
文本分类实战
分类任务
其实工程上对于文本分类的需求还是挺多的,主要可以分为下面两类,并对每类给了两个例子。
二分类
色情新闻分类 这是一个非平衡数据集的二分类问题,因为色情新闻数是远小于非色情新闻数的。
判断是否医疗Query 这个就关系到搜索变现了,还记得莆田系”事件吗?这个分类是很值钱的。
多分类
商品自动分类 每天商家都在上新,对这些新商品应该放到“服装“类目还是”数码“类目,人工搞肯定不划算了。
Query领域分类 这个是为了对准领域知识库,做更炫更”智能“的所谓“框计算”。
算法流程
数据标注
分类是有监督的学习,所以必然是需要标注数据的。刚开始肯定是需要找一些人,比如说运营同事提供手工标注一些数据的。有了这批种子数据,我们可以先训练一个分类器,用这个分类器做分类,后面的工作其实就相对轻松一点,可以使用一些半监督的方法来持续扩充标记数据集,并对其中不确信的部分再做人工标注。这种半人工半自动的方法,既大大减少了标记的工作量,又能快速扩大标记数据集。
特征抽取
分类是基于特征的,拿到数据后怎么抽取具有区分度的特征是关键的一步。我们使用的特征主要是基于Bag Of Word, 具体步骤如下:
1. 分词:jieba足够好了,主要还是对词库的维护。
2. N-gram:用到tri-gram就可以了。
3. term位置:主要是对query分类有用。
4. 特征权重:对短文本IDF够了,对长文本TF-IDF。
特征选择
词有很多,是不是每个都作为特征呢?不是,要去除不具区分性的特征以及会对分类起反作用的特征。特征选择条件如下:
1. 词频数限制: 在总的corpus里面出现次数小于一定阈值的要删掉
2. 停用词:停用词除了像”的“这样的通用的烂大街的词之外,每种应用场景需要维护自己的停用词表。比如说”三星“在商品分类上绝不是停用词,但在色情新闻分类上可以是停用词
3. feature filter: 对相对平衡的样本集,可以直接使用信息增益比(information gain ratio, IGR)来做。对不平衡的样本集(如色情新闻分类)用IGR就不合适了,可以用基于odds ratio的filter:
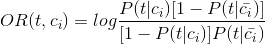
这边的smoothing可以用基于Expected Likelihood Estimation(ELE)的。用好这两个,感觉特征选择就差不多了。
分类器
首先说明一点的是,在浅层机器学习系统(相对于具有特征学习能力的深度学习而言),feature engineering往往比分类器选择更重要。在文本分类这个问题上, 我的实验结果是判别模型比较靠谱,下面两个结果差不多,可以任选一个使用。我自己在做BoW特征文本相关的任务时习惯选择Max Entropy。
1. SVM
2. Max Entropy
对于经典的垃圾邮件分类问题使用的Naive Bayes,结果并没有上述两种判别模型好。
还有一些人使用了基于决策树的方法,但是在这种特征向量比较稀疏的情况,不知道效果如何,没有试过。
训练与评估
在训练分类器时,我们采用10-fold交叉验证的方法,以防止单一验证集有偏。
评估指标是很平常的召回率、准确率、F1 score;对多分类还可以用confusion matrix。
坑
分词
分词从实用主义的角度来讲,主要在于维护词典。HMM还是CRF对最终结果的贡献并不如词典的贡献可见。另外针对应用场景,可能还需要自己额外做一些事情。比如说针对手机机型作一些基于正则的分词来把小米4变成一个词,而不是小米 4。这种分词粒度上的小trick是根据你的应用场景定的。
特征重要度
除了TF-IDF之外,根据应用场景的不同,有不同的特征重要度的要求。如Query会给名词和专有名词加大的权重,而色情新闻识别中形容词和名词同等重要。
有偏训练集
分类器的假设是样本数是大致均匀分布的,如果一类比其他类数据量大得过分,分类器很容易把其他类的数据推到大的类上去,以换取平均误差最小。这种情况下,我们的做法就是尝试不同的样本比例进行训练并在测试集上测试,选择结果最好的那个比例。
另外一个比较常用的方法就是设置meta cost,也就是为cost设置权重,比如说色情判成非色情损失就乘10。
这两种方式的最终目的是一样的,操作起来第一种更好些。
模型大小优化
有的时候模型大小有要求,比如说模型会推送给设备耗流量和设备内存, 比如说即使在云端整个系统也有内存要求,希望你优化。这时候主要有两个方法:
a. 特征选择。 加大特征选择的强度,比如说原来选Top 1000的,现在选Top 500,这个可类比为主成分分析,会降低模型的指标数据,所以是有损的。
b. 精简模型。 可以删除一些最终模型中的权重特别小或者为0的特征,再基于剩下来的特征重新训练个新模型。这个其实是feature warping。还可以使用正则化方法,加大正则化系数。
One More Thing…
term 扩展
这个尤其是对query,有的query特别短导致召回低。这个时候可以通过term扩展给他更多的同义,近义,共现词,增加召回。term扩展主要是基于下面要说的这类特征。
Distributed Representation
我们上面使用的特征向量是每个term或者term组合在向量中占一个坑的形式,这种方法能取得不错的结果。当它有一个致命弱点是它其实只是记住了一些词的组合关系,并不能真正表示这个词。一个例子就是”月亮“和”月球“这两个向量的距离其实跟”月亮“和”猫“的距离是一样的,这并不符合实际情况。为了使文本分类能够处理这种情况,需要distributed representation。主要有两类:
a. 基于主题模型的: pLSA, LDA等
b. 基于DNN的:word2vec等


