Exc1.java:4) at Exc1.main(Exc1.java:7)
如你所见,栈底是main的第7行,该行调用了subroutine( )方法。该方法在第4行导致了异常。调用堆栈对于调试来说是很重要的,因为它查明了导致错误的精确的步骤。
6.4 java try和catch的使用
尽管由Java运行时系统提供的默认异常处理程序对于调试是很有用的,但通常你希望自己处理异常。这样做有两个好处。第一,它允许你修正错误。第二,它防止程序自动终止。大多数用户对于在程序终止运行和在无论何时错误发生都会打印堆栈轨迹感到很烦恼(至少可以这么说)。幸运的是,这很容易避免。
为防止和处理一个运行时错误,只需要把你所要监控的代码放进一个try块就可以了。紧跟着try块的,包括一个说明你希望捕获的错误类型的catch子句。完成这个任务很简单,下面的程序包含一个处理因为被零除而产生的ArithmeticException 异常的try块和一个catch子句。
class Exc2 { public static void main(String args[]) { int d, a; try { // monitor a block of code. d = 0; a = 42 / d; System.out.println("This will not be printed."); } catch (ArithmeticException e) { // catch divide-by-zero error System.out.println("Division by zero."); } System.out.println("After catch statement."); } }
该程序输出如下:
Division by zero.
After catch statement.
注意在try块中的对println( )的调用是永远不会执行的。一旦异常被引发,程序控制由try块转到catch块。执行永远不会从catch块“返回”到try块。因此,“This will not be printed。”
将不会被显示。一旦执行了catch语句,程序控制从整个try/catch机制的下面一行继续。
一个try和它的catch语句形成了一个单元。catch子句的范围限制于try语句前面所定义的语句。一个catch语句不能捕获另一个try声明所引发的异常(除非是嵌套的try语句情况)。
被try保护的语句声明必须在一个大括号之内(也就是说,它们必须在一个块中)。你不能单独使用try。
构造catch子句的目的是解决异常情况并且像错误没有发生一样继续运行。例如,下面的程序中,每一个for循环的反复得到两个随机整数。这两个整数分别被对方除,结果用来除12345。最后的结果存在a中。如果一个除法操作导致被零除错误,它将被捕获,a的值设为零,程序继续运行。
// Handle an exception and move on. import java.util.Random; class HandleError { public static void main(String args[]) { int a=0, b=0, c=0; Random r = new Random(); for(int i=0; i<32000; i++) { try { b = r.nextInt(); c = r.nextInt(); a = 12345 / (b/c); } catch (ArithmeticException e) { System.out.println("Division by zero."); a = 0; // set a to zero and continue } System.out.println("a: " + a); } } }
显示一个异常的描述
Throwable重载toString( )方法(由Object定义),所以它返回一个包含异常描述的字符串。你可以通过在println( )中传给异常一个参数来显示该异常的描述。例如,前面程序的catch块可以被重写成
catch (ArithmeticException e) { System.out.println("Exception: " + e); a = 0; // set a to zero and continue }
当这个版本代替原程序中的版本,程序在标准javaJDK解释器下运行,每一个被零除错误显示下面的消息:
Exception: java.lang.ArithmeticException: / by zero
尽管在上下文中没有特殊的值,显示一个异常描述的能力在其他情况下是很有价值的——特别是当你对异常进行实验和调试时。
6.5 多重catch语句的使用
某些情况,由单个代码段可能引起多个异常。处理这种情况,你可以定义两个或更多的catch子句,每个子句捕获一种类型的异常。当异常被引发时,每一个catch子句被依次检查,第一个匹配异常类型的子句执行。当一个catch语句执行以后,其他的子句被旁路,执行从try/catch块以后的代码开始继续。下面的例子设计了两种不同的异常类型:
// Demonstrate multiple catch statements. class MultiCatch { public static void main(String args[]) { try { int a = args.length; System.out.println("a = " + a); int b = 42 / a; int c[] = { 1 }; c[42] = 99; } catch(ArithmeticException e) { System.out.println("Divide by 0: " + e); } catch(ArrayIndexOutOfBoundsException e) { System.out.println("Array index oob: " + e); } System.out.println("After try/catch blocks."); } }
ArithmeticException 和 ArrayIndexOutOfBoundsException 与之同类的还有那些,分别是什么作用???
该程序在没有命令行参数的起始条件下运行导致被零除异常,因为a为0。如果你提供一个命令行参数,它将幸免于难,把a设成大于零的数值。但是它将导致ArrayIndexOutOf BoundsException异常,因为整型数组c的长度为1,而程序试图给c[42]赋值。
下面是运行在两种不同情况下程序的输出:
C:\>java MultiCatch a = 0 Divide by 0: java.lang.ArithmeticException: / by zero After try/catch blocks. C:\>java MultiCatch TestArg a = 1 Array index oob: java.lang.ArrayIndexOutOfBoundsException After try/catch blocks.
当你用多catch语句时,记住异常子类必须在它们任何父类之前使用是很重要的。这是因为运用父类的catch语句将捕获该类型及其所有子类类型的异常。这样,如果子类在父类后面,子类将永远不会到达。而且,Java中不能到达的代码是一个错误。例如,考虑下面的程序:
/* This program contains an error. A subclass must come before its superclass in a series of catch statements. If not,unreachable code will be created and acompile-time error will result. */ class SuperSubCatch { public static void main(String args[]) { try { int a = 0; int b = 42 / a; } catch(Exception e) { System.out.println("Generic Exception catch."); } /* This catch is never reached because ArithmeticException is a subclass of Exception. */ catch(ArithmeticException e) { // ERROR - unreachable System.out.println("This is never reached."); } } }
如果你试着编译该程序,你会收到一个错误消息,该错误消息说明第二个catch语句不会到达,因为该异常已经被捕获。因为ArithmeticException 是Exception的子类,第一个catch语句将处理所有的面向Exception的错误,包括ArithmeticException。这意味着第二个catch语句永远不会执行。为修改程序,颠倒两个catch语句的次序。
6.6 java中try语句的嵌套
Try语句可以被嵌套。也就是说,一个try语句可以在另一个try块内部。每次进入try语句,异常的前后关系都会被推入堆栈。如果一个内部的try语句不含特殊异常的catch处理程序,堆栈将弹出,下一个try语句的catch处理程序将检查是否与之匹配。这个过程将继续直到一个catch语句匹配成功,或者是直到所有的嵌套try语句被检查耗尽。如果没有catch语句匹配,Java的运行时系统将处理这个异常。下面是运用嵌套try语句的一个例子:
// An example of nested try statements. class NestTry { public static void main(String args[]) { try { int a = args.length; /* If no command-line args are present,the following statement will generate a divide-by-zero exception. */ int b = 42 / a; System.out.println("a = " + a); try { // nested try block /* If one command-line arg is used,then a divide-by-zero exception will be generated by the following code. */ if(a==1) a = a/(a-a); // division by zero /* If two command-line args are used,then generate an out-of-bounds exception. */ if(a==2) { int c[] = { 1 }; c[42] = 99; // generate an out-of-bounds exception } } catch(ArrayIndexOutOfBoundsException e) { System.out.println("Array index out-of-bounds: " + e); } } catch(ArithmeticException e) { System.out.println("Divide by 0: " + e); } } }//当第一个if否认后,if中的语句还会执行吗? 还是直接跳出????
如你所见,该程序在一个try块中嵌套了另一个try块。程序工作如下:当你在没有命令行参数的情况下执行该程序,外面的try块将产生一个被零除的异常。程序在有一个命令行参数条件下执行,由嵌套的try块产生一个被零除的错误。因为内部的块不匹配这个异常,它将把异常传给外部的try块,在那里异常被处理。如果你在具有两个命令行参数的条件下执行该程序,由内部try块产生一个数组边界异常。下面的结果阐述了每一种情况:
C:\>java NestTry Divide by 0: java.lang.ArithmeticException: / by zero C:\>java NestTry One a = 1 Divide by 0: java.lang.ArithmeticException: / by zero C:\>java NestTry One Two a = 2 Array index out-of-bounds: java.lang.ArrayIndexOutOfBoundsException
当有方法调用时,try语句的嵌套可以很隐蔽的发生。例如,你可以把对方法的调用放在一个try块中。在该方法内部,有另一个try语句。这种情况下,方法内部的try仍然是嵌套在外部调用该方法的try块中的。下面是前面例子的修改,嵌套的try块移到了方法nesttry( )的内部:
/* Try statements can be implicitly nested via calls to methods. */ class MethNestTry { static void nesttry(int a) { try { // nested try block /* If one command-line arg is used,then a divide-by-zero exception will be generated by the following code. */ if(a==1) a = a/(a-a); // division by zero /* If two command-line args are used,then generate an out-of-bounds exception. */ if(a==2) { int c[] = { 1 }; c[42] = 99; // generate an out-of-bounds exception } } catch(ArrayIndexOutOfBoundsException e) { System.out.println("Array index out-of-bounds: " + e); } } public static void main(String args[]) { try { int a = args.length; /* If no command-line args are present,the following statement will generate a divide-by-zero exception. */ int b = 42 / a; System.out.println("a = " + a); nesttry(a); } catch(ArithmeticException e) { System.out.println("Divide by 0: " + e); } } }
该程序的输出与前面的例子相同。
6.7 java throw:异常的抛出
到目前为止,你只是获取了被Java运行时系统抛出的异常。然而,程序可以用throw语句抛出明确的异常。Throw语句的通常形式如下:
throw ThrowableInstance;
这里,ThrowableInstance一定是Throwable类类型或Throwable子类类型的一个对象。简单类型,例如int或char,以及非Throwable类,例如String或Object,不能用作异常。有两种可以获得Throwable对象的方法:在catch子句中使用参数或者用new操作符创建。
程序执行在throw语句之后立即停止;后面的任何语句不被执行。最紧紧包围的try块用来检查它是否含有一个与异常类型匹配的catch语句。如果发现了匹配的块,控制转向该语句;如果没有发现,次包围的try块来检查,以此类推。如果没有发现匹配的catch块,默认异常处理程序中断程序的执行并且打印堆栈轨迹。
下面是一个创建并抛出异常的例子程序,与异常匹配的处理程序再把它抛出给外层的处理程序。
// Demonstrate throw. class ThrowDemo { static void demoproc() { try { throw new NullPointerException("demo"); } catch(NullPointerException e) { System.out.println("Caught inside demoproc."); throw e; // rethrow the exception } } public static void main(String args[]) { try { demoproc(); } catch(NullPointerException e) { System.out.println("Recaught: " + e); } } }
该程序有两个机会处理相同的错误。首先,main()设立了一个异常关系然后调用demoproc( )。 demoproc( )方法然后设立了另一个异常处理关系并且立即抛出一个新的NullPointerException实例,NullPointerException在下一行被捕获。异常于是被再次抛出。下面是输出结果:
Caught inside demoproc.
Recaught: java.lang.NullPointerException: demo
该程序还阐述了怎样创建Java的标准异常对象,特别注意下面这一行:
throw new NullPointerException("demo");
这里,new用来构造一个NullPointerException实例。所有的Java内置的运行时异常有两个构造函数:一个没有参数,一个带有一个字符串参数。当用到第二种形式时,参数指定描述异常的字符串。如果对象用作 print( )或println( )的参数时,该字符串被显示。这同样可以通过调用getMessage( )来实现,getMessage( )是由Throwable定义的。
6.8 java throws子句
如果一个方法可以导致一个异常但不处理它,它必须指定这种行为以使方法的调用者可以保护它们自己而不发生异常。做到这点你可以在方法声明中包含一个throws子句。一个 throws 子句列举了一个方法可能抛出的所有异常类型。这对于除Error或RuntimeException及它们子类以外类型的所有异常是必要的。一个方法可以抛出的所有其他类型的异常必须在throws子句中声明。如果不这样做,将会导致编译错误。
下面是包含一个throws子句的方法声明的通用形式:
type method-name(parameter-list) throws exception-list{ // body of method }
这里,exception-list是该方法可以抛出的以有逗号分割的异常列表。
下面是一个不正确的例子。该例试图抛出一个它不能捕获的异常。因为程序没有指定一个throws子句来声明这一事实,程序将不会编译。
// This program contains an error and will not compile. class ThrowsDemo { static void throwOne() { System.out.println("Inside throwOne."); throw new IllegalAccessException("demo"); } public static void main(String args[]) { throwOne(); } } 错误的!
为编译该程序,需要改变两个地方。第一,需要声明throwOne( )引发IllegalAccess Exception异常。第二,main( )必须定义一个try/catch 语句来捕获该异常。正确的例子如下:
// This is now correct. class ThrowsDemo { static void throwOne() throws IllegalAccessException { System.out.println("Inside throwOne."); throw new IllegalAccessException("demo"); } public static void main(String args[]) { try { throwOne(); } catch (IllegalAccessException e) { System.out.println("Caught " + e); } } }
下面是例题的输出结果:
inside throwOne
caught java.lang.IllegalAccessException: demo
6.9 java finally
当异常被抛出,通常方法的执行将作一个陡峭的非线性的转向。依赖于方法是怎样编码的,异常甚至可以导致方法过早返回。这在一些方法中是一个问题。例如,如果一个方法打开一个文件项并关闭,然后退出,你不希望关闭文件的代码被异常处理机制旁路。finally关键字为处理这种意外而设计。
finally创建一个代码块。该代码块在一个try/catch 块完成之后另一个try/catch出现之前执行。finally块无论有没有异常抛出都会执行。如果异常被抛出,finally甚至是在没有与该异常相匹配的catch子句情况下也将执行。一个方法将从一个try/catch块返回到调用程序的任何时候,经过一个未捕获的异常或者是一个明确的返回语句,finally子句在方法返回之前仍将执行。这在关闭文件句柄和释放任何在方法开始时被分配的其他资源是很有用的。finally子句是可选项,可以有也可以无。然而每一个try语句至少需要一个catch或finally子句。
下面的例子显示了3种不同的退出方法。每一个都执行了finally子句:
// Demonstrate finally. class FinallyDemo { // Through an exception out of the method. static void procA() { try { System.out.println("inside procA"); throw new RuntimeException("demo"); } finally { System.out.println("procA's finally"); } } // Return from within a try block. static void procB() { try { System.out.println("inside procB"); return; } finally { System.out.println("procB's finally"); } } // Execute a try block normally. static void procC() { try { System.out.println("inside procC"); } finally { System.out.println("procC's finally"); } } public static void main(String args[]) { try { procA(); } catch (Exception e) { System.out.println("Exception caught"); } procB(); procC(); } }
该例中,procA( )过早地通过抛出一个异常中断了try。Finally子句在退出时执行。procB( )的try语句通过一个return语句退出。在procB( )返回之前finally子句执行。在procC()中,try语句正常执行,没有错误。然而,finally块仍将执行。
注意:如果finally块与一个try联合使用,finally块将在try结束之前执行。
下面是上述程序产生的输出:
inside procA
procA’s finally
Exception caught
inside procB
procB’s finally
inside procC
procC’s finally
6.10 java的内置异常
在标准包java.lang中,Java定义了若干个异常类。前面的例子曾用到其中一些。这些异常一般是标准类RuntimeException的子类。因为java.lang实际上被所有的Java程序引入,多数从RuntimeException派生的异常都自动可用。而且,它们不需要被包含在任何方法的throws列表中。Java语言中,这被叫做未经检查的异常(unchecked exceptions )。因为编译器不检查它来看一个方法是否处理或抛出了这些异常。 java.lang中定义的未经检查的异常列于表10-1。表10-2列出了由 java.lang定义的必须在方法的throws列表中包括的异常,如果这些方法能产生其中的某个异常但是不能自己处理它。这些叫做受检查的异常(checked exceptions)。Java定义了几种与不同类库相关的其他的异常类型。
| 异常 | 说明 |
|---|---|
| ArithmeticException | 算术错误,如被0除 |
| ArrayIndexOutOfBoundsException | 数组下标出界 |
| ArrayStoreException | 数组元素赋值类型不兼容 |
| ClassCastException | 非法强制转换类型 |
| IllegalArgumentException | 调用方法的参数非法 |
| IllegalMonitorStateException | 非法监控操作,如等待一个未锁定线程 |
| IllegalStateException | 环境或应用状态不正确 |
| IllegalThreadStateException | 请求操作与当前线程状态不兼容 |
| IndexOutOfBoundsException | 某些类型索引越界 |
| NullPointerException | 非法使用空引用 |
| NumberFormatException | 字符串到数字格式非法转换 |
| SecurityException | 试图违反安全性 |
| StringIndexOutOfBounds | 试图在字符串边界之外索引 |
| UnsupportedOperationException | 遇到不支持的操作 |
| 异常 | 意义 |
|---|---|
| ClassNotFoundException | 找不到类 |
| CloneNotSupportedException | 试图克隆一个不能实现Cloneable接口的对象 |
| IllegalAccessException | 对一个类的访问被拒绝 |
| InstantiationException | 试图创建一个抽象类或者抽象接口的对象 |
| InterruptedException | 一个线程被另一个线程中断 |
| NoSuchFieldException | 请求的字段不存在 |
| NoSuchMethodException | 请求的方法不存在 |
6.11 使用Java创建自己的异常子类
尽管Java的内置异常处理大多数常见错误,你也许希望建立你自己的异常类型来处理你所应用的特殊情况。这是非常简单的:只要定义Exception的一个子类就可以了(Exception当然是Throwable的一个子类)。你的子类不需要实际执行什么——它们在类型系统中的存在允许你把它们当成异常使用。
Exception类自己没有定义任何方法。当然,它继承了Throwable提供的一些方法。因此,所有异常,包括你创建的,都可以获得Throwable定义的方法。这些方法显示在表10-3中。你还可以在你创建的异常类中覆盖一个或多个这样的方法。
| 方法 | 描述 |
|---|---|
| Throwable fillInStackTrace( ) | 返回一个包含完整堆栈轨迹的Throwable对象,该对象可能被再次引发。 |
| String getLocalizedMessage( ) | 返回一个异常的局部描述 |
| String getMessage( ) | 返回一个异常的描述 |
| void printStackTrace( ) | 显示堆栈轨迹 |
| void printStackTrace(PrintStreamstream) | 把堆栈轨迹送到指定的流 |
| void printStackTrace(PrintWriterstream) | 把堆栈轨迹送到指定的流 |
| String toString( ) | 返回一个包含异常描述的String对象。当输出一个Throwable对象时,该方法被println( )调用 |
下面的例子声明了Exception的一个新子类,然后该子类当作方法中出错情形的信号。它重载了toString( )方法,这样可以用println( )显示异常的描述。
// This program creates a custom exception type. class MyException extends Exception { private int detail; MyException(int a) { detail = a; } public String toString() { return "MyException[" + detail + "]"; } } class ExceptionDemo { static void compute(int a) throws MyException { System.out.println("Called compute(" + a + ")"); if(a > 10) throw new MyException(a); System.out.println("Normal exit"); } public static void main(String args[]) { try { compute(1); compute(20); } catch (MyException e) { System.out.println("Caught " + e); } } }
该例题定义了Exception的一个子类MyException。该子类非常简单:它只含有一个构造函数和一个重载的显示异常值的toString( )方法。ExceptionDemo类定义了一个compute( )方法。该方法抛出一个MyException对象。当compute( )的整型参数比10大时该异常被引发。
main( )方法为MyException设立了一个异常处理程序,然后用一个合法的值和不合法的值调用compute( )来显示执行经过代码的不同路径。下面是结果:
Called compute(1)
Normal exit
Called compute(20)
Caught MyException[20]
6.12 java断言
断言的概念
断言用于证明和测试程序的假设,比如“这里的值大于 5”。
断言可以在运行时从代码中完全删除,所以对代码的运行速度没有影响。
断言的使用
断言有两种方法:
- 一种是 assert<<布尔表达式>> ;
- 另一种是 assert<<布尔表达式>> :<<细节描述>>。
如果布尔表达式的值为false , 将抛出AssertionError 异常; 细节描述是AssertionError异常的描述文本使用 javac –source 1.4 MyClass.java 的方式进行编译示例如下:
public class AssertExample { public static void main(String[] args) { int x = 10; if (args.length > 0) { try { x = Integer.parseInt(args[0]); } catch (NumberFormatException nfe) { /* Ignore */ } } System.out.println("Testing assertion that x == 10"); assert x == 10 : "Our assertion failed"; System.out.println("Test passed"); } }
由于引入了一个新的关键字,所以在编译的时候就需要增加额外的参数,要编译成功,必须使用 JDK1.4 的 javac 并加上参数'-source 1.4',例如可以使用以下的命令编译上面的代码:
javac -source 1.4 AssertExample.java
以上程序运行使用断言功能也需要使用额外的参数(并且需要一个数字的命令行参数),例如:
java -ea AssertExample 1
程序的输出为:
Testing assertion that x == 10
Exception in thread "main" java.lang.AssertionError:Our assertion failed
at AssertExample.main(AssertExample.java:20)
由于输入的参数不等于 10,因此断言功能使得程序运行时抛出断言错误,注意是错误, 这意味着程序发生严重错误并且将强制退出。断言使用 boolean 值,如果其值不为 true 则 抛出 AssertionError 并终止程序的运行。
断言推荐使用方法
用于验证方法中的内部逻辑,包括:
- 内在不变式
- 控制流程不变式
- 后置条件和类不变式
注意:不推荐用于公有方法内的前置条件的检查。
运行时屏蔽断言
运行时要屏蔽断言,可以用如下方法:
java –disableassertions 或 java –da 类名
运行时要允许断言,可以用如下方法:
java –enableassertions 或 java –ea类名
七◐ java多线程编程
7.1 java线程的概念
和其他多数计算机语言不同,Java内置支持多线程编程(multithreaded programming)。(这应该是JVM的功劳)
多线程程序包含两条或两条以上并发运行的部分。程序中每个这样的部分都叫一个线程(thread),每个线程都有独立的执行路径。因此,多线程是多任务处理的一种特殊形式。
你一定知道多任务处理,因为它实际上被所有的现代操作系统所支持。然而,多任务处理有两种截然不同的类型:基于进程的和基于线程的。认识两者的不同是十分重要的。
对很多读者,基于进程的多任务处理是更熟悉的形式。进程(process)本质上是一个执行的程序。因此,基于进程(process-based) 的多任务处理的特点是允许你的计算机同时运行两个或更多的程序。举例来说,基于进程的多任务处理使你在运用文本编辑器的时候可以同时运行Java编译器。在基于进程的多任务处理中,程序是调度程序所分派的最小代码单位。
在基于线程(thread-based) 的多任务处理环境中,线程是最小的执行单位。这意味着一个程序可以同时执行两个或者多个任务的功能。例如,一个文本编辑器可以在打印的同时格式化文本。所以,多进程程序处理“大图片”,而多线程程序处理细节问题。
多线程程序比多进程程序需要更少的管理费用。进程是重量级的任务,需要分配它们自己独立的地址空间。进程间通信是昂贵和受限的。进程间的转换也是很需要花费的。另一方面,线程是轻量级的选手。它们共享相同的地址空间并且共同分享同一个进程。线程间通信是便宜的,线程间的转换也是低成本的。当Java程序使用多进程任务处理环境时,多进程程序不受Java的控制,而多线程则受Java控制。
多线程帮助你写出CPU最大利用率的高效程序,因为空闲时间保持最低。这对Java运行的交互式的网络互连环境是至关重要的,因为空闲时间是公共的。举个例子来说,网络的数据传输速率远低于计算机处理能力,本地文件系统资源的读写速度远低于CPU的处理能力,当然,用户输入也比计算机慢很多。在传统的单线程环境中,你的程序必须等待每一个这样的任务完成以后才能执行下一步——尽管CPU有很多空闲时间。多线程使你能够获得并充分利用这些空闲时间。
如果你在Windows 98 或Windows 2000这样的操作系统下有编程经验,那么你已经熟悉了多线程。然而,Java管理线程使多线程处理尤其方便,因为很多细节对你来说是易于处理的。
7.2 java线程模型
为更好的理解多线程环境的优势可以将它与它的对照物相比较。单线程系统的处理途径是使用一种叫作轮询的事件循环方法。在该模型中,单线程控制在一无限循环中运行,轮询一个事件序列来决定下一步做什么。一旦轮询装置返回信号表明,已准备好读取网络文件,事件循环调度控制管理到适当的事件处理程序。直到事件处理程序返回,系统中没有其他事件发生。这就浪费了CPU时间。这导致了程序的一部分独占了系统,阻止了其他事件的执行。总的来说,单线程环境,当一个线程因为等待资源时阻塞(block,挂起执行),整个程序停止运行。
Java多线程的优点在于取消了主循环/轮询机制。一个线程可以暂停而不影响程序的其他部分。例如,当一个线程从网络读取数据或等待用户输入时产生的空闲时间可以被利用到其他地方。多线程允许活的循环在每一帧间隙中沉睡一秒而不暂停整个系统。在Java程序中出现线程阻塞,仅有一个线程暂停,其他线程继续运行。
线程存在于好几种状态。线程可以正在运行(running)。只要获得CPU时间它就可以运行。运行的线程可以被挂起(suspend),并临时中断它的执行。一个挂起的线程可以被恢复(resume,允许它从停止的地方继续运行。一个线程可以在等待资源时被阻塞(block)。
在任何时候,线程可以终止(terminate),这立即中断了它的运行。一旦终止,线程不能被恢复。
线程优先级
Java给每个线程安排优先级以决定与其他线程比较时该如何对待该线程。线程优先级是详细说明线程间优先关系的整数。作为绝对值,优先级是毫无意义的;当只有一个线程时,优先级高的线程并不比优先权低的线程运行的快。相反,线程的优先级是用来决定何时从一个运行的线程切换到另一个。这叫“上下文转换”(context switch)。决定上下文转换发生的规则很简单:- 线程可以自动放弃控制。在I/O未决定的情况下,睡眠或阻塞由明确的让步来完成。在这种假定下,所有其他的线程被检测,准备运行的最高优先级线程被授予CPU。
- 线程可以被高优先级的线程抢占。在这种情况下,低优先级线程不主动放弃,处理器只是被先占——无论它正在干什么——处理器被高优先级的线程占据。基本上,一旦高优先级线程要运行,它就执行。这叫做有优先权的多任务处理。
当两个相同优先级的线程竞争CPU周期时,情形有一点复杂。对于Windows98这样的操作系统,等优先级的线程是在循环模式下自动划分时间的。对于其他操作系统,例如Solaris 2.x,等优先级线程相对于它们的对等体自动放弃。如果不这样,其他的线程就不会运行。
警告:不同的操作系统下等优先级线程的上下文转换可能会产生错误。
同步性
因为多线程在你的程序中引入了一个异步行为,所以在你需要的时候必须有加强同步性的方法。举例来说,如果你希望两个线程相互通信并共享一个复杂的数据结构,例如链表序列,你需要某些方法来确保它们没有相互冲突。也就是说,你必须防止一个线程写入数据而另一个线程正在读取链表中的数据。为此目的,Java在进程间同步性的老模式基础上实行了另一种方法:管程(monitor)。管程是一种由C.A.R.Hoare首先定义的控制机制。你可以把管程想象成一个仅控制一个线程的小盒子。一旦线程进入管程,所有线程必须等待直到该线程退出了管程。用这种方法,管程可以用来防止共享的资源被多个线程操纵。
很多多线程系统把管程作为程序必须明确的引用和操作的对象。Java提供一个清晰的解决方案。没有“Monitor”类;相反,每个对象都拥有自己的隐式管程,当对象的同步方法被调用时管程自动载入。一旦一个线程包含在一个同步方法中,没有其他线程可以调用相同对象的同步方法。这就使你可以编写非常清晰和简洁的多线程代码,因为同步支持是语言内置的。
消息传递
在你把程序分成若干线程后,你就要定义各线程之间的联系。用大多数其他语言规划时,你必须依赖于操作系统来确立线程间通信。这样当然增加花费。然而,Java提供了多线程间谈话清洁的、低成本的途径——通过调用所有对象都有的预先确定的方法。Java的消息传递系统允许一个线程进入一个对象的一个同步方法,然后在那里等待,直到其他线程明确通知它出来。Thread 类和Runnable 接口
Java的多线程系统建立于Thread类,它的方法,它的共伴接口Runnable基础上。Thread类封装了线程的执行。既然你不能直接引用运行着的线程的状态,你要通过它的代理处理它,于是Thread 实例产生了。为创建一个新的线程,你的程序必须扩展Thread 或实现Runnable接口。Thread类定义了好几种方法来帮助管理线程。本章用到的方法如表11-1所示:
| 方法 | 意义 |
|---|---|
| getName | 获得线程名称 |
| getPriority | 获得线程优先级 |
| jsAlive | 判定线程是否仍在运行 |
| join | 等待一个线程终止 |
| run | 线程的入口点. |
| sleep | 在一段时间内挂起线程 |
| start | 通过调用运行方法来启动线程 |
到目前为止,本书所应用的例子都是用单线程的。本章剩余部分解释如何用Thread 和 Runnable 来创建、管理线程。让我们从所有Java程序都有的线程:主线程开始。
7.3 java主线程
urrentThread( )
该方法返回一个调用它的线程的引用。一旦你获得主线程的引用,你就可以像控制其他线程那样控制主线程。
让我们从复习下面例题开始:
// Controlling the main Thread. class CurrentThreadDemo { public static void main(String args[]) { Thread t = Thread.currentThread(); System.out.println("Current thread: " + t); // change the name of the thread t.setName("My Thread"); System.out.println("After name change: " + t); try { for(int n = 5; n > 0; n--) { System.out.println(n); Thread.sleep(1000); } } catch (InterruptedException e) { System.out.println("Main thread interrupted"); } } }
在本程序中,当前线程(自然是主线程)的引用通过调用currentThread()获得,该引用保存在局部变量t中。然后,程序显示了线程的信息。接着程序调用setName()改变线程的内部名称。线程信息又被显示。然后,一个循环数从5开始递减,每数一次暂停一秒。暂停是由sleep()方法来完成的。Sleep()语句明确规定延迟时间是1毫秒。注意循环外的try/catch块。
Thread类的sleep()方法可能引发一个InterruptedException异常。这种情形会在其他线程想要打搅沉睡线程时发生。本例只是打印了它是否被打断的消息。在实际的程序中,你必须灵活处理此类问题。下面是本程序的输出:
Current thread: Thread[main,5,main]
After name change: Thread[My Thread,5,main]
5
4
3
2
1
注意t作为语句println()中参数运用时输出的产生。该显示顺序:线程名称,优先级以及组的名称。默认情况下,主线程的名称是main。它的优先级是5,这也是默认值,main也是所属线程组的名称。一个线程组(thread group)是一种将线程作为一个整体集合的状态控制的数据结构。这个过程由专有的运行时环境来处理,在此就不赘述了。线程名改变后,t又被输出。这次,显示了新的线程名。
让我们更仔细的研究程序中Thread类定义的方法。sleep()方法按照毫秒级的时间指示使线程从被调用到挂起。它的通常形式如下:
static void sleep(long milliseconds) throws InterruptedException
挂起的时间被明确定义为毫秒。该方法可能引发InterruptedException异常。
sleep()方法还有第二种形式,显示如下,该方法允许你指定时间是以毫秒还是以纳秒为周期。
static void sleep(long milliseconds, int nanoseconds) throws InterruptedException
第二种形式仅当允许以纳秒为时间周期时可用。如上述程序所示,你可以用setName()设置线程名称,用getName()来获得线程名称(该过程在程序中没有体现)。这些方法都是Thread 类的成员,声明如下:
final void setName(String threadName) final String getName( )
这里,threadName 特指线程名称。
7.4 java创建线程(Runnable接口和Thread类)
- 实现Runnable 接口;
- 可以继承Thread类。
下面的两小节依次介绍了每一种方式。
实现Runnable接口
创建线程的最简单的方法就是创建一个实现Runnable 接口的类。Runnable抽象了一个执行代码单元。你可以通过实现Runnable接口的方法创建每一个对象的线程。为实现Runnable 接口,一个类仅需实现一个run()的简单方法,该方法声明如下:public void run( )
在run()中可以定义代码来构建新的线程。理解下面内容是至关重要的:run()方法能够像主线程那样调用其他方法,引用其他类,声明变量。仅有的不同是run()在程序中确立另一个并发的线程执行入口。当run()返回时,该线程结束。
在你已经创建了实现Runnable接口的类以后,你要在类内部实例化一个Thread类的对象。Thread 类定义了好几种构造函数。我们会用到的如下:
Thread(Runnable threadOb, String threadName)
建立新的线程后,它并不运行直到调用了它的start()方法,该方法在Thread 类中定义。本质上,start() 执行的是一个对run()的调用。 Start()方法声明如下:
void start( )
// Create a second thread. class NewThread implements Runnable { Thread t; NewThread() { // Create a new, second thread t = new Thread(this, "Demo Thread"); System.out.println("Child thread: " + t); t.start(); // Start the thread } // This is the entry point for the second thread. public void run() { try { for(int i = 5; i > 0; i--) { System.out.println("Child Thread: " + i); Thread.sleep(500); } } catch (InterruptedException e) { System.out.println("Child interrupted."); } System.out.println("Exiting child thread."); } } class ThreadDemo { public static void main(String args[]) { new NewThread(); // create a new thread try { for(int i = 5; i > 0; i--) { System.out.println("Main Thread: " + i); Thread.sleep(1000); } } catch (InterruptedException e) { System.out.println("Main thread interrupted."); } System.out.println("Main thread exiting."); } }
t = new Thread(this, "Demo Thread");
Child thread: Thread[Demo Thread,5,main]
Main Thread: 5
Child Thread: 5
Child Thread: 4
Main Thread: 4
Child Thread: 3
Child Thread: 2
Main Thread: 3
Child Thread: 1
Exiting child thread.
Main Thread: 2
Main Thread: 1
Main thread exiting.
如前面提到的,在多线程程序中,通常主线程必须是结束运行的最后一个线程。实际上,一些老的JVM,如果主线程先于子线程结束,Java的运行时间系统就可能“挂起”。前述程序保证了主线程最后结束,因为主线程沉睡周期1000毫秒,而子线程仅为500毫秒。这就使子线程在主线程结束之前先结束。简而言之,你将看到等待线程结束的更好途径。
扩展Thread
创建线程的另一个途径是创建一个新类来扩展Thread类,然后创建该类的实例。当一个类继承Thread时,它必须重载run()方法,这个run()方法是新线程的入口。它也必须调用start()方法去启动新线程执行。下面用扩展thread类重写前面的程序:// Create a second thread by extending Thread class NewThread extends Thread { NewThread() { // Create a new, second thread super("Demo Thread"); System.out.println("Child thread: " + this); start(); // Start the thread } // This is the entry point for the second thread. public void run() { try { for(int i = 5; i > 0; i--) { System.out.println("Child Thread: " + i); Thread.sleep(500); } } catch (InterruptedException e) { System.out.println("Child interrupted."); } System.out.println("Exiting child thread."); } } class ExtendThread { public static void main(String args[]) { new NewThread(); // create a new thread try { for(int i = 5; i > 0; i--) { System.out.println("Main Thread: " + i); Thread.sleep(1000); } } catch (InterruptedException e) { System.out.println("Main thread interrupted."); } System.out.println("Main thread exiting."); } }
public Thread(String threadName)
选择合适方法
到这里,你一定会奇怪为什么Java有两种创建子线程的方法,哪一种更好呢。所有的问题都归于一点。Thread类定义了多种方法可以被派生类重载。对于所有的方法,惟一的必须被重载的是run()方法。这当然是实现Runnable接口所需的同样的方法。很多Java程序员认为类仅在它们被加强或修改时应该被扩展。因此,如果你不重载Thread的其他方法时,最好只实现Runnable 接口。这当然由你决定。然而,在本章的其他部分,我们应用实现runnable接口的类来创建线程。7.5 java创建多线程
到目前为止,我们仅用到两个线程:主线程和一个子线程。然而,你的程序可以创建所需的更多线程。例如,下面的程序创建了三个子线程:
// Create multiple threads. class NewThread implements Runnable { String name; // name of thread Thread t; NewThread(String threadname) { name = threadname; t = new Thread(this, name); System.out.println("New thread: " + t); t.start(); // Start the thread } // This is the entry point for thread. public void run() { try { for(int i = 5; i > 0; i--) { System.out.println(name + ": " + i); Thread.sleep(1000); } } catch (InterruptedException e) { System.out.println(name + "Interrupted"); } System.out.println(name + " exiting."); } } class MultiThreadDemo { public static void main(String args[]) { new NewThread("One"); // start threads new NewThread("Two"); new NewThread("Three"); try { // wait for other threads to end Thread.sleep(10000); } catch (InterruptedException e) { System.out.println("Main thread Interrupted"); } System.out.println("Main thread exiting."); } }
程序输出如下所示:
New thread: Thread[One,5,main]
New thread: Thread[Two,5,main]
New thread: Thread[Three,5,main]
One: 5
Two: 5
Three: 5
One: 4
Two: 4
Three: 4
One: 3
Three: 3
Two: 3
One: 2
Three: 2
Two: 2
One: 1
Three: 1
Two: 1
One exiting.
Two exiting.
Three exiting.
Main thread exiting.
如你所见,一旦启动,所有三个子线程共享CPU。注意main()中对sleep(10000)的调用。这使主线程沉睡十秒确保它最后结束。(这只是穿件几个相同的线程,线程中run函数修改后可以实现不同的线程)
7.6 java isAlive()和join()的使用
有两种方法可以判定一个线程是否结束。第一,可以在线程中调用isAlive()。这种方法由Thread定义,它的通常形式如下:
final boolean isAlive( )
final void join( ) throws InterruptedExceptio
// Using join() to wait for threads to finish. class NewThread implements Runnable { String name; // name of thread Thread t; NewThread(String threadname) { name = threadname; t = new Thread(this, name); System.out.println("New thread: " + t); t.start(); // Start the thread } // This is the entry point for thread. public void run() { try { for(int i = 5; i > 0; i--) { System.out.println(name + ": " + i); Thread.sleep(1000); } } catch (InterruptedException e) { System.out.println(name + " interrupted."); } System.out.println(name + " exiting."); } } class DemoJoin { public static void main(String args[]) { NewThread ob1 = new NewThread("One"); NewThread ob2 = new NewThread("Two"); NewThread ob3 = new NewThread("Three"); System.out.println("Thread One is alive: "+ ob1.t.isAlive()); //isAlive System.out.println("Thread Two is alive: "+ ob2.t.isAlive()); System.out.println("Thread Three is alive: "+ ob3.t.isAlive()); // wait for threads to finish try { System.out.println("Waiting for threads to finish."); ob1.t.join(); //join ob2.t.join(); ob3.t.join(); } catch (InterruptedException e) { System.out.println("Main thread Interrupted"); } System.out.println("Thread One is alive: "+ ob1.t.isAlive()); System.out.println("Thread Two is alive: "+ ob2.t.isAlive()); System.out.println("Thread Three is alive: "+ ob3.t.isAlive()); System.out.println("Main thread exiting."); } }
New thread: Thread[One,5,main]
New thread: Thread[Two,5,main]
New thread: Thread[Three,5,main]
Thread One is alive: true
Thread Two is alive: true
Thread Three is alive: true
Waiting for threads to finish.
One: 5
Two: 5
Three: 5
One: 4
Two: 4
Three: 4
One: 3
Two: 3
Three: 3
One: 2
Two: 2
Three: 2
One: 1
Two: 1
Three: 1
Two exiting.
Three exiting.
One exiting.
Thread One is alive: false
Thread Two is alive: false
Thread Three is alive: false
Main thread exiting.
如你所见,调用join()后返回,线程终止执行。
7.7 java线程优先级
线程优先级被线程调度用来判定何时每个线程允许运行。理论上,优先级高的线程比优先级低的线程获得更多的CPU时间。实际上,线程获得的CPU时间通常由包括优先级在内的多个因素决定(例如,一个实行多任务处理的操作系统如何更有效的利用CPU时间)。
一个优先级高的线程自然比优先级低的线程优先。举例来说,当低优先级线程正在运行,而一个高优先级的线程被恢复(例如从沉睡中或等待I/O中),它将抢占低优先级线程所使用的CPU。
理论上,等优先级线程有同等的权利使用CPU。但你必须小心了。记住,Java是被设计成能在很多环境下工作的。一些环境下实现多任务处理从本质上与其他环境不同。为安全起见,等优先级线程偶尔也受控制。这保证了所有线程在无优先级的操作系统下都有机会运行。实际上,在无优先级的环境下,多数线程仍然有机会运行,因为很多线程不可避免的会遭遇阻塞,例如等待输入输出。遇到这种情形,阻塞的线程挂起,其他线程运行。
但是如果你希望多线程执行的顺利的话,最好不要采用这种方法。同样,有些类型的任务是占CPU的。对于这些支配CPU类型的线程,有时你希望能够支配它们,以便使其他线程可以运行。
设置线程的优先级,用setPriority()方法,该方法也是Tread 的成员。它的通常形式为:
final void setPriority(int level)
这 里 , level 指 定了对所调用的线程的新的优先权的设置。Level的值必须在MIN_PRIORITY到MAX_PRIORITY范围内。通常,它们的值分别是1和10。要返回一个线程为默认的优先级,指定NORM_PRIORITY,通常值为5。这些优先级在Thread中都被定义为final型变量。
你可以通过调用Thread的getPriority()方法来获得当前的优先级设置。该方法如下:
final int getPriority( )
当涉及调度时,Java的执行可以有本质上不同的行为。Windows 95/98/NT/2000 的工作或多或少如你所愿。但其他版本可能工作的完全不同。大多数矛盾发生在你使用有优先级行为的线程,而不是协同的腾出CPU时间。最安全的办法是获得可预先性的优先权,Java获得跨平台的线程行为的方法是自动放弃对CPU的控制。
下面的例子阐述了两个不同优先级的线程,运行于具有优先权的平台,这与运行于无优先级的平台不同。一个线程通过Thread.NORM_PRIORITY设置了高于普通优先级两级的级数,另一线程设置的优先级则低于普通级两级。两线程被启动并允许运行10秒。每个线程执行一个循环,记录反复的次数。10秒后,主线程终止了两线程。每个线程经过循环的次数被显示。
// Demonstrate thread priorities. class clicker implements Runnable { int click = 0; Thread t; private volatile boolean running = true; public clicker(int p) { t = new Thread(this); t.setPriority(p); //设置线程优先级 } public void run() { while (running) { click++; } } public void stop() { running = false; } public void start() { t.start(); } } class HiLoPri { public static void main(String args[]) { Thread.currentThread().setPriority(Thread.MAX_PRIORITY); //主线程优先级 clicker hi = new clicker(Thread.NORM_PRIORITY + 2); clicker lo = new clicker(Thread.NORM_PRIORITY - 2); lo.start(); hi.start(); try { Thread.sleep(10000); } catch (InterruptedException e) { System.out.println("Main thread interrupted."); } lo.stop(); hi.stop(); // Wait for child threads to terminate. try { hi.t.join(); lo.t.join(); } catch (InterruptedException e) { System.out.println("InterruptedException caught"); } System.out.println("Low-priority thread: " + lo.click); System.out.println("High-priority thread: " + hi.click); } }
该程序在Windows 98下运行的输出,表明线程确实上下转换,甚至既不屈从于CPU,也不被输入输出阻塞。优先级高的线程获得大约90%的CPU时间。
Low-priority thread: 4408112
High-priority thread: 589626904
当然,该程序的精确的输出结果依赖于你的CPU的速度和运行的其他任务的数量。当同样的程序运行于无优先级的系统,将会有不同的结果。
上述程序还有个值得注意的地方。注意running前的关键字volatile。尽管volatile 在下章会被很仔细的讨论,用在此处以确保running的值在下面的循环中每次都得到验证。
while (running) { click++; }
如果不用volatile,Java可以自由的优化循环:running的值被存在CPU的一个寄存器中,
每次重复不一定需要复检。volatile的运用阻止了该优化,告知Java running可以改变,改变
方式并不以直接代码形式显示。
7.8 java线程同步
当两个或两个以上的线程需要共享资源,它们需要某种方法来确定资源在某一刻仅被一个线程占用。达到此目的的过程叫做同步(synchronization)。像你所看到的,Java为此提供了独特的,语言水平上的支持。
同步的关键是管程(也叫信号量semaphore)的概念。管程是一个互斥独占锁定的对象,或称互斥体(mutex)。在给定的时间,仅有一个线程可以获得管程。当一个线程需要锁定,它必须进入管程。所有其他的试图进入已经锁定的管程的线程必须挂起直到第一个线程退出管程。这些其他的线程被称为等待管程。一个拥有管程的线程如果愿意的话可以再次进入相同的管程。
如果你用其他语言例如C或C++时用到过同步,你会知道它用起来有一点诡异。这是因为很多语言它们自己不支持同步。相反,对同步线程,程序必须利用操作系统源语。幸运的是Java通过语言元素实现同步,大多数的与同步相关的复杂性都被消除。
你可以用两种方法同步化代码。两者都包括synchronized关键字的运用,下面分别说明这两种方法。
使用同步方法
Java中同步是简单的,因为所有对象都有它们与之对应的隐式管程。进入某一对象的管程,就是调用被synchronized关键字修饰的方法。当一个线程在一个同步方法内部,所有试图调用该方法(或其他同步方法)的同实例的其他线程必须等待。为了退出管程,并放弃对对象的控制权给其他等待的线程,拥有管程的线程仅需从同步方法中返回。
为理解同步的必要性,让我们从一个应该使用同步却没有用的简单例子开始。下面的程序有三个简单类。首先是Callme,它有一个简单的方法call( )。call( )方法有一个名为msg的String参数。该方法试图在方括号内打印msg 字符串。有趣的事是在调用call( ) 打印左括号和msg字符串后,调用Thread.sleep(1000),该方法使当前线程暂停1秒。
下一个类的构造函数Caller,引用了Callme的一个实例以及一个String,它们被分别存在target 和 msg 中。构造函数也创建了一个调用该对象的run( )方法的新线程。该线程立即启动。Caller类的run( )方法通过参数msg字符串调用Callme实例target的call( ) 方法。最后,Synch类由创建Callme的一个简单实例和Caller的三个具有不同消息字符串的实例开始。
Callme的同一实例传给每个Caller实例。
// This program is not synchronized. class Callme { void call(String msg) { System.out.print("[" + msg); try { Thread.sleep(1000); } catch(InterruptedException e) { System.out.println("Interrupted"); } System.out.println("]"); } } class Caller implements Runnable { String msg; Callme target; Thread t; public Caller(Callme targ, String s) { target = targ; msg = s; t = new Thread(this); t.start(); } public void run() { target.call(msg); } } class Synch { public static void main(String args[]) { Callme target = new Callme(); Caller ob1 = new Caller(target, "Hello"); Caller ob2 = new Caller(target, "Synchronized"); Caller ob3 = new Caller(target, "World"); // wait for threads to end try { ob1.t.join(); ob2.t.join(); ob3.t.join(); } catch(InterruptedException e) { System.out.println("Interrupted"); } } }
该程序的输出如下:
Hello[Synchronized[World]
]
]
在本例中,通过调用sleep( ),call( )方法允许执行转换到另一个线程。该结果是三个消息字符串的混合输出。该程序中,没有阻止三个线程同时调用同一对象的同一方法的方法存在。这是一种竞争,因为三个线程争着完成方法。例题用sleep( )使该影响重复和明显。在大多数情况,竞争是更为复杂和不可预知的,因为你不能确定何时上下文转换会发生。这使程序时而运行正常时而出错。
为达到上例所想达到的目的,必须有权连续的使用call( )。也就是说,在某一时刻,必须限制只有一个线程可以支配它。为此,你只需在call( ) 定义前加上关键字synchronized,如下:
class Callme { synchronized void call(String msg) { ...
这防止了在一个线程使用call( )时其他线程进入call( )。在synchronized加到call( )前面以后,程序输出如下:
[Hello]
[Synchronized]
[World]
任何时候在多线程情况下,你有一个方法或多个方法操纵对象的内部状态,都必须用synchronized 关键字来防止状态出现竞争。记住,一旦线程进入实例的同步方法,没有其他线程可以进入相同实例的同步方法。然而,该实例的其他不同步方法却仍然可以被调用。
同步语句
尽管在创建的类的内部创建同步方法是获得同步的简单和有效的方法,但它并非在任何时候都有效。这其中的原因,请跟着思考。假设你想获得不为多线程访问设计的类对象的同步访问,也就是,该类没有用到synchronized方法。而且,该类不是你自己,而是第三方创建的,你不能获得它的源代码。这样,你不能在相关方法前加synchronized修饰符。怎样才能使该类的一个对象同步化呢?很幸运,解决方法很简单:你只需将对这个类定义的方法的调用放入一个synchronized块内就可以了。
下面是synchronized语句的普通形式:
synchronized(object) { // statements to be synchronized }
其中,object是被同步对象的引用。如果你想要同步的只是一个语句,那么不需要花括号。一个同步块确保对object成员方法的调用仅在当前线程成功进入object管程后发生。
下面是前面程序的修改版本,在run( )方法内用了同步块:
// This program uses a synchronized block. class Callme { void call(String msg) { System.out.print("[" + msg); try { Thread.sleep(1000); } catch (InterruptedException e) { System.out.println("Interrupted"); } System.out.println("]"); } } class Caller implements Runnable { String msg; Callme target; Thread t; public Caller(Callme targ, String s) { target = targ; msg = s; t = new Thread(this); t.start(); } // synchronize calls to call() public void run() { synchronized(target) { // synchronized block ☆ target.call(msg); } } } class Synch1 { public static void main(String args[]) { Callme target = new Callme(); Caller ob1 = new Caller(target, "Hello"); Caller ob2 = new Caller(target, "Synchronized"); Caller ob3 = new Caller(target, "World"); // wait for threads to end try { ob1.t.join(); ob2.t.join(); ob3.t.join(); } catch(InterruptedException e) { System.out.println("Interrupted"); } } }
这里,call( )方法没有被synchronized修饰。而synchronized是在Caller类的run( )方法中声明的。这可以得到上例中同样正确的结果,因为每个线程运行前都等待先前的一个线程结束。
7.9 java线程间通信
上述例题无条件的阻塞了其他线程异步访问某个方法。Java对象中隐式管程的应用是很强大的,但是你可以通过进程间通信达到更微妙的境界。这在Java中是尤为简单的。
像前面所讨论过的,多线程通过把任务分成离散的和合乎逻辑的单元代替了事件循环程序。线程还有第二优点:它远离了轮询。轮询通常由重复监测条件的循环实现。一旦条件成立,就要采取适当的行动。这浪费了CPU时间。举例来说,考虑经典的序列问题,当一个线程正在产生数据而另一个程序正在消费它。为使问题变得更有趣,假设数据产生器必须等待消费者完成工作才能产生新的数据。在轮询系统,消费者在等待生产者产生数据时会浪费很多CPU周期。一旦生产者完成工作,它将启动轮询,浪费更多的CPU时间等待消费者的工作结束,如此下去。很明显,这种情形不受欢迎。
为避免轮询,Java包含了通过wait( ),notify( )和notifyAll( )方法实现的一个进程间通信机制。这些方法在对象中是用final方法实现的,所以所有的类都含有它们。这三个方法仅在synchronized方法中才能被调用。尽管这些方法从计算机科学远景方向上来说具有概念的高度先进性,实际中用起来是很简单的:
- wait( ) 告知被调用的线程放弃管程进入睡眠直到其他线程进入相同管程并且调用notify( )。
- notify( ) 恢复相同对象中第一个调用 wait( ) 的线程。
- notifyAll( ) 恢复相同对象中所有调用 wait( ) 的线程。具有最高优先级的线程最先运行。
这些方法在Object中被声明,如下所示:
final void wait( ) throws InterruptedException final void notify( ) final void notifyAll( )
wait( )存在的另外的形式允许你定义等待时间。
下面的例子程序错误的实行了一个简单生产者/消费者的问题。它由四个类组成:Q,设法获得同步的序列;Producer,产生排队的线程对象;Consumer,消费序列的线程对象;以及PC,创建单个Q,Producer,和Consumer的小类。
// An incorrect implementation of a producer and consumer. class Q { int n; synchronized int get() { System.out.println("Got: " + n); return n; } synchronized void put(int n) { this.n = n; System.out.println("Put: " + n); } } class Producer implements Runnable { Q q; Producer(Q q) { this.q = q; new Thread(this, "Producer").start(); } public void run() { int i = 0; while(true) { q.put(i++); } } } class Consumer implements Runnable { Q q; Consumer(Q q) { this.q = q; new Thread(this, "Consumer").start(); } public void run() { while(true) { q.get(); } } } class PC { public static void main(String args[]) { Q q = new Q(); new Producer(q); new Consumer(q); System.out.println("Press Control-C to stop."); } }
尽管Q类中的put( )和get( )方法是同步的,没有东西阻止生产者超越消费者,也没有东西阻止消费者消费同样的序列两次。这样,你就得到下面的错误输出(输出将随处理器速度和装载的任务而改变):
Put: 1
Got: 1
Got: 1
Got: 1
Got: 1
Got: 1
Put: 2
Put: 3
Put: 4
Put: 5
Put: 6
Put: 7
Got: 7
生产者生成1后,消费者依次获得同样的1五次。生产者在继续生成2到7,消费者没有机会获得它们。
用Java正确的编写该程序是用wait( )和notify( )来对两个方向进行标志,如下所示:
// A correct implementation of a producer and consumer. class Q { int n; boolean valueSet = false; synchronized int get() { if(!valueSet) try { wait(); // } catch(InterruptedException e) { System.out.println("InterruptedException caught"); } System.out.println("Got: " + n); valueSet = false; notify(); // return n; } synchronized void put(int n) { if(valueSet) try { wait(); // } catch(InterruptedException e) { System.out.println("InterruptedException caught"); } this.n = n; valueSet = true; System.out.println("Put: " + n); notify(); // } } class Producer implements Runnable { Q q; Producer(Q q) { this.q = q; new Thread(this, "Producer").start(); } public void run() { int i = 0; while(true) { q.put(i++); } } } class Consumer implements Runnable { Q q; Consumer(Q q) { this.q = q; new Thread(this, "Consumer").start(); } public void run() { while(true) { q.get(); } } } class PCFixed { public static void main(String args[]) { Q q = new Q(); new Producer(q); new Consumer(q); System.out.println("Press Control-C to stop."); } }//wait()后本线程释放CPU,等待任何一个notify到来; 典
内部get( ), wait( )被调用。这使执行挂起直到Producer 告知数据已经预备好。这时,内部get( ) 被恢复执行。获取数据后,get( )调用notify( )。这告诉Producer可以向序列中输入更多数据。在put( )内,wait( )挂起执行直到Consumer取走了序列中的项目。当执行再继续,下一个数据项目被放入序列,notify( )被调用,这通知Consumer它应该移走该数据。
下面是该程序的输出,它清楚的显示了同步行为:
Put: 1
Got: 1
Put: 2
Got: 2
Put: 3
Got: 3
Put: 4
Got: 4
Put: 5
Got: 5
7.10 java线程死锁
需要避免的与多任务处理有关的特殊错误类型是死锁(deadlock)。死锁发生在当两个线程对一对同步对象有循环依赖关系时。例如,假定一个线程进入了对象X的管程而另一个线程进入了对象Y的管程。如果X的线程试图调用Y的同步方法,它将像预料的一样被锁定。而Y的线程同样希望调用X的一些同步方法,线程永远等待,因为为到达X,必须释放自己的Y的锁定以使第一个线程可以完成。死锁是很难调试的错误,因为:
- 通常,它极少发生,只有到两线程的时间段刚好符合时才能发生。
- 它可能包含多于两个的线程和同步对象(也就是说,死锁在比刚讲述的例子有更多复杂的事件序列的时候可以发生)。
为充分理解死锁,观察它的行为是很有用的。下面的例子生成了两个类,A和B,分别有foo( )和bar( )方法。这两种方法在调用其他类的方法前有一个短暂的停顿。主类,名为Deadlock,创建了A和B的实例,然后启动第二个线程去设置死锁环境。foo( )和bar( )方法使用sleep( )强迫死锁现象发生。
// An example of deadlock. class A { synchronized void foo(B b) { String name = Thread.currentThread().getName(); System.out.println(name + " entered A.foo"); try { Thread.sleep(1000); } catch(Exception e) { System.out.println("A Interrupted"); } System.out.println(name + " trying to call B.last()"); b.last(); } synchronized void last() { System.out.println("Inside A.last"); } } class B { synchronized void bar(A a) { String name = Thread.currentThread().getName(); System.out.println(name + " entered B.bar"); try { Thread.sleep(1000); } catch(Exception e) { System.out.println("B Interrupted"); } System.out.println(name + " trying to call A.last()"); a.last(); } synchronized void last() { System.out.println("Inside A.last"); } } class Deadlock implements Runnable { A a = new A(); B b = new B(); Deadlock() { Thread.currentThread().setName("MainThread"); Thread t = new Thread(this, "RacingThread"); t.start(); a.foo(b); // get lock on a in this thread. System.out.println("Back in main thread"); } public void run() { b.bar(a); // get lock on b in other thread. System.out.println("Back in other thread"); } public static void main(String args[]) { new Deadlock(); } }
运行程序后,输出如下:
MainThread entered A.foo
RacingThread entered B.bar
MainThread trying to call B.last()
RacingThread trying to call A.last()
因为程序死锁,你需要按CTRL-C来结束程序。在PC机上按CTRL-BREAK(或在Solaris下按CTRL-\)你可以看到全线程和管程缓冲堆。你会看到RacingThread在等待管程a时占用管程b,同时,MainThread占用a等待b。该程序永远都不会结束。像该例阐明的,你的多线程程序经常被锁定,死锁是你首先应检查的问题。
7.11 java线程的挂起、恢复和终止
有时,线程的挂起是很有用的。例如,一个独立的线程可以用来显示当日的时间。如果用户不希望用时钟,线程被挂起。在任何情形下,挂起线程是很简单的,一旦挂起,重新启动线程也是一件简单的事。
挂起,终止和恢复线程机制在Java 2和早期版本中有所不同。尽管你运用Java 2的途径编写代码,你仍需了解这些操作在早期Java环境下是如何完成的。例如,你也许需要更新或维护老的代码。你也需要了解为什么Java 2会有这样的变化。因为这些原因,下面内容描述了执行线程控制的原始方法,接着是Java 2的方法。
Java 1.1或更早版本的线程的挂起、恢复和终止
先于Java2的版本,程序用Thread 定义的suspend() 和 resume() 来暂停和再启动线程。它们的形式如下:
final void suspend( ) //暂定 final void resume( ) //启动
下面的程序描述了这些方法:
// Using suspend() and resume(). class NewThread implements Runnable { String name; // name of thread Thread t; NewThread(String threadname) { name = threadname; t = new Thread(this, name); System.out.println("New thread: " + t); t.start(); // Start the thread } // This is the entry point for thread. public void run() { try { for(int i = 15; i > 0; i--) { System.out.println(name + ": " + i); Thread.sleep(200); } } catch (InterruptedException e) { System.out.println(name + " interrupted."); } System.out.println(name + " exiting."); } } class SuspendResume { public static void main(String args[]) { NewThread ob1 = new NewThread("One"); NewThread ob2 = new NewThread("Two"); try { Thread.sleep(1000); ob1.t.suspend(); //挂起 System.out.println("Suspending thread One"); Thread.sleep(1000); ob1.t.resume(); //启动线程 System.out.println("Resuming thread One"); ob2.t.suspend(); System.out.println("Suspending thread Two"); Thread.sleep(1000); ob2.t.resume(); System.out.println("Resuming thread Two"); } catch (InterruptedException e) { System.out.println("Main thread Interrupted"); } // wait for threads to finish try { System.out.println("Waiting for threads to finish."); ob1.t.join(); ob2.t.join(); } catch (InterruptedException e) { System.out.println("Main thread Interrupted"); } System.out.println("Main thread exiting."); } }
程序的部分输出如下:
New thread: Thread[One,5,main]
One: 15
New thread: Thread[Two,5,main]
Two: 15
One: 14
Two: 14
One: 13
Two: 13
One: 12
Two: 12
One: 11
Two: 11
Suspending thread One
Two: 10
Two: 9
Two: 8
Two: 7
Two: 6
Resuming thread One
Suspending thread Two
One: 10
One: 9
One: 8
One: 7
One: 6
Resuming thread Two
Waiting for threads to finish.
Two: 5
One: 5
Two: 4
One: 4
Two: 3
One: 3
Two: 2
One: 2
Two: 1
One: 1
Two exiting.
One exiting.
Main thread exiting.
Thread类同样定义了stop() 来终止线程。它的形式如下:
void stop( )
一旦线程被终止,它不能被resume() 恢复继续运行。
Java 2中挂起、恢复和终止线程
Thread定义的suspend(),resume()和stop()方法看起来是管理线程的完美的和方便的方法,它们不能用于新Java版本的程序。下面是其中的原因。Thread类的suspend()方法在Java2中不被赞成,因为suspend()有时会造成严重的系统故障。假定对关键的数据结构的一个线程被锁定的情况,如果该线程在那里挂起,这些锁定的线程并没有放弃对资源的控制。其他的等待这些资源的线程可能死锁。
Resume()方法同样不被赞同。它不引起问题,但不能离开suspend()方法而独立使用。Thread类的stop()方法同样在Java 2中受到反对。这是因为该方法可能导致严重的系统故障。设想一个线程正在写一个精密的重要的数据结构且仅完成一个零头。如果该线程在此刻终止,则数据结构可能会停留在崩溃状态。
因为在Java 2中不能使用suspend(),resume()和stop() 方法来控制线程,你也许会想那就没有办法来停止,恢复和结束线程。其实不然。相反,线程必须被设计以使run() 方法定期检查以来判定线程是否应该被挂起,恢复或终止它自己的执行。有代表性的,这由建立一个指示线程状态的标志变量来完成。只要该标志设为“running”,run()方法必须继续让线程执行。如果标志为“suspend”,线程必须暂停。若设为“stop”,线程必须终止。
当然,编写这样的代码有很多方法,但中心主题对所有的程序应该是相同的。
下面的例题阐述了从Object继承的wait()和notify()方法怎样控制线程的执行。该例与前面讲过的程序很像。然而,不被赞同的方法都没有用到。让我们思考程序的执行。
NewTread 类包含了用来控制线程执行的布尔型的实例变量suspendFlag。它被构造函数初始化为false。Run()方法包含一个监测suspendFlag 的同步声明的块。如果变量是true,wait()方法被调用以挂起线程。Mysuspend()方法设置suspendFlag为true。Myresume()方法设置suspendFlag为false并且调用notify()方法来唤起线程。最后,main()方法被修改以调用mysuspend()和myresume()方法。
// Suspending and resuming a thread for Java2 class NewThread implements Runnable { String name; // name of thread Thread t; boolean suspendFlag; NewThread(String threadname) { name = threadname; t = new Thread(this, name); System.out.println("New thread: " + t); suspendFlag = false; t.start(); // Start the thread } // This is the entry point for thread. public void run() { try { for(int i = 15; i > 0; i--) { System.out.println(name + ": " + i); Thread.sleep(200); synchronized(this) { while(suspendFlag) { //☆☆ 自定义函数 wait(); //说白了,系统自带的 suspend、resume都没wait稳定 } } } } catch (InterruptedException e) { System.out.println(name + " interrupted."); } System.out.println(name + " exiting."); } void mysuspend() { //☆☆ 自定义函数 suspendFlag = true; } synchronized void myresume() { suspendFlag = false; notify(); } } class SuspendResume { public static void main(String args[]) { NewThread ob1 = new NewThread("One"); NewThread ob2 = new NewThread("Two"); try { Thread.sleep(1000); ob1.mysuspend(); System.out.println("Suspending thread One"); Thread.sleep(1000); ob1.myresume(); // System.out.println("Resuming thread One"); ob2.mysuspend(); System.out.println("Suspending thread Two"); Thread.sleep(1000); ob2.myresume(); System.out.println("Resuming thread Two"); } catch (InterruptedException e) { System.out.println("Main thread Interrupted"); } // wait for threads to finish try { System.out.println("Waiting for threads to finish."); ob1.t.join(); ob2.t.join(); } catch (InterruptedException e) { System.out.println("Main thread Interrupted"); } System.out.println("Main thread exiting."); } }
该程序的输出与前面的程序相同。此书的后面部分,你将看到用Java 2机制控制线程的更多例子。尽管这种机制不像老方法那样“干净”,然而,它是确保运行时不发生错误的方法。它是所有新的代码必须采用的方法。
八◐ 输入输出(IO)操作
8.1 java输入输出(IO)和流的基本概念
输入输出(I/O)是指程序与外部设备或其他计算机进行交互的操作。几乎所有的程序都具有输入与输出操作,如从键盘上读取数据,从本地或网络上的文件读取数据或写入数据等。通过输入和输出操作可以从外界接收信息,或者是把信息传递给外界。Java把这些输入与输出操作用流来实现,通过统一的接口来表示,从而使程序设计更为简单。
Java流的概念
流(Stream)是指在计算机的输入输出操作中各部件之间的数据流动。按照数据的传输方向,流可分为输入流与输出流。Java语言里的流序列中的数据既可以是未经加工的原始二进制数据,也可以是经过一定编码处理后符合某种特定格式的数据。
1.输入输出流
在Java中,把不同类型的输入输出源抽象为流,其中输入和输出的数据称为数据流(Data Stream)。数据流是Java程序发送和接收数据的一个通道,数据流中包括输入流(Input Stream)和输出流(Output Stream)。通常应用程序中使用输入流读出数据,输出流写入数据。 流式输入、输出的特点是数据的获取和发送均沿数据序列顺序进行。相对于程序来说,输出流是往存储介质或数据通道写入数据,而输入流是从存储介质或数据通道中读取数据,一般来说关于流的特性有下面几点:
- 先进先出,最先写入输出流的数据最先被输入流读取到。
- 顺序存取,可以一个接一个地往流中写入一串字节,读出时也将按写入顺序读取一串字节,不能随机访问中间的数据。
- 只读或只写,每个流只能是输入流或输出流的一种,不能同时具备两个功能,在一个数据传输通道中,如果既要写入数据,又要读取数据,则要分别提供两个流。
2.缓冲流
为了提高数据的传输效率,引入了缓冲流(Buffered Stream)的概念,即为一个流配备一个缓冲区(Buffer),一个缓冲区就是专门用于传送数据的一块内存。
当向一个缓冲流写入数据时,系统将数据发送到缓冲区,而不是直接发送到外部设备。缓冲区自动记录数据,当缓冲区满时,系统将数据全部发送到相应的外部设备。当从一个缓冲流中读取数据时,系统实际是从缓冲区中读取数据,当缓冲区为空时,系统就会从相关外部设备自动读取数据,并读取尽可能多的数据填满缓冲区。 使用数据流来处理输入输出的目的是使程序的输入输出操作独立于相关设备,由于程序不需关注具体设备实现的细节(具体细节由系统处理),所以对于各种输入输出设备,只要针对流做处理即可,不需修改源程序,从而增强了程序的可移植性。
I/O流类概述
为了方便流的处理,Java语言提供了java.io包,在该包中的每一个类都代表了一种特定的输入或输出流。为了使用这些流类,编程时需要引入这个包。 Java提供了两种类型的输入输出流:一种是面向字节的流,数据的处理以字节为基本单位;另一种是面向字符的流,用于字符数据的处理。字节流(Byte Stream)每次读写8位二进制数,也称为二进制字节流或位流。字符流一次读写16位二进制数,并将其做一个字符而不是二进制位来处理。需要注意的是,为满足字符的国际化表示,Java语言的字符编码采用的是16位的Unicode码,而普通文本文件中采用的是8位ASCⅡ码。
java.io中类的层次结构如图10-1所示。
图10-1 java.io包的顶级层次结构图
针对一些频繁的设备交互,Java语言系统预定了3个可以直接使用的流对象,分别是:
- System.in(标准输入),通常代表键盘输入。
- System.out(标准输出):通常写往显示器。
- System.err(标准错误输出):通常写往显示器。
在Java语言中使用字节流和字符流的步骤基本相同,以输入流为例,首先创建一个与数据源相关的流对象,然后利用流对象的方法从流输入数据,最后执行close()方法关闭流。
8.2 java中面向字符的输入流
字符流是针对字符数据的特点进行过优化的,因而提供一些面向字符的有用特性,字符流的源或目标通常是文本文件。 Reader和Writer是java.io包中所有字符流的父类。由于它们都是抽象类,所以应使用它们的子类来创建实体对象,利用对象来处理相关的读写操作。Reader和Writer的子类又可以分为两大类:一类用来从数据源读入数据或往目的地写出数据(称为节点流),另一类对数据执行某种处理(称为处理流)。
面向字符的输入流类都是Reader的子类,其类层次结构如图10-2所示。
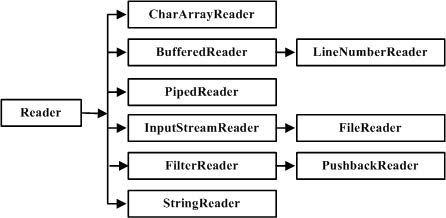
图10-2 Reader的类层次结构图
表 10-1 列出了 Reader 的主要子类及说明。
| 类名 | 功能描述 |
|---|---|
| CharArrayReader | 从字符数组读取的输入流 |
| BufferedReader | 缓冲输入字符流 |
| PipedReader | 输入管道 |
| InputStreamReader | 将字节转换到字符的输入流 |
| FilterReader | 过滤输入流 |
| StringReader | 从字符串读取的输入流 |
| LineNumberReader | 为输入数据附加行号 |
| PushbackReader | 返回一个字符并把此字节放回输入流 |
| FileReader | 从文件读取的输入流 |
Reader 所提供的方法如表 10-2 所示,可以利用这些方法来获得流内的位数据。
| 方法 | 功能描述 |
|---|---|
| void close() | 关闭输入流 |
| void mark() | 标记输入流的当前位置 |
| boolean markSupported() | 测试输入流是否支持 mark |
| int read() | 从输入流中读取一个字符 |
| int read(char[] ch) | 从输入流中读取字符数组 |
| int read(char[] ch, int off, int len) | 从输入流中读 len 长的字符到 ch 内 |
| boolean ready() | 测试流是否可以读取 |
| void reset() | 重定位输入流 |
| long skip(long n) | 跳过流内的 n 个字符 |
使用 FileReader 类读取文件
FileReader 类是 Reader 子类 InputStreamReader 类的子类,因此 FileReader 类既可以使用Reader 类的方法也可以使用 InputStreamReader 类的方法来创建对象。
在使用 FileReader 类读取文件时,必须先调用 FileReader()构造方法创建 FileReader 类的对象,再调用 read()方法。FileReader 构造方法的格式为:
public FileReader(String name); //根据文件名创建一个可读取的输入流对象
【例 10-1】利用 FileReader 类读取纯文本文件的内容(查看源代码)。
运行结果如图 10-3 所示:
图 10-3 例 10_1 运行结果(输出内容为文件ep10_1.txt的内容)
需要注意的是,Java 把一个汉字或英文字母作为一个字符对待,回车或换行作为两个字符对待。
使用 BufferedReader 类读取文件
BufferedReader 类是用来读取缓冲区中的数据。使用时必须创建 FileReader 类对象,再以该对象为参数创建 BufferedReader 类的对象。BufferedReader 类有两个构造方法,其格式为:
public BufferedReader(Reader in); //创建缓冲区字符输入流 public BufferedReader(Reader in,int size); //创建输入流并设置缓冲区大小
【例 10-2】利用 BufferedReader 类读取纯文本文件的内容(查看源代码)。
运行结果如图 10-4 所示:
图 10-4 例 10_2 运行结果
需要注意的是,执行 read()或 write()方法时,可能由于 IO 错误,系统抛出 IOException 异常,需要将执行读写操作的语句包括在 try 块中,并通过相应的 catch 块来处理可能产生的异常。
8.3 Java面向字符的输出流
面向字符的输出流都是类 Writer 的子类,其类层次结构如图 10-5 所示。
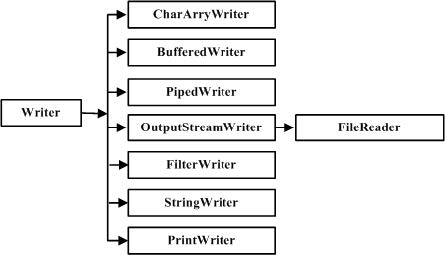
图10-5 Writer的类层次结构图
表 10-3 列出了 Writer 的主要子类及说明。
| 类名 | 功能说明 |
|---|---|
| CharArrayWriter | 写到字符数组的输出流 |
| BufferedWriter | 缓冲输出字符流 |
| PipedWriter | 输出管道 |
| OutputStreamWriter | 转换字符到字节的输出流 |
| FilterWriter | 过滤输出流 |
| StringWriter | 输出到字符串的输出流 |
| PrintWriter | 包含 print()和 println()的输出流 |
| FileWriter | 输出到文件的输出流 |
Writer 所提供的方法如表 10-4 所示。
| 方法 | 功能描述 |
|---|---|
| void close() | 关闭输出流 |
| void flush() | 将缓冲区中的数据写到文件中 |
| void writer(int c) | 将单一字符 c 输出到流中 |
| void writer(String str) | 将字符串 str 输出到流中 |
| void writer(char[] ch) | 将字符数组 ch 输出到流 |
| void writer(char[] ch, int offset, int length) | 将一个数组内自 offset 起到 length 长的字符输出到流 |
使用 FileWriter 类写入文件
FileWriter 类是 Writer 子类 OutputStreamWriter 类的子类,因此 FileWriter 类既可以使用 Writer类的方法也可以使用 OutputStreamWriter 类的方法来创建对象。
在使用 FileWriter 类写入文件时,必须先调用 FileWriter()构造方法创建 FileWriter 类的对象,再调用 writer()方法。FileWriter 构造方法的格式为:
public FileWriter(String name); //根据文件名创建一个可写入的输出流对象 public FileWriter(String name,Boolean a); //a 为真,数据将追加在文件后面
【例 10-3】利用 FileWriter 类将 ASCⅡ字符写入到文件中(查看源代码)。
运行后程序后,打开 ep10_3.txt 文件,显示内容为:
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}
使用 BufferedWriter 类写入文件
BufferedWriter 类是用来将数据写入到缓冲区。使用时必须创建 FileWriter 类对象,再以该对象为参数创建 BufferedWriter 类的对象,最后需要用 flush()方法将缓冲区清空。BufferedWriter类有两个构造方法,其格式为:
public BufferedWriter(Writer out); //创建缓冲区字符输出流 public BufferedWriter(Writer out,int size); //创建输出流并设置缓冲区大小
【例 10-4】利用 BufferedWriter 类进行文件复制(查看源代码)。
需要注意的是,调用 out 对象的 write()方法写入数据时,不会写入回车,因此需要使用newLine()方法在每行数据后加入回车,以保证目标文件与源文件相一致。
8.4 java中面向字节的输入输出流
字节流以字节为传输单位,用来读写8位的数据,除了能够处理纯文本文件之外,还能用来处理二进制文件的数据。InputStream类和OutputStream类是所有字节流的父类。
InputStream类
面向字节的输入流都是InputStream类的子类,其类层次结构如图10-6所示。
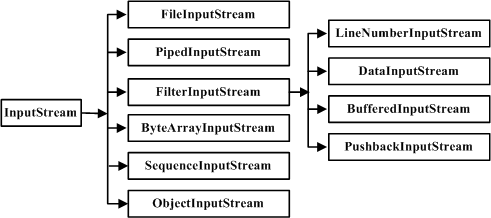
图10-6 InputStream的类层次结构图
表 10-5 列出了 InputStream 的主要子类及说明。
| 类名 | 功能描述 |
|---|---|
| FileInputStream | 从文件中读取的输入流 |
| PipedInputStream | 输入管道 |
| FilterInputStream | 过滤输入流 |
| ByteArrayInputStream | 从字节数组读取的输入流 |
| SequenceInputStream | 两个或多个输入流的联合输入流,按顺序读取 |
| ObjectInputStream | 对象的输入流 |
| LineNumberInputStream | 为文本文件输入流附加行号 |
| DataInputStream | 包含读取 Java 标准数据类型方法的输入流 |
| BufferedInputStream | 缓冲输入流 |
| PushbackInputStream | 返回一个字节并把此字节放回输入流 |
InputStream 流类中包含一套所有输入都需要的方法,可以完成最基本的从输入流读入数据的功能。表 10-6 列出了其中常用的方法及说明。
| 方法 | 功能描述 |
|---|---|
| void close() | 关闭输入流 |
| void mark() | 标记输入流的当前位置 |
| void reset() | 将读取位置返回到标记处 |
| int read() | 从输入流中当前位置读入一个字节的二进制数据,以此数据为低位字节,补足16位的整型量(0~255)后返回,若输入流中当前位置没有数据,则返回-1 |
| int read(byte b[]) | 从输入流中的当前位置连续读入多个字节保存在数组中,并返回所读取的字节数 |
| int read(byte b[], int off, int len) | 从输入流中当前位置连续读len长的字节,从数组第off+1个元素位置处开始存放,并返回所读取的字节数 |
| int available() | 返回输入流中可以读取的字节数 |
| long skip(long n) | 略过n个字节 |
| long skip(long n) | 跳过流内的n个字符 |
| boolean markSupported() | 测试输入数据流是否支持标记 |
OutputStream类
面向字节的输出流都是OutputStream类的子类,其类层次结构如图10-7所示。
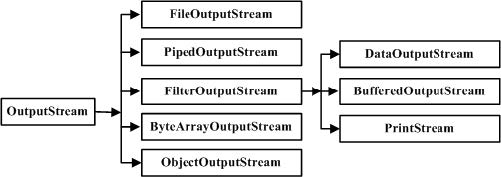
图10-7 OutputStream的类层次结构图
10-7列出了OutputStream的主要子类及说明。
| 类名 | 功能描述 |
|---|---|
| FileOutputStream | 写入文件的输出流 |
| PipedOutputStream | 输出管道 |
| FilterOutputStream | 过滤输出流 |
| ByteArrayOutputStream | 写入字节数组的输出流 |
| ObjectOutputStream | 对象的输出流 |
| DataOutputStream | 包含写Java标准数据类型方法的输出流 |
| BufferedOutputStream | 缓冲输出流 |
| PrintStream | 包含print()和println()的输出流 |
OutputStream流类中包含一套所有输出都需要的方法,可以完成最基本的向输出流写入数据的功能。表10-8列出了其中常用的方法及说明。
| 方法 | 功能描述 |
|---|---|
| void close() | 关闭输出流 |
| void flush() | 强制清空缓冲区并执行向外设输出数据 |
| void write(int b) | 将参数b的低位字节写入到输出流 |
| void write(byte b[]) | 按顺序将数组b[]中的全部字节写入到输出流 |
| void write(byte b[], int off, int len) | 按顺序将数组b[]中第off+1个元素开始的len个数据写入到输出流 |
由于InputStream和OutputStream都是抽象类,所以在程序中创建的输入流对象一般是它们某个子类的对象,通过调用对象继承的read()和write()方法就可实现对相应外设的输入输出操作。
8.5 java面向字节流的应用
文件输入输出流
文件输入输出流 FileInputStream 和 FileOutputStream 负责完成对本地磁盘文件的顺序输入输出操作。
【例 10-5】通过程序创建一个文件,从键盘输入字符,当遇到字符“#”时结束,在屏幕上显示该文件的所有内容(查看源代码)。
运行后在程序目录建立一个名称为 ep10_5 的文件,运行结果如图 10-8 所示:
图 10-8 例 10_5 运行结果
FileDescriptor 是 java.io 中的一个类,该类不能实例化,其中包含三个静态成员:in、out 和err,分别对应于标准输入流、标准输出流和标准错误流,利用它们可以在标准输入输出流上建立文件输入输出流,实现键盘输入或屏幕输出操作。
【例 10-6】实现对二进制图形文件(.gif)的备份(查看源代码)。
运行后在程序目录备份了一个名称为 ep10_6_a.gif 的文件,运行结果如图 10-9 所示:
图 10-9 例 10_6 运行结果
过滤流
FilterInputStream 和 FileOutputStream 是 InputStream 和 OutputStream 的直接子类,分别实现了在数据的读、写操作的同时能对所传输的数据做指定类型或格式的转换,即可实现对二进制字节数据的理解和编码转换。
常用的两个过滤流是数据输入流 DataInputStream 和数据输出流 DataOutputStream。其构造方法为:
DataInputStream(InputStream in); //创建新输入流,从指定的输入流 in 读数据
DataOutputStream(OutputStream out); //创建新输出流,向指定的输出流 out 写数据
由于 DataInputStream 和 DataOutputStream 分别实现了 DataInput 和 DataOutput 两个接口(这两个接口规定了基本类型数据的输入输出方法)中定义的独立于具体机器的带格式的读写操作,从而实现了对不同类型数据的读写。由构造方法可以看出,输入输出流分别作为数据输入输出流的构造方法参数,即作为过滤流必须与相应的数据流相连。
DataInputStream 和 DataOutputStream 类提供了很多个针对不同类型数据的读写方法,具体内容读者可参看 Java 的帮助文档。
【例 10-7】将三个 int 型数字 100,0,-100 写入数据文件 ep10_6.dat 中(查看源代码)。
运行后在程序目录中生成数据文件 ep10_7.dat,用文本编辑器打开后发现内容为二进制的:
00 00 00 64 00 00 00 00 FF FF FF 9C。
【例 10-8】读取数据文件 ep10_6.dat 中的三个 int 型数字,求和并显示(查看源代码)。
运行结果:
三个数的和为:0
readInt 方法可以从输入输出流中读入 4 个字节并将其作为 int 型数据直接参与运算。由于已经知道文件中有 3 个数据,所以可以使用 3 个读入语句,但若只知道文件中是 int 型数据而不知道数据的个数时该怎么办呢?因为 DataInputStream 的读入操作如遇到文件结尾就会抛出 EOFException 异常,所以可将读操作放入 try 中。
try{
while(true)
sum+=a.readInt();
}
catch(EOFException e){
System.out.pritnln("三个数的和为:"+sum);
a.close();
}
EOFException 是 IOException 的子类,只有文件结束异常时才会被捕捉到,但如果没有读到文件结尾,在读取过程中出现异常就属于 IOException。
【例 10-9】从键盘输入一个整数,求该数的各位数字之和(查看源代码)。
运行结果:
请输入一个整数:26
842403082 的各位数字之和=31
需要注意的是,输入的数据 26 为变成了 842403082,原因在于输入数据不符合基本类型数据的格式,从键盘提供的数据是字符的字节码表示方式,若输入 26,只代表 2 和 6 两个字符的字节数据,而不是代表整数 26 的字节码。
若要从键盘得到整数需要先读取字符串,再利用其他方法将字符串转化为整数。
标准输入输出
System.in、System.out、System.err 这 3 个标准输入输流对象定义在 java.lang.System 包中,这 3 个对象在 Java 源程序编译时会被自动加载。
- 标准输入:标准输入 System.in 是 BufferedInputStream 类的对象,当程序需要从键盘上读入数据时,只需要调用 System.in 的 read()方法即可,该方法从键盘缓冲区读入一个字节的二进制数据,返回以此字节为低位字节,高位字节为 0 的整型数据。
- 标准输出:标准输出 System.out 是打印输出流 PrintStream 类的对象。PrintStream 类是过滤输出流类 FilterOutputStream 的一个子类,其中定义了向屏幕输出不同类型数据的方法print()和 println()。
- 标准错误输出:System.err 用于为用户显示错误信息,也是由 PrintStream 类派生出来的错误流。Err 流的作用是使 print()和 println()将信息输出到 err 流并显示在屏幕上,以方便用户使用和调试程序。
【例 10-10】输入一串字符显示出来,并显示 System.in 和 System.out 所属的类(查看源代码)。
运行结果如图 10-10 所示:
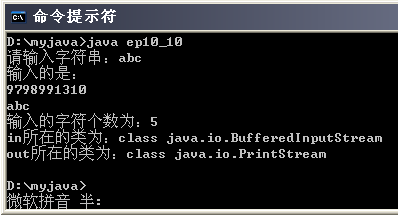
图 10-10 例 10_10 运行结果
需要注意的是,输入了 3 个字符按回车后,输出的结果显示为 5 个字符。这是由于 Java 中回车被当作两个字符,一个是 ASCⅡ为 13 的回车符,一个是值为 10 的换行符。程序中 getClass()和 ToString()是 Object 类的方法,作用分别是返回当前对象所对应的类和返回当前对象的字符串表示。
8.6 java中文件与目录管理
目录是管理文件的特殊机制,同类文件保存在同一个目录下不仅可以简化文件管理,而且还可以提高工作效率。Java 语言在 java.io 包中定义了一个 File 类专门用来管理磁盘文件和目录。
每个 File 类对象表示一个磁盘文件或目录,其对象属性中包含了文件或目录的相关信息。通过调用 File 类提供的各种方法,能够创建、删除、重名名文件、判断文件的读写权限以及是否存在,设置和查询文件的最近修改时间等。不同操作系统具有不同的文件系统组织方式,通过使用 File 类对象,Java 程序可以用与平台无关的、统一的方式来处理文件和目录。
创建 File 类的对象
创建 File 类对象需要给出其所对应的文件名或目录名,File 类的构造方法如表 10-9 所示。
| 构造方法 | 功能描述 |
|---|---|
| public File(String path) | 指定与 File 对象关联的文件或目录名,path 可以包含路径及文件和目录名 |
| public File(String path, String name) | 以 path 为路径,以 name 为文件或目录名创建 File 对象 |
| public File(File dir, String name) | 用现有的 File 对象 dir 作为目录,以 name 作为文件或目录名创建 File 对象 |
| public File(UR ui) | 使用给定的统一资源定位符来定位文件 |
在使用 File 类的构造方法时,需要注意下面几点:
(1)path 参数可以是绝对路径,也可以是相对路径,也可以是磁盘上的某个目录。
( 2)由于不同操作系统使用的目录分隔符不同,可以使用 System 类的一个静态变量System.dirSep,来实现在不同操作系统下都通用的路径。如:
"d:"+System.dirSep+"myjava"+System.dirSep+"file"
获取属性和操作
借助 File 对象,可以获取文件和相关目录的属性信息并可以对其进行管理和操作。表 10-10列出了其常用的方法及说明。
| 方法 | 功能描述 |
|---|---|
| boolean canRead() | 如果文件可读,返回真,否则返回假 |
| boolean canWrite() | 如果文件可写,返回真,否则返回假 |
| boolean exists() | 判断文件或目录是否存在 |
| boolean createNewFile() | 若文件不存在,则创建指定名字的空文件,并返回真,若不存在返回假 |
| boolean isFile() | 判断对象是否代表有效文件 |
| boolean isDirectory() | 判断对象是否代表有效目录 |
| boolean equals(File f) | 比较两个文件或目录是否相同 |
| string getName() | 返回文件名或目录名的字符串 |
| string getPath() | 返回文件或目录路径的字符串 |
| long length() | 返回文件的字节数,若 File 对象代表目录,则返回 0 |
| long lastModified() | 返回文件或目录最近一次修改的时间 |
| String[] list() | 将目录中所有文件名保存在字符串数组中并返回,若 File 对象不是目录返回 null |
| boolean delete() | 删除文件或目录,必须是空目录才能删除,删除成功返回真,否则返回假 |
| boolean mkdir() | 创建当前目录的子目录,成功返回真,否则返回假 |
| boolean renameTo(File newFile) | 将文件重命名为指定的文件名 |
【例 10-11】判断输入的绝对路径是代表一个文件或一个目录。若是文件输出此文件的绝对路径,并判断此文件的文件属性(是否可读写或隐藏);若是目录则输出该目录下所有文件(不包括隐藏文件)(查看源代码)。
运行结果如图 10-11 所示:
图 10-11 输入一个文件路径后例 10_11 的运行结果
Java.io 包提供了 RandomAccessFile 类用于随机文件的创建和访问。使用这个类,可以跳转到文件的任意位置读写数据。程序可以在随机文件中插入数据,而不会破坏该文件的其他数据。此外,程序也可以更新或删除先前存储的数据,而不用重写整个文件。
RandomAccessFile类是Object类的直接子类,包含两个主要的构造方法用来创 建RandomAccessFile 的对象,如表 10-11 所示。
| 构造方法 | 功能描述 |
|---|---|
| public RandomAccessFile(String name, String mode) | 指定随机文件流对象所对应的文件名,以 mode 表示对文件的访问模式 |
| public RandomAccessFile (File file, String mode) | 以 file 指定随机文件流对象所对应的文件名,以 mode 表示访问模式 |
需要注意的是,mode 表示所创建的随机读写文件的操作状态,其取值包括:
- r:表示以只读方式打开文件。
- rw:表示以读写方式打开文件,使用该模式只用一个对象即可同时实现读写操作。
表 10-12 列出了 RandowAccessFile 类常用的方法及说明。
| 方法 | 功能描述 |
|---|---|
| long length() | 返回文件长度 |
| void seek(long pos) | 移动文件位置指示器,pos 指定从文件开头的偏离字节数 |
| int skipBytes(int n) | 跳过 n 个字节,返回数为实际跳过的字节数 |
| int read() | 从文件中读取一个字节,字节的高 24 位为 0,若遇到文件结尾,返回-1 |
| final byte readByte() | 从文件中读取带符号的字节值 |
| final char readChar() | 从文件中读取一个 Unicode 字符 |
| final void writeChar(inte c) | 写入一个字符,两个字节 |
【例 10-12】模仿系统日志,将数据写入到文件尾部。
//********** ep10_12.java ********** import java.io.*; class ep10_12{ public static void main(String args[]) throws IOException{ try{ BufferedReader in=new BufferedReader(new InputStreamReader(System.in)); String s=in.readLine(); RandomAccessFile myFile=new RandomAccessFile("ep10_12.log","rw"); // myFile.seek(myFile.length()); //移动到文件结尾 myFile.writeBytes(s+"\n"); //写入数据 myFile.close(); } catch(IOException e){} } }
程序运行后在目录中建立一个 ep10_12.log 的文件,每次运行时输入的内容都会在该文件内容的结尾处添加。
8.8 java中文件的压缩处理
Java.util.zip 包中提供了可对文件的压缩和解压缩进行处理的类,它们继承自字节流类OutputSteam 和 InputStream。其中 GZIPOutputStream 和 ZipOutputStream 可分别把数据压缩成 GZIP 和 Zip 格式,GZIPInpputStream 和 ZipInputStream 又可将压缩的数据进行还原。
将文件写入压缩文件的一般步骤如下:
- 生成和所要生成的压缩文件相关联的压缩类对象。
- 压缩文件通常不只包含一个文件,将每个要加入的文件称为一个压缩入口,使用ZipEntry(String FileName)生成压缩入口对象。
- 使用 putNextEntry(ZipEntry entry)将压缩入口加入压缩文件。
- 将文件内容写入此压缩文件。
- 使用 closeEntry()结束目前的压缩入口,继续下一个压缩入口。
将文件从压缩文件中读出的一般步骤如下:
- 生成和所要读入的压缩文件相关联的压缩类对象。
- 利用 getNextEntry()得到下一个压缩入口。
【例 10-13】输入若干文件名,将所有文件压缩为“ep10_13.zip”,再从压缩文件中解压并显示。
//********** ep10_13.java ********** import java.io.*; import java.util.*; import java.util.zip.*; class ep10_13{ public static void main(String args[]) throws IOException{ FileOutputStream a=new FileOutputStream("ep10_13.zip"); //处理压缩文件 ZipOutputStream out=new ZipOutputStream(new BufferedOutputStream(a)); for(int i=0;i<args.length;i++){ //对命令行输入的每个文件进行处理 System.out.println("Writing file"+args[i]); BufferedInputStream in=new BufferedInputStream(new FileInputStream(args[i])); out.putNextEntry(new ZipEntry(args[i])); //设置 ZipEntry 对象 int b; while((b=in.read())!=-1) out.write(b); //从源文件读出,往压缩文件中写入 in.close(); } out.close(); //解压缩文件并显示 System.out.println("Reading file"); FileInputStream d=new FileInputStream("ep10_13.zip"); ZipInputStream inout=new ZipInputStream(new BufferedInputStream(d)); ZipEntry z; while((z=inout.getNextEntry())!=null){ //获得入口 System.out.println("Reading file"+z.getName()); //显示文件初始名 int x; while((x=inout.read())!=-1) System.out.write(x); System.out.println(); } inout.close(); } }
例 10-13 运行后,在程序目录建立一个 ep10_13.zip 的压缩文件,使用解压缩软件(如 WinRAR等),可以将其打开。命令提示符下,程序运行结果如图 10-12 所示:
图 10-12 例 10_13 运行结果
九◐ java 常用类库、向量与哈希
9.1 java基础类库
Java 的类库是 Java 语言提供的已经实现的标准类的集合,是 Java 编程的 API(Application Program Interface),它可以帮助开发者方便、快捷地开发 Java 程序。这些类根据实现的功能不同,可以划分为不同的集合,每个集合组成一个包,称为类库。Java 类库中大部分都是由Sun 公司提供的,这些类库称为基础类库。
Java 语言中提供了大量的类库共程序开发者来使用,了解类库的结构可以帮助开发者节省大量的编程时间,而且能够使编写的程序更简单更实用。Java 中丰富的类库资源也是 Java 语言的一大特色,是 Java 程序设计的基础。
Java 常用包的简单介绍如下:
- java.lang 包:主要含有与语言相关的类。java.lang 包由解释程序自动加载,不需要显示说明。
- java.io 包:主要含有与输入/输出相关的类,这些类提供了对不同的输入和输出设备读写数据的支持,这些输入和输出设备包括键盘、显示器、打印机、磁盘文件等。
- java.util 包:包括许多具有特定功能的类,有日期、向量、哈希表、堆栈等,其中 Date类支持与时间有关的操作。
- java.swing 包和 java.awt 包:提供了创建图形用户界面元素的类。通过这些元素,编程者可以控制所写的 Applet 或 Application 的外观界面。包中包含了窗口、对话框、菜单等类。
- java.net 包:含有与网络操作相关的类,如 TCP Scokets、URL 等工具。
- java.applet 包:含有控制 HTML 文档格式、应用程序中的声音等资源的类,其中 Applet类是用来创建包含于 HTML 的 Applet 必不可少的类。
- java.beans 包:定义了应用程序编程接口(API),Java Beans 是 Java 应用程序环境的中性平台组件结构。
9.2 java Object类
Object 类位于 java.lang 包中,是所有 Java 类的祖先,Java 中的每个类都由它扩展而来。
定义Java类时如果没有显示的指明父类,那么就默认继承了 Object 类。例如:
public class Demo{ // ... }
实际上是下面代码的简写形式:
public class Demo extends Object{ // ... }
在Java中,只有基本类型不是对象,例如数值、字符和布尔型的值都不是对象,所有的数组类型,不管是对象数组还是基本类型数组都是继承自 Object 类。
Object 类定义了一些有用的方法,由于是根类,这些方法在其他类中都存在,一般是进行了重载或覆盖,实现了各自的具体功能。
equals() 方法
Object 类中的 equals() 方法用来检测一个对象是否等价于另外一个对象,语法为:
public boolean equals(Object obj)
例如:
obj1.equals(obj2);
在Java中,数据等价的基本含义是指两个数据的值相等。在通过 equals() 和“==”进行比较的时候,引用类型数据比较的是引用,即内存地址,基本数据类型比较的是值。
注意:
- equals()方法只能比较引用类型,“==”可以比较引用类型及基本类型。
- 当用 equals() 方法进行比较时,对类 File、String、Date 及包装类来说,是比较类型及内容而不考虑引用的是否是同一个实例。
- 用“==”进行比较时,符号两边的数据类型必须一致(可自动转换的数据类型除外),否则编译出错,而用 equals 方法比较的两个数据只要都是引用类型即可。
hashCode() 方法
散列码(hashCode)是按照一定的算法由对象得到的一个数值,散列码没有规律。如果 x 和 y 是不同的对象,x.hashCode() 与 y.hashCode() 基本上不会相同。
hashCode() 方法主要用来在集合中实现快速查找等操作,也可以用于对象的比较。
在 Java 中,对 hashCode 的规定如下:
- 在同一个应用程序执行期间,对同一个对象调用 hashCode(),必须返回相同的整数结果——前提是 equals() 所比较的信息都不曾被改动过。至于同一个应用程序在不同执行期所得的调用结果,无需一致。
- 如果两个对象被 equals() 方法视为相等,那么对这两个对象调用 hashCode() 必须获得相同的整数结果。
- 如果两个对象被 equals() 方法视为不相等,那么对这两个对象调用 hashCode() 不必产生不同的整数结果。然而程序员应该意识到,对不同对象产生不同的整数结果,有可能提升hashTable(后面会学到,集合框架中的一个类)的效率。
简单地说:如果两个对象相同,那么它们的 hashCode 值一定要相同;如果两个对象的 hashCode 值相同,它们并不一定相同。在 Java 规范里面规定,一般是覆盖 equals() 方法应该连带覆盖 hashCode() 方法。
toString() 方法
toString() 方法是 Object 类中定义的另一个重要方法,是对象的字符串表现形式,语法为:
public String toString()
返回值是 String 类型,用于描述当前对象的有关信息。Object 类中实现的 toString() 方法是返回当前对象的类型和内存地址信息,但在一些子类(如 String、Date 等)中进行了 重写,也可以根据需要在用户自定义类型中重写 toString() 方法,以返回更适用的信息。
除显式调用对象的 toString() 方法外,在进行 String 与其它类型数据的连接操作时,会自动调用 toString() 方法。
以上几种方法,在Java中是经常用到的,这里仅作简单介绍,让大家对Object类和其他类有所了解,详细说明请参考 Java API 文档。
9.3 java语言包(java.lang)简介
Java语言包(java.lang)定义了Java中的大多数基本类,由Java语言自动调用,不需要显示声明。该包中包含了Object类,Object类是整个类层次结构的根结点,同时还定义了基本数据类型的类,如:String、Boolean、Byter、Short等。这些类支持数字类型的转换和字符串的操作等,下面将进行简单介绍。
Math类
Math类提供了常用的数学运算方法以及Math.PI和Math.E两个数学常量。该类是final的,不能被继承,类中的方法和属性全部是静态,不允许在类的外部创建Math类的对象。因此,只能使用Math类的方法而不能对其作任何更改。表8-1列出了Math类的主要方法。
| 方法 | 功能 |
|---|---|
| int abs(int i) | 求整数的绝对值(另有针对long、float、double的方法) |
| double ceil(double d) | 不小于d的最小整数(返回值为double型) |
| double floor(double d) | 不大于d的最大整数(返回值为double型) |
| int max(int i1,int i2) | 求两个整数中最大数(另有针对long、float、double的方法) |
| int min(int i1,int i2) | 求两个整数中最小数(另有针对long、float、double的方法) |
| double random() | 产生0~1之间的随机数 |
| int round(float f) | 求最靠近f的整数 |
| long round(double d) | 求最靠近d的长整数 |
| double sqrt(double a) | 求平方根 |
| double sin(double d) | 求d的sin值(另有求其他三角函数的方法如cos,tan,atan) |
| double log(double x) | 求自然对数 |
| double exp(double x) | 求e的x次幂(ex) |
| double pow(double a, double b) | 求a的b次幂 |
【例8-2】产生10个10~100之间的随机整数。
//********** ep8_2.java ********** class ep8_2{ public static void main(String args[]){ int a; System.out.print("随机数为:"); for(int i=1;i<=10;i++){ a=(int)((100-10+1)*Math.random()+10); System.out.print(" "+a); } System.out.println(); } }
运行结果: 随机数为:12 26 21 68 56 98 22 69 68 31
由于产生的是随机数,例8-2每次运行的结果都不会相同。若要产生[a,b]之间的随机数其通式为:
(b-a+1)*Math.random()+a
字符串类
字符串是字符的序列。在 Java 中,字符串无论是常量还是变量都是用类的对象来实现的。java.lang 提供了两种字符串类:String 类和 StringBuffer 类。
1.String 类
按照 Java 语言的规定,String 类是 immutable 的 Unicode 字符序列,其作用是实现一种不能改变的静态字符串。例如,把两个字符串连接起来的结果是生成一个新的字符串,而不会使原来的字符串改变。实际上,所有改变字符串的结果都是生成新的字符串,而不是改变原来字符串。
字符串与数组的实现很相似,也是通过 index 编号来指出字符在字符串中的位置的,编号从0 开始,第 2 个字符的编号为 1,以此类推。如果要访问的编号不在合法的范围内,系统会产生 StringIndexOutOfBoundsExecption 异常。如果 index 的值不是整数,则会产生编译错误。
String 类提供了如表 8-2 所示的几种字符串创建方法。
| 方法 | 功能 |
|---|---|
| String s=”Hello!” | 用字符串常量自动创建 String 实例。 |
| String s=new String(String s) | 通过 String 对象或字符串常量传递给构造方法。 |
| public String(char value[]) | 将整个字符数组赋给 String 构造方法。 |
| public String(char value[], int offset, int count) | 将字符数组的一部分赋给 String 构造方法,offset 为起始下标,count为子数组长度。 |
2.StringBuffer 类
String 类不能改变字符串对象中的内容,只能通过建立一个新串来实现字符串的变化。如果字符串需要动态改变,就需要用 StringBuffer 类。StringBuffer 类主要用来实现字符串内容的添加、修改、删除,也就是说该类对象实体的内存空间可以自动改变大小,以便于存放一个可变的字符序列。
| 构造方法 | 说明 |
|---|---|
| StringBuffer() | 使用该无参数的构造方法创建的 StringBuffer 对象,初始容量为 16 个字符,当对象存放的字符序列大于 16 个字符时,对象的容量自动增加。该对象可以通过 length()方法获取实体中存放的字符序列的长度,通过 capacity()方法获取当前对象的实际容量。 |
| StringBuffer(int length) | 使用该构造方法创建的 StringBuffer 对象,其初始容量为参数 length 指定的字符个数,当对象存放的字符序列的长度大于 length 时,对象的容量自动增加,以便存放所增加的字符。 |
| StringBuffer(Strin str) | 使用该构造方法创建的 StringBuffer 对象,其初始容量为参数字符串 str 的长度再加上 16 个字符。 |
| 方法 | 说明 |
|---|---|
| append() | 使用 append() 方法可以将其他 Java 类型数据转化为字符串后再追加到 StringBuffer 的对象中。 |
| insert(int index, String str) | insert() 方法将一个字符串插入对象的字符序列中的某个位置。 |
| setCharAt(int n, char ch) | 将当前 StringBuffer 对象中的字符序列 n 处的字符用参数 ch 指定的字符替换,n 的值必须是非负的,并且小于当前对象中字符串序列的长度。 |
| reverse() | 使用 reverse()方法可以将对象中的字符序列翻转。 |
| delete(int n, int m) | 从当前 StringBuffer 对象中的字符序列删除一个子字符序列。这里的 n 指定了需要删除的第一个字符的下标,m 指定了需要删除的最后一个字符的下一个字符的下标,因此删除的子字符串从 n~m-1。 |
| replace(int n, int m, String str) | 用 str 替换对象中的字符序列,被替换的子字符序列由下标 n 和 m 指定。 |
9.4 日期和时间类简介
Java 的日期和时间类位于 java.util 包中。利用日期时间类提供的方法,可以获取当前的日期和时间,创建日期和时间参数,计算和比较时间。
Date 类
Date 类是 Java 中的日期时间类,其构造方法比较多,下面是常用的两个:
- Date():使用当前的日期和时间初始化一个对象。
- Date(long millisec):从1970年01月01日00时(格林威治时间)开始以毫秒计算时间,计算 millisec 毫秒。如果运行 Java 程序的本地时区是北京时区(与格林威治时间相差 8 小时),Date dt1=new Date(1000);,那么对象 dt1 就是1970年01月01日08时00分01秒。
请看一个显示日期时间的例子:
import java.util.Date; public class Demo{ public static void main(String args[]){ Date da=new Date(); //创建时间对象 System.out.println(da); //显示时间和日期 long msec=da.getTime(); System.out.println("从1970年1月1日0时到现在共有:" + msec + "毫秒"); } }
运行结果:
Mon Feb 05 22:50:05 CST 2007
从1970年1月1日0时到现在共有:1170687005390 毫秒
一些比较常用的 Date 类方法:
| 方法 | 功能 |
|---|---|
| boolean after(Date date) | 若调用 Date 对象所包含的日期比 date 指定的对象所包含的日期晚,返回 true,否则返回 false。 |
| boolean before(Date date) | 若调用 Date 对象所包含的日期比 date 指定的对象所包含的日期早,返回 true,否则返回 false。 |
| Object clone() | 复制调用 Date 对象。 |
| int compareTo(Date date) | 比较调用对象所包含的日期和指定的对象包含的日期,若相等返回 0;若前者比后者早,返回负值;否则返回正值。 |
| long getTime() | 以毫秒数返回从 1970 年 01 月 01 日 00 时到目前的时间。 |
| int hashCode() | 返回调用对象的散列值。 |
| void setTime(long time) | 根据 time 的值,设置时间和日期。time 值从 1970 年 01 月 01 日 00 时开始计算。 |
| String toString() | 把调用的 Date 对象转换成字符串并返回结果。 |
| public Static String valueOf(type variable) | 把 variable 转换为字符串。 |
Date 对象表示时间的默认顺序是星期、月、日、小时、分、秒、年。若需要修改时间显示的格式可以使用“SimpleDateFormat(String pattern)”方法。
例如,用不同的格式输出时间:
import java.util.Date; import java.text.SimpleDateFormat; public class Demo{ public static void main(String args[]){ Date da=new Date(); System.out.println(da); SimpleDateFormat ma1=new SimpleDateFormat("yyyy 年 MM 月 dd 日 E 北京时间"); System.out.println(ma1.format(da)); SimpleDateFormat ma2=new SimpleDateFormat("北京时间:yyyy 年 MM 月 dd 日 HH 时 mm 分 ss 秒"); System.out.println(ma2.format(-1000)); } }
运行结果:
Sun Jan 04 17:31:36 CST 2015
2015 年 01 月 04 日 星期日 北京时间
北京时间:1970 年 01 月 01 日 07 时 59 分 59 秒
Calendar 类
抽象类 Calendar 提供了一组方法,允许把以毫秒为单位的时间转换成一些有用的时间组成部分。Calendar 不能直接创建对象,但可以使用静态方法 getInstance() 获得代表当前日期的日历对象,如:
Calendar calendar=Calendar.getInstance();
该对象可以调用下面的方法将日历翻到指定的一个时间:
void set(int year,int month,int date); void set(int year,int month,int date,int hour,int minute); void set(int year,int month,int date,int hour,int minute,int second);
若要调用有关年份、月份、小时、星期等信息,可以通过调用下面的方法实现:
int get(int field);
其中,参数 field 的值由 Calendar 类的静态常量决定。其中:YEAR 代表年,MONTH 代表月,HOUR 代表小时,MINUTE 代表分,如:
calendar.get(Calendar.MONTH);
如果返回值为 0 代表当前日历是一月份,如果返回 1 代表二月份,依此类推。
由 Calendar 定义的一些常用方法如下表所示:
| 方法 | 功能 |
|---|---|
| abstract void add(int which,int val) | 将 val 加到 which 所指定的时间或者日期中,如果需要实现减的功能,可以加一个负数。which 必须是 Calendar 类定义的字段之一,如 Calendar.HOUR |
| boolean after(Object calendarObj) | 如果调用 Calendar 对象所包含的日期比 calendarObj 指定的对象所包含的日期晚,返回 true,否则返回 false |
| boolean before(Object calendarObj) | 如果调用 Calendar 对象所包含的日期比 calendarObj 指定的对象所包含的日期早,返回 true,否则返回 false |
| final void clear() | 对调用对象包含的所有时间组成部分清零 |
| final void clear(int which) | 对调用对象包含的 which 所指定的时间组成部分清零 |
| boolean equals(Object calendarObj) | 如果调用 Calendar 对象所包含的日期和 calendarObj 指定的对象所包含的日期相等,返回 true,否则返回 false |
| int get(int calendarField) | 返回调用 Calendar 对象的一个时间组成部分的值,这个组成部分由 calendarField指定,可以被返回的组成部分如:Calendar.YEAR,Calendar.MONTH 等 |
| static Calendar getInstance() | 返回使用默认地域和时区的一个 Calendar 对象 |
| final Date getTime() | 返回一个和调用对象时间相等的 Date 对象 |
| final boolean isSet(int which) | 如果调用对象所包含的 which 指定的时间部分被设置了,返回 true,否则返回 false |
| final void set(int year,int month) | 设置调用对象的各种日期和时间部分 |
| final void setTime(Date d) | 从 Date 对象 d 中获得日期和时间部分 |
| void setTimeZone(TimeZone t) | 设置调用对象的时区为 t 指定的那个时区 |
GregorianCalendar 类
GregorianCalendar 是一个具体实现 Calendar 类的类,该类实现了公历日历。Calendar 类的 getInstance() 方法返回一个 GregorianCalendar,它被初始化为默认的地域和时区下的当前日期和时间。
GregorianCalendar 类定义了两个字段:AD 和 BC,分别代表公元前和公元后。其默认的构造方法 GregorianCalendar() 以默认的地域和时区的当前日期和时间初始化对象,另外也可以指定地域和时区来建立一个 GregorianCalendar 对象,例如:
GregorianCalendar(Locale locale);
GregorianCalendar(TimeZone timeZone);
GregorianCalendar(TimeZone timeZone,Locale locale);
GregorianCalendar 类提供了 Calendar 类中所有的抽象方法的实现,同时还提供了一些附加的方法,其中用来判断闰年的方法为:
Boolean isLeapYear(int year);
如果 year 是闰年,该方法返回 true,否则返回 false。
9.5 java向量(vector)及其应用
向量和数组相似,都可以保存一组数据(数据列表)。但是数组的大小是固定的,一旦指定,就不能改变,而向量却提供了一种类似于“动态数组”的功能,向量与数组的重要区别之一就是向量的容量是可变的。
可以在向量的任意位置插入不同类型的对象,无需考虑对象的类型,也无需考虑向量的容量。
向量和数组分别适用于不同的场合,一般来说,下列场合更适合于使用向量:
- 如果需要频繁进行对象的插入和删除工作,或者因为需要处理的对象数目不定。
- 列表成员全部都是对象,或者可以方便的用对象表示。
- 需要很快确定列表内是否存在某一特定对象,并且希望很快了解到对象的存放位置。
向量作为一种对象提供了比数组更多的方法,但需要注意的是,向量只能存储对象,不能直接存储简单数据类型,因此下列场合适用于使用数组:
- 所需处理的对象数目大致可以确定。
- 所需处理的是简单数据类型。
向量的使用
向量必须要先创建后使用,向量的大小是向量中元素的个数,向量的容量是被分配用来存储元素的内存大小,其大小总是大于向量的大小。下面是 Vector 的构造方法:Vector(); //①创建空向量,初始大小为 10 Vector(int initialCapacity); //②创建初始容量为 capacity 的空向量 Vector(int initialCapacity,int capacityIncrement); //③创建初始容量为 initialCapacity,增量为 capacityIncrement 的空向量
使用第②种方式,会创建一个初始容量(即向量可存储数据的大小)为 initialCapacity 的空向量,当真正存放的数据超过该容量时,系统会自动扩充容量,每次增加一倍。
使用第③中方式,会创建一个初始容量为 initialCapacity 的空向量,当真正存放的数据超过该容量时,系统每次会自动扩充 capacityIncrement。如果 capacityIncrement 为0,那么每次增加一倍,。
通过分配多于所需的内存空间,向量减少了必须的内存分配的数目。这样能够有效地减少分配所消耗的时间,每次分配的额外空间数目将由创建向量时指定的增量所决定。
除了构造方法外,向量类还提供了三个属性变量,分别为:
protected int capacityIncrement; //当向量大小不足时,所用的增量大小 protected int elementCount; //向量的元素个数 protected Object elementData[]; //向量成员数据所用的缓冲
| 方法 | 功能 |
|---|---|
| void addElement(Object element) | 将给定对象 element 增加到向量末尾 |
| int capacity() | 返回向量容量 |
| boolean contains(Object element) | 若向量中包含了 element 返回 true,否则返回 false |
| void copyInto(Object Array[]) | 将向量元素复制到指定数组 |
| synchronized Object elementAt(int index) | 返回指定下标的元素,若下标非法,抛出 ArrayIndexOutOfBoundsExecption 异常 |
| void ensureCapacity(int size) | 将向量的最小容量设为 size |
| synchronized Object firstElement() | 返回向量的第一个元素,若向量为空,抛出 NoSuchElementException 异常 |
| int indexOf(Object element) | 返回 element 的下标,若对象不存在返回-1 |
| int indexOf (Object element,int start) | 从指定位置(start)开始搜索向量,返回对象所对应的下标值,若未找到返回-1 |
| void insertElementAt (Object obj,int index) | 将给定的对象插入到指定的下标处 |
| boolean isEmpty() | 若向量不包括任何元素,返回 true,否则返回 false |
| synchronized Object lastElement() | 返回向量的最后一个元素,若向量为空,抛出 NoSuchElementException 异常 |
| int lastIndexOf(Object element) | 从向量末尾向前搜索向量,返回对象的下标值 |
| int lastIndexOf(Object element,int start) | 从指定位置开始向前搜索向量,返回给定对象的下标值,若未找到返回-1 |
| void removeAllElements() | 删除向量中的所有对象,向量变成空向量 |
| boolean removeElement(Object element) | 从向量中删除指定对象 element,若给定的对象在向量中保存多次,则只删除其第一个实例,如果删除成功,返回 true,如果没发现对象,则返回 false |
| void removeElementAt(int index) | 删除由 index 指定位置处的元素 |
| void setElementAt(Object obj,int index) | 将给定对象存放到给定下标处,该下标处的原有对象丢失 |
| void setSize(int size) | 将向量中的元素个数设为 size,如果新的长度小于原来的长度,元素将丢失,若新的长度大于原来的长度,则在其后增加 null 元素 |
| int size() | 返回向量中当前元素的个数 |
| String toString() | 将向量转换成字符串 |
| void trimToSize() | 将向量的容量设为与当前拥有的元素个数相等 |
Vector vector=new Vector();
9.6 java哈希表及其应用
哈希表也称为散列表,是用来存储群体对象的集合类结构。
什么是哈希表
数组和向量都可以存储对象,但对象的存储位置是随机的,也就是说对象本身与其存储位置之间没有必然的联系。当要查找一个对象时,只能以某种顺序(如顺序查找或二分查找)与各个元素进行比较,当数组或向量中的元素数量很多时,查找的效率会明显的降低。
一种有效的存储方式,是不与其他元素进行比较,一次存取便能得到所需要的记录。这就需要在对象的存储位置和对象的关键属性(设为 k)之间建立一个特定的对应关系(设为 f),使每个对象与一个唯一的存储位置相对应。在查找时,只要根据待查对象的关键属性 k 计算f(k)的值即可。如果此对象在集合中,则必定在存储位置 f(k)上,因此不需要与集合中的其他元素进行比较。称这种对应关系 f 为哈希(hash)方法,按照这种思想建立的表为哈希表。
Java 使用哈希表类(Hashtable)来实现哈希表,以下是与哈希表相关的一些概念:
- 容量(Capacity):Hashtable 的容量不是固定的,随对象的加入其容量也可以自动增长。
- 关键字(Key):每个存储的对象都需要有一个关键字,key 可以是对象本身,也可以是对象的一部分(如某个属性)。要求在一个 Hashtable 中的所有关键字都是唯一的。
- 哈希码(Hash Code):若要将对象存储到 Hashtable 上,就需要将其关键字 key 映射到一个整型数据,成为 key 的哈希码。
- 项(Item):Hashtable 中的每一项都有两个域,分别是关键字域 key 和值域 value(存储的对象)。Key 和 value 都可以是任意的 Object 类型的对象,但不能为空。
- 装填因子(Load Factor):装填因子表示为哈希表的装满程度,其值等于元素数比上哈希表的长度。
哈希表的使用
哈希表类主要有三种形式的构造方法:
Hashtable(); //默认构造函数,初始容量为 101,最大填充因子 0.75 Hashtable(int capacity); Hashtable(int capacity,float loadFactor)
哈希表类的主要方法如表 8-6 所示。
| 方法 | 功能 |
|---|---|
| void clear() | 重新设置并清空哈希表 |
| boolean contains(Object value) | 确定哈希表内是否包含了给定的对象,若有返回 true,否则返回 false |
| boolean containsKey(Object key) | 确定哈希表内是否包含了给定的关键字,若有返回 true,否则返回 false |
| boolean isEmpty() | 确认哈希表是否为空,若是返回 true,否则返回 false |
| Object get(Object key) | 获取对应关键字的对象,若不存在返回 null |
| void rehash() | 再哈希,扩充哈希表使之可以保存更多的元素,当哈希表达到饱和时,系统自动调用此方法 |
| Object put(Object key,Object value) | 用给定的关键字把对象保存到哈希表中,此处的关键字和元素均不可为空 |
| Object remove(Object key) | 从哈希表中删除与给定关键字相对应的对象,若该对象不存在返回 null |
| int size() | 返回哈希表的大小 |
| String toString() | 将哈希表内容转换为字符串 |
哈希表的创建也可以通过 new 操作符实现。其语句为:
HashTable has=new HashTable();
【例 8-12】哈希表的遍历。
//********** ep8_12.java ********** import java.util.*; class ep8_12{ public static void main(String args[]){ Hashtable has=new Hashtable(); has.put("one",new Integer(1)); has.put("two",new Integer(2)); has.put("three",new Integer(3)); has.put("four",new Double(12.3)); Set s=has.keySet(); for(Iterator<String> i=s.iterator();i.hasNext();){ System.out.println(has.get(i.next())); } } }
运行结果:
2
1
3
12.3
2015年10月14日
瘋子java阅读笔记
--------------------

