
centos Linux系统日常管理1 cpuinfo cpu核数 命令 w, vmstat, uptime ,top ,kill ,ps ,free,netstat ,sar, ulimit ,lsof ,pidof,dstat ,prlimit 第十四节课
centos Linux系统日常管理1 cpuinfo cpu核数 命令 w, vmstat, uptime ,top ,kill ,ps ,free,netstat ,sar, ulimit ,lsof ,pidof,dstat ,prlimit 第十四节课
上半节课
w
uptime
下半节课
top
kill命令
vmstat
ps
free
netstat
ulimit
sar
lsof
pidof
dstat
htop
监控系统状态命令:w, vmstat, uptime ,top
w
# w
12:27:16 up 16 min (运行天数), 2 users (当前系统登录用户数 如果要删除某个用户可以查看有多少用户登录了系统),
load average: 0.06, 0.03, 0.00 单位时间段内CPU平均消耗 ,上两位数就要注意了
三个数分别代表不同时间段的系统平均负载(一分钟、五分钟、十五分钟)
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root tty1 - 12:26 5.00s 0.01s 0.00s -bash (本地用户)
root pts/0 192.168.0.101 12:26 0.00s 0.07s 0.00s w (远程用户)

注意:load average的最大值不可能超过CPU逻辑核数,比如8逻辑核CPU,load average不可能达到9.00 ,上两位数就要注意了!
每次远程连接Linux都会显示w命令信息
15:18:09 up 4 days, 21:19, 2 users, load average: 0.00, 0.00, 0.00
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
steven pts/0 113.x.x.x 15:15 41.00s 0.01s 0.02s sshd: steven [priv]
steven pts/1 113.x.x.x 15:18 0.00s 0.01s 0.02s sshd: steven [priv]
ab(apache benchmark测试工具):测试apache
uptime
# uptime
14:43:50 up 2 days, 20:45, 1 user, load average: 0.00, 0.00, 0.00 ,上两位数就要注意了
下半节课
top
# top
top - 14:46:57当前时间 up 2 days, 20:48 已经运行了多少时间, 1 user, load average: 0.00, 0.00, 0.00 ,上两位数就要注意了
Tasks: 89 total 89个进程, 1 running, 88 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.3%sy, 0.0%ni, 99.7%id, 0.0%wa io等待cpu, 0.0%hi, 0.0%si, 0.0%st
Mem: 1922484k total 2G内存, 449604k used, 1472880k free, 166384k buffers
Swap: 0k total 无swap, 0k used, 0k free, 173156k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 19356 1492 1192 S 0.0 0.1 0:00.58 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
us:用户态
sy:内核态
wa:wait等待时间
id:空闲
ni:优先值
buffer:缓冲
cache:缓存
下面部分
PR:优先级
NI:NICE 优先值 -20~19 数值越小优先级越高,用户层概念 nice 值可调整的范围为 -20 ~ 19 # nice [-n 数字] command
VIRT:虚拟内存 RES+SWAP,包括mmap分配的内存http://mysql.taobao.org/monthly/2017/05/01/
RES:真正内存 没有被换出的, 要关注
SHR:共享内存
S:状态
%CPU:CPU百分比 top默认以CPU排序 8逻辑核CPU 当%CPU为800的时候 才说明CPU才完全占满
%MEM:内存百分比
TIME+:在CPU运行了多长时间
COMMAND:命令
用于动态监控进程所占系统资源,每隔3秒变一次。
RES 这一项为进程所占内存大小,而 %MEM 为使用内存百分比
按 “shift + m”, 可以按照内存使用大小排序。
按 “shift + p”, 可以按照CPU使用排序。
按数字 ‘1’ 可以列出各颗cpu的使用状态。
top -bn1 它表示非动态打印系统资源使用情况,可以用在shell脚本中
top -c 最右侧的命令可以显示更详细的信息 例如命令路径
kill命令
少使用 kill -9 进程ID
尽量用 killall 进程名
w,uptime,top显示的第一行都是一样的
vmstat
#vmstat 1 //每一秒打印一次 #vmstat 1 10 //每一秒打印一次 打印十次后结束打印
-t参数:执行vmstat命令,该命令将会在每一行输出后都带一个时间戳 vmstat -t 1 5
-s参数:将输出各种事件计数器和内存的统计信息。 vmstat -s
-d参数:将会输出所有磁盘的统计信息。 vmstat -d
-S和-M参数:(大写和MB)将会以MB为单位输出。vmstat默认以KB为单位输出统计信息。 vmstat -S -M 1 5
vmstat各指标含义:
--proc进程相关-------------------------------------------------------------------------------
r :run 表示运行和等待cpu时间片的进程数,如果长期大于服务器cpu的个数,则说明cpu不够用了;
b :表示等待资源的进程数,比如等待I/O, 内存等,这列的值如果长时间大于1,则需要关注一下了
--swap 交换分区相关的---------------------------------------------------------------------------
si :由交换区进入内存的数量; swap--》内存
so :由内存进入交换区的数量;
--io 磁盘---------------------------------------------------------------------------------------
bi :从块设备读取数据的量(读磁盘); 磁盘--》内存
bo: 从块设备写入数据的量(写磁盘);
--system 系统相关的-----------------------------------------------------------------------
in : 每秒的软中断次数,包含时钟中断;
cs : 每秒的上下文切换次数;
--cpu cpu相关的-----------------------------------------------------------------------
wa :表示I/O等待所占用cpu时间百分比.
us :用户态
sy :内核态
id :空闲
--------------------------------------------------------------------------------------
ps
ps 查看系统进程 process show,注意:ps命令只能查看进程不能查看线程!!!
-A 显示所有进程(等价于-e)(utility)
-a 显示一个终端的所有进程,除了会话引线
-C ps -C nginx 只显示某个程序的所有进程
-N 忽略选择。
-d 显示所有进程,但省略所有的会话引线(utility)
-x 显示没有控制终端的进程,同时显示各个命令的具体路径。dx不可合用。(utility)
-p pid 进程使用cpu的时间
-u uid or username 选择有效的用户id或者是用户名
-g gid or groupname 显示组的所有进程。
U username 显示该用户下的所有进程,且显示各个命令的详细路径。如:ps U zhang;(utility)
-f 全部列出,通常和其他选项联用。如:ps -fa or ps -fx and so on.,注意:ps命令只能查看进程不能查看线程!!!
-l 长格式(有F,wchan,C 等字段)
-L 列出栏位的相关信息
-j 作业格式
-o 用户自定义格式。
v 以虚拟存储器格式显示
s 以信号格式显示
-m 显示所有的线程
-H 显示进程的层次(和其它的命令合用,如:ps -Ha)(utility)
e 命令之后显示环境(如:ps -d e; ps -a e)(utility)
h 不显示第一行
ps aux / ps -elf
PID :进程的id,这个id很有用,在linux中内核管理进程就得靠pid来识别和管理某一个程序,
比如我想终止某一个进程,则用 ‘kill 进程的pid’有时并不能杀掉,则需要加一个-9选项 kill -9 进程pid
ps aux
%CPU 进程的cpu占用率
%MEM 进程的内存占用率
VSZ 进程所使用的虚存的大小(Virtual Size)
RSS 进程使用的驻留集大小或者是实际内存的大小,单位 KB。
ps -eo ppid,pid,user,args |grep mysql
1 7348 root /bin/sh /usr/local/mysql/bin/mysqld_safe --datadir=/data/mysql/mysql3306/data --pid-file=/data/mysql/mysql3306/tmp/mysql.pid
7348 8463 mysql /usr/local/mysql/bin/mysqld --basedir=/usr/local/mysql --datadir=/data/mysql/mysql3306/data --pid-file=/data/mysql/mysql3306/tmp/mysql.pid --socket=/data/mysql/mysql3306/tmp/mysql.sock
ps axjf
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
0 2 0 0 ? -1 S 0 0:00 [kthreadd]
2 3 0 0 ? -1 S 0 0:00 \_ [migration/0] #子进程
2 4 0 0 ? -1 S 0 0:18 \_ [ksoftirqd/0] #子进程
STAT :表示进程的状态,进程状态分为以下几种
D 不能中断的进程(通常为IO)
R 正在运行中的进程
S 已经中断的进程,系统中大部分进程都是这个状态
T 已经停止或者暂停的进程,如果我们正在运行一个命令,比如说 sleep 10 如果我们按一下ctrl -z 让他暂停,那么我们用ps查看就会显示T这个状态
X 已经死掉的进程(这个从来不会出现)
Z 僵尸进程,杀不掉,打不死的垃圾进程,占系统一小点资源,不过没有关系。如果太多,就有问题了,只能重启服务器解决。
< 高优先级进程
N 低优先级进程
L 在内存中被锁了内存分页
s 主进程
l 多线程进程
+ 在前台的进程
watchdog:监视非常重要的进程,发现死掉的话帮忙拉起重要进程
free
查看内存使用情况
-b 以Byte为单位显示内存使用情况。
-k 以KB为单位显示内存使用情况。
-m 以MB为单位显示内存使用情况。
-g 以GB为单位显示内存使用情况。
-o 不显示缓冲区调节列。
-s <间隔秒数> 持续观察内存使用状况。
-t 显示内存总和列。
-V 显示版本信息。
free 默认以k为单位显示
mem(total):内存总数;
mem(used):已经分配的内存; 并不是真正已用
mem(free):未分配的内存; 并不是真正剩余内存
mem(buffers):系统分配但未被使用的buffers;
mem(cached)系统分配但未被使用的cache
buffers/cache(used):实际使用的buffers与cache 总量,也是实际使用的内存;
buffers/cache(free):未被使用的buffers与cache和未被分配的内存之和,这就是系统 当前实际可用内存
buffers是即将要被写入磁盘的
cached是被从磁盘中读出来的
redhat7支持 free -h
系统启动的时候就会从内存拿出一部分内存作为buffers和cached
netstat
netstat 查看网络状况 三次握手 四次挥手
输出分为两部分:一个是TCP/IP网络部分,另一个是Unix socket部分
Unix socket是本机内的进程间通信,而且连接非常多
-n :显示ip ,不显示机器名
netstat -lnp 查看当前系统开启的端口以及socket,所有ip,比如十个ip,十个ip都监听
netstat -an 查看当前系统所有的连接状态
netstat -lntp 只有tcp,不列出socket
netstat -lnup 只有udp,不列出socket
netstat -an|awk '/ESTABLISHED/'|wc -l 检查机器并发
zabbix监听端口:10050
mysql监听端口:3306
nginx监听端口:80
stmp sendmail监听端口:25
sendmail和postifx都可以发邮件
sar
sysstat软件包包含sar、iostat、mpstat三个命令,iostat的cpu统计和磁盘统计跟sar命令差不多
sar查看网络状态 跟vmstat用法差不多 1 10 每隔一秒打印,打印10次结束
没有这个命令,使用 yum install -y sysstat
网卡流量 n:network DEV device sar -n DEV , sar -n DEV 1 10
读取指定文件数据,不加-f 默认显示今天凌晨到现在为止: sar -n DEV -f /var/log/sa/sa24
查看历史负载 sar -q ldavg 1分钟 5分钟 15分钟
查看磁盘读写 sar -b bread/s bwrtn/s

查看网络状态还有另外一个工具:iftop
记录文件需要开启sysstat服务:ls /etc/init.d/sysstat
查看cpu的个数和核数
cpu核数
cat /proc/cpuinfo
cat /proc/cpuinfo |grep 'core id'
processor :线程数 逻辑核心数 从0开始算 ,衡量性能
core id:核心数 物理核心数 从0开始算
cat /proc/cpuinfo |grep processor //只有一个逻辑核
processor : 0
cat /proc/cpuinfo |grep 'core id' //只有一个物理核
core id : 0
lscpu命令
lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 2 On-line CPU(s) list: 0,1 Thread(s) per core: 1 Core(s) per socket: 2 Socket(s): 1 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 45 Model name: Intel(R) Xeon(R) CPU E5-2680 0 @ 2.70GHz Stepping: 7 CPU MHz: 2698.942 BogoMIPS: 5400.00 Hypervisor vendor: VMware Virtualization type: full L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 20480K NUMA node0 CPU(s): 0,1 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts mmx fxsr sse sse2 ss ht syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts nopl xtopology tsc_reliable nonstop_tsc pni pclmulqdq ssse3 cx16 pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx hypervisor lahf_lm arat tsc_adjust
dstat 命令是 vmstat、iostat、netstat、nfsstat 和 ifstat 这些命令的合集,全能系统信息统计工具
https://cloud.tencent.com/developer/article/1921445
直接使用 dstat命令可以实时的监控 cpu、磁盘、网络、IO、内存等使用情况
安装
yum install -y dstat
指标,能以人性化的单位 显示 m,k,b等等
-c, --cpu :展示cpu状态。
usr用户占比,sys系统占比,idl空闲占比,wai等待次数,这四个加和是100, hiq硬中断次数,siq软中断次数。
dsk/total 磁盘读写
read:磁盘读取速度 writ:磁盘写速度。
net/total :网络状态
recv:接收速度 send:发送速度
paging 换页空间
展示内存到换页空间(swap)的使用情况,从内存到换页是out,从换页到内存是in,只有频繁的in和out才表明内存不足。
System
int: 每秒产生的中断次数
csw: 每秒产生的上下文切换次数
上面这 2 个值越大,会看到由内核消耗的 CPU 时间会越多
CPU资源的使用情况
dstat -cyl --proc-count --top-cpu
内存使用情况
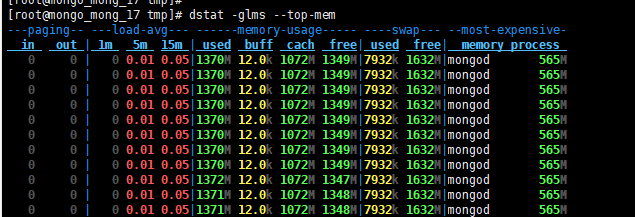
dstat -glms --top-mem
并发连接数不会超过65536 文件描述符 socket文件连接 最大65535
ulimit -n
# ulimit -a //腾讯云 core file size (blocks, -c) 0 data seg size (kbytes, -d) unlimited scheduling priority (-e) 0 file size (blocks, -f) unlimited pending signals (-i) 14860 max locked memory (kbytes, -l) 64 max memory size (kbytes, -m) unlimited open files (-n) 100001 //10W 关注 pipe size (512 bytes, -p) 8 POSIX message queues (bytes, -q) 819200 real-time priority (-r) 0 stack size (kbytes, -s) 10240 cpu time (seconds, -t) unlimited max user processes (-u) 14860 // 关注 virtual memory (kbytes, -v) unlimited file locks (-x) unlimited
STACK堆内存,mongodb连接默认采用这个配置,每个连接使用8192KB(8mb)/10240KB(10mb) 内存,连接一多,非常消耗内存
stack size (kbytes, -s) 8192 centos7
stack size (kbytes, -s) 10240 centos6
建议设置为1024,DefaultLimitSTACK==1024
ulimit -a //家里centos6 core file size (blocks, -c) 0 data seg size (kbytes, -d) unlimited scheduling priority (-e) 0 file size (blocks, -f) unlimited pending signals (-i) 7764 max locked memory (kbytes, -l) 64 max memory size (kbytes, -m) unlimited open files (-n) 1024 pipe size (512 bytes, -p) 8 POSIX message queues (bytes, -q) 819200 real-time priority (-r) 0 stack size (kbytes, -s) 10240 cpu time (seconds, -t) unlimited max user processes (-u) 7764 virtual memory (kbytes, -v) unlimited file locks (-x) unlimited
楼方鑫HZ(37223884) 17:24:34
起动onecache前要设一下ulimit -n
ulimit -n 16384
概述
系统性能一直是一个受关注的话题,如何通过最简单的设置来实现最有效的性能调优,如何在有限资源的
条件下保证程序的运作,ulimit 是我们在处理这些问题时,经常使用的一种简单手段。
ulimit 是一种 linux系统的内建功能,它具有一套参数集,用于为由它生成的 shell 进程及其子进程的资源使用设置限制。
本文将在后面的章节中详细说明 ulimit 的功能,使用以及它的影响,并以具体的例子来详细地阐述它在限制资
源使用方面的影响。
http://www.cnblogs.com/leaven/archive/2011/04/22/2024539.html
ulimit 的功能和用法
ulimit 功能简述
假设有这样一种情况,当一台 Linux 主机上同时登陆了 10 个人,在系统资源无限制的情况下,
这 10 个用户同时打开了 500 个文档,而假设每个文档的大小有 10M,这时系统的内存资源就
会受到巨大的挑战。
而实际应用的环境要比这种假设复杂的多,例如在一个嵌入式开发环境中,各方面的资源都是非常
紧缺的,对于开启文件描述符的数量,分配堆栈的大小,CPU 时间,虚拟内存大小,等等,都有非
常严格的要求。资源的合理限制和分配,不仅仅是保证系统可用性的必要条件,也与系统上软件运
行的性能有着密不可分的联系。这时,ulimit 可以起到很大的作用,它是一种简单并且有效的实现
资源限制的方式。
ulimit 用于限制 shell 所占用的资源,支持以下各种类型的限制:所创建的内核文件的大
小、进程数据块的大小、Shell 进程创建文件的大小、内存锁住的大小、常驻内存集的大小、打开
文件描述符的数量、分配堆栈的最大大小、CPU 时间、单个用户的最大线程数、Shell 进程所能使
用的最大虚拟内存。同时,它支持硬资源和软资源的限制。
作为临时限制,ulimit 可以作用于通过使用命令登录的 shell 会话,在会话终止时便结束限制,并
不影响于其他 shell 会话。而对于长期的固定限制,ulimit 命令语句又可以被添加到由登录 shell 读
取的文件中,作用于特定的 shell 用户。
ulimit 通过一些参数选项来管理不同种类的系统资源。在本节,我们将讲解这些参数的使用。
ulimit 命令的格式为:ulimit [options] [limit]
具体的 options 含义以及简单示例可以参考以下表格。
表 1. ulimit 参数说明
选项 [options]
含义
例子
-H
设置硬资源限制,一旦设置不能增加。
ulimit – Hs 64;限制硬资源,线程栈大小为 64K。
-S
设置软资源限制,设置后可以增加,但是不能超过硬资源设置。
ulimit – Sn 32;限制软资源,32 个文件描述符。
-a
显示当前所有的 limit 信息。
ulimit – a;显示当前所有的 limit 信息。
-c
最大的 core 文件的大小, 以 blocks 为单位。
ulimit – c unlimited; 对生成的 core 文件的大小不进行限制。
-d
进程最大的数据段的大小,以 Kbytes 为单位。
ulimit -d unlimited;对进程的数据段大小不进行限制。
-f
进程可以创建文件的最大值,以 blocks 为单位。
ulimit – f 2048;限制进程可以创建的最大文件大小为 2048 blocks。
-l
最大可加锁内存大小,以 Kbytes 为单位。
ulimit – l 32;限制最大可加锁内存大小为 32 Kbytes。
-m
最大内存大小,以 Kbytes 为单位。
ulimit – m unlimited;对最大内存不进行限制。
-n
可以打开最大文件描述符的数量。
ulimit – n 128;限制最大可以使用 128 个文件描述符。
-p
管道缓冲区的大小,以 Kbytes 为单位。
ulimit – p 512;限制管道缓冲区的大小为 512 Kbytes。
-s
线程栈大小,以 Kbytes 为单位。
ulimit – s 512;限制线程栈的大小为 512 Kbytes。默认值是8192KB,也就是8MB
linux里面一个线程一般占用多少内存
http://www.mongoing.com/archives/8781
针对每个连接,Mongod 会起一个单独的线程,专门负责处理这条连接上的请求,mongod 为处理连接请求的线程配置了最大1MB的线程栈,
通常实际使用在几十KB左右,通过 proc 文件系统看到这些线程栈的实际开销。
除了处理请求的线程,mongod 还有一系列的后台线程,比如主备同步、定期刷新 Journal、TTL、evict 等线程,
默认每个线程最大ulimit -s(一般10MB)的线程栈,由于这批线程数量比较固定,占的内存也比较可控。
-t
最大的 CPU 占用时间,以秒为单位。
ulimit – t unlimited;对最大的 CPU 占用时间不进行限制。
-u
用户最大可用的进程数。
ulimit – u 64;限制用户最多可以使用 64 个进程。
-v
进程最大可用的虚拟内存,以 Kbytes 为单位。
ulimit – v 200000;限制最大可用的虚拟内存为 200000 Kbytes。
https://blog.51cto.com/ppp1013/342385
我们可以通过以下几种方式来使用 ulimit:
在用户的启动脚本中
如果用户使用的是 bash,就可以在用户的家目录下的 .bashrc 文件中,加入 ulimit – u 64,
来限制用户最多可以使用 64 个进程。此外,可以在与 .bashrc 功能相当的启动脚本中加入 ulimt。
在应用程序的启动脚本中
如果用户要对某个应用程序 myapp 进行限制,可以写一个简单的脚本 startmyapp。
用户进程的有效范围
ulimit 作为对资源使用限制的一种方式,是有其作用范围的。那么,它限制的对象是单个用户,单个
进程,还是整个系统呢?事实上,ulimit 限制的是当前 shell 进程以及其派生的子进程。举例来说,
如果用户同时运行了两个 shell 终端进程,只在其中一个环境中执行了 ulimit – s 100,则该 shell
进程里创建文件的大小收到相应的限制,而同时另一个 shell 终端包括其上运行的子程序都不会受其影响:
Shell 进程 1
Shell 进程 2
ulimit 管理系统资源的例子
ulimit 提供了在 shell 进程中限制系统资源的功能。本章列举了一些使用 ulimit 对用户进
程进行限制的例子,详述了这些限制行为以及对应的影响,以此来说明 ulimit 如何对系统资源进行限制,从而达到调节系统性能的功能。
使用 ulimit 限制程序所能创建的 socket 数量
考虑一个现实中的实际需求。对于一个 C/S 模型中的 server 程序来说,它会为多个 client
程序请求创建多个 socket 端口给与响应。如果恰好有大量的 client 同时向 server 发出请
求,那么此时 server 就会需要创建大量的 socket 连接。但在一个系统当中,往往需要限制单
个 server 程序所能使用的最大 socket 数,以供其他的 server 程序所使用。那么我们如何
来做到这一点呢?答案是我们可以通过 ulimit 来实现!细心的读者可能会发现,通过前面章节的
介绍似乎没有限制 socket 使用的 ulimit 选项。是的,ulimit 并没有哪个选项直接说是用来
限制 socket 的数量的。但是,我们有 -n 这个选项,它是用于限制一个进程所能打开的文件描
述符的最大值。在 Linux 下一切资源皆文件,普通文件是文件,磁盘打印机是文件,socket 当
然也是文件。在 Linux 下创建一个新的 socket 连接,实际上就是创建一个新的文件描述符。如
下图所示(查看某个进程当前打开的文件描述符信息):

因此,我们可以通过使用 ulimit – n 来限制程序所能打开的最大文件描述符数量,从而
达到限制 socket 创建的数量。
每当一个新的线程被创建时都需要新分配一段大小为 1232KB (1MB)的内存空间
https://www.cnblogs.com/IMxY/p/8941022.html
https://www.cnblogs.com/MYSQLZOUQI/p/9809018.html
centos6
全局设置:有两种
第一种:加载了pam_limits.so模块的进程,/etc/security/limits.conf 仅针对使用pam的进程并且加载了pam_limits.so模块的进程(limits.conf 实际是pam_limits.so的配置文件)
第二种:没有加载pam_limits.so模块的进程,保险来说,不管运行的进程有没有加载pam_limits.so模块,最好在服务启动前设置ulimit命令
vim /etc/security/limits.conf
* - nofile 1024000
* - nproc 1024000
centos7
全局设置:有两种
第一种:不管用不用systemd管理进程都生效,/etc/security/limits.conf 仅针对使用pam的进程并且加载了pam_limits.so模块的进程(limits.conf 实际是pam_limits.so的配置文件)
第二种:用systemd管理进程,
全局服务:对所有systemd管理的服务生效,/etc/systemd/system.conf的[Manager]下的所有#DefaultLimitxxx
单个服务:只对单个systemd管理的服务生效,/usr/lib/systemd/system/xxx.service里的[Service]里增加LimitNOFILE=65535
username|@groupname type resource limit
username|@groupname:设置需要被限制的用户名,组名前面加@和用户名区别。也可以用通配符*来做所有用户的限制。
type:有 soft,hard 和 -,soft 指的是当前系统生效的设置值。hard 表明系统中所能设定的最大值。soft 的限制不能比har 限制高。用 - 就表明同时设置了 soft 和 hard 的值。
vim /etc/security/limits.conf * - nofile 1024000 * - nproc 1024000
resource:
core - 限制内核文件的大小
date - 最大数据大小
fsize - 最大文件大小
memlock - 最大锁定内存地址空间
nofile - 打开文件的最大数目
rss - 最大持久设置大小
stack - 最大栈大小
cpu - 以分钟为单位的最多 CPU 时间
noproc - 进程的最大数目
as - 地址空间限制
maxlogins - 此用户允许登录的最大数目
要使 limits.conf 文件配置生效,必须要确保 pam_limits.so 文件被加入到启动文件中。查看 /etc/pam.d/login 文件中有:
session required /lib/security/pam_limits.so
暂时地,适用于通过 ulimit 命令登录 shell 会话期间。
永久地,通过将一个相应的 ulimit 语句添加到由登录 shell 读取的文件之一(例如 ~/.profile),即特定于 shell 的用户资源文件;或者通过编辑 /etc/security/limits.conf。
何谓core文件,当一个程序崩溃时,在进程当前工作目录的core文件中复制了该进程的存储图像。core文件仅仅是一个内存映象(同时加上调试信息),主要是用来调试的。 core文件是个二进制文件,需要用相应的工具来分析程序崩溃时的内存映像。
系统默认core文件的大小为0,所以没有创建。可以用ulimit命令查看和修改core文件的大小。
$ulimit -c
0
$ ulimit -c 1000
$ ulimit -c
1000
-c 指定修改core文件的大小,1000指定了core文件大小。也可以对core文件的大小不做限制,如:
# ulimit -c unlimited
#ulimit -c
unlimited
如果想让修改永久生效,则需要修改配置文件,如 .bash_profile、/etc/profile或/etc/security/limits.conf。
2.nofile - 打开文件的最大数目
对于需要做许多套接字连接并使它们处于打开状态的应用程序而言,最好通过使用 ulimit –n,或者通过设置nofile 参数,为用户把文件描述符的数量设置得比默认值高一些
用ulimit -n 2048 修改只对当前的shell有效,退出后失效:
如A程序已经运行,此时ulimit -n为1024;之后ulimit -n 2048,这时在运行B程序;退出当前shell用户,再次进行shell,之后运行C程序;这时只有B程序用的是2048,其它用的都是1024
lsof命令
在终端下输入lsof即可显示系统打开的文件,因为 lsof 需要访问核心内存和各种文件,所以必须以 root 用户的身份运行它才能够充分地发挥其功能。
各列解释
每行显示一个打开的文件,若不指定条件默认将显示所有进程打开的所有文件。
lsof输出各列信息的意义如下:
COMMAND:进程的名称
PID:进程标识符
USER:进程所有者
FD:文件描述符,应用程序通过文件描述符识别该文件。如cwd、txt等
TYPE:文件类型,如DIR、REG等
DEVICE:指定磁盘的名称
SIZE:文件的大小
NODE:索引节点(文件在磁盘上的标识)
NAME:打开文件的确切名称
选项
lsof filename 显示打开指定文件的所有进程
lsof -a 表示两个参数都必须满足时才显示结果
lsof -c string 显示COMMAND列中包含指定字符的进程所有打开的文件
lsof -u username 显示所属user进程打开的文件
lsof -g gid 显示所属gid的进程情况
lsof +d /DIR/ 显示目录下被进程打开的文件
lsof +D /DIR/ 同上,但是会递归搜索,但是会搜索目录下的所有目录,时间相对较长
lsof -d FD 显示指定文件描述符的进程
lsof -n 不将IP转换为hostname,缺省是不加上-n参数
lsof -p <pid> 查看指定进程打开的文件
lsof -i[46] [protocol][@hostname|@hostaddr][:service|port]
46 --> IPv4 or IPv6
protocol --> TCP or UDP
hostname --> Internet host name
hostaddr --> IPv4地址
service --> /etc/services 中的 service name (可以不只一个)
port --> 端口号 (可以不只一个)
lsof -n |grep deleted ,显示文件系统中已经被删除的文件但是因为被引用所以还无法删除
文件被 deleted,但syslog-ng中文件句柄还在,结果导致磁盘空间一直未释放。有经验的SA发现磁盘空间实际使用和df显示的不一致时,
一般都会用lsof检查是否有大文件标记为deleted,把该进程杀掉或重启下系统就可以了。https://imysql.com/2014/04/25/disk-space-unfree-if-large-file-was-deleted.shtml
lsof -i:36000,显示使用36000端口的进程
lsof -u root,显示以root运行的程序
lsof -c php-fpm,显示php-fpm进程打开的文件
lsof php.ini,显示打开php.ini这个文件的进程。
lsof -i :873|grep -v "PID"|awk '{print "kil -9",$2}'|sh grep -v "PID":去除行头
# lsof -i 4 查看IPv4类型的进程
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
exim4 2213 Debian-exim 4u IPv4 4844 TCP *:smtp (LISTEN)
dhclient3 2306 root 4u IPv4 4555 UDP *:bootpc
# lsof -i 6 查看IPv6类型的进程
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
exim4 2213 Debian-exim 3u IPv6 4820 TCP *:smtp (LISTEN)
# lsof -i @192.168.1.2 查看与某个具体的IP相关联的进程
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
amule 3620 root 16u IPv4 11925 TCP 192.168.1.2:42556->77.247.178.244:4242 (ESTABLISHED)
amule 3620 root 28u IPv4 11952 TCP 192.168.1.2:49915->118-166-47-24.dynamic.hinet.net:5140 (ESTABLISHED)
# lsof -i:873 根据进程号查看进程对应的可执行程序
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
rsync 702 root 4u IPv4 3792149 0t0 TCP *:rsync (LISTEN)
lsof -p 702 根据进程号查看进程对应的可执行程序
# lsof -p 702
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
rsync 702 root cwd DIR 252,1 4096 311297 /root
rsync 702 root rtd DIR 252,1 4096 2 /
rsync 702 root txt REG 252,1 410536 240090 /usr/bin/rsync
rsync 702 root mem REG 252,1 18712 147514 /lib64/libattr.so.1.1.0
rsync 702 root mem REG 252,1 154528 147463 /lib64/ld-2.12.so
rsync 702 root 0u CHR 1,3 0t0 3787 /dev/null 前三个文件描述符 标准输入 标准输出 标准错误 第四个开始文件描述符
rsync 702 root 1u CHR 1,3 0t0 3787 /dev/null
rsync 702 root 2u CHR 1,3 0t0 3787 /dev/null
rsync 702 root 4u IPv4 3792149 0t0 TCP *:rsync (LISTEN)
# lsof /usr/bin/rsync
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
rsync 702 root txt REG 252,1 410536 240090 /usr/bin/rsync
# lsof -u steven
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
sshd 19640 steven cwd DIR 252,1 4096 2 /
sshd 19640 steven rtd DIR 252,1 4096 2 /
sshd 19640 steven txt REG 252,1 567128 239837 /usr/sbin/sshd
sshd 19640 steven DEL REG 0,4 6892665 /dev/zero
sshd 19640 steven mem REG 252,1 18600 147602 /lib64/security/pam_limits.so
# lsof -c rsync
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
rsync 702 root cwd DIR 252,1 4096 311297 /root
rsync 702 root rtd DIR 252,1 4096 2 /
rsync 702 root txt REG 252,1 410536 240090 /usr/bin/rsync
rsync 702 root mem REG 252,1 18712 147514 /lib64/libattr.so.1.1.0
rsync 702 root mem REG 252,1 1921176 147470 /lib64/libc-2.12.so
rsync 702 root 0u CHR 1,3 0t0 3787 /dev/null
rsync 702 root 4u IPv4 3792149 0t0 TCP *:rsync (LISTEN)
lsof简介
http://blog.csdn.net/guoguo1980/article/details/2324454
lsof(list open files)是一个列出当前系统打开文件的工具。在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。所以如传输控制协议 (TCP) 和用户数据报协议 (UDP) 套接字等,系统在后台都为该应用程序分配了一个文件描述符,无论这个文件的本质如何,该文件描述符为应用程序与基础操作系统之间的交互提供了通用接口。为应用程序打开文件的描述符列表提供了大量关于这个应用程序本身的信息,因此通过lsof工具能够查看这个列表对系统监测以及排错将是很有帮助的。
大多数与 lsof 相关的信息都存储于以进程的 PID 命名的目录中,即 /proc/1234 中包含的是 PID 为 1234 的进程的信息。
lsof使用
lsof输出信息含义
在终端下输入lsof即可显示系统打开的文件,因为 lsof 需要访问核心内存和各种文件,所以必须以 root 用户的身份运行它才能够充分地发挥其功能。
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
init 1 root cwd DIR 3,3 1024 2 /
init 1 root rtd DIR 3,3 1024 2 /
init 1 root txt REG 3,3 38432 1763452 /sbin/init
init 1 root mem REG 3,3 106114 1091620 /lib/libdl-2.6.so
init 1 root mem REG 3,3 7560696 1091614 /lib/libc-2.6.so
init 1 root mem REG 3,3 79460 1091669 /lib/libselinux.so.1
init 1 root mem REG 3,3 223280 1091668 /lib/libsepol.so.1
init 1 root mem REG 3,3 564136 1091607 /lib/ld-2.6.so
init 1 root 10u FIFO 0,15 1309 /dev/initctl
每行显示一个打开的文件,若不指定条件默认将显示所有进程打开的所有文件。lsof输出各列信息的意义如下:
COMMAND:进程的名称
PID:进程标识符
USER:进程所有者
FD:文件描述符,应用程序通过文件描述符识别该文件。如cwd、txt等
TYPE:文件类型,如DIR、REG等
DEVICE:指定磁盘的名称
SIZE:文件的大小
NODE:索引节点(文件在磁盘上的标识) 文件inode
NAME:打开文件的确切路径
FD 列表示文件描述符
cwd 表示应用程序的当前工作目录,这是该应用程序启动的目录,除非它本身对这个目录进行更改。
txt 表示的文件是程序代码,如应用程序二进制文件本身或共享库,如上列表中显示的 /sbin/init 程序。
u 表示该其次数值表示应用程序的文件描述符,这是打开该文件时返回的一个整数。如上的最后一行文件/dev/initctl,
其文件描述符为 10。
文件被打开并处于读取/写入模式,而不是只读或只写模式。同时还有大写的W表示该应用程序具有对整个文件的写锁。
该文件描述符用于确保每次只能打开一个应用程序实例。初始打开每个应用程序时,都具有三个文件描述符,
从 0 到 2,分别表示标准输入、输出和错误流。所以大多数应用程序所打开的文件的 FD 都是从 3 开始。
Type 列表示文件类型
文件和目录分别称为 REG 和 DIR
CHR 和 BLK,分别表示字符和块设备
UNIX、FIFO 和 IPv4,分别表示 UNIX 域套接字、先进先出 (FIFO) 队列和网络协议 (IP) 套接字
lsof常用参数
lsof 常见的用法是查找应用程序打开的文件的名称和数目。可用于查找出某个特定应用程序将日志数据记录到何处,或者正在跟踪某个问题。
例如,linux限制了进程能够打开文件的数目。通常这个数值很大,所以不会产生问题,并且在需要时,应用程序可以请求更大的值(直到某
个上限)。如果你怀疑应用程序耗尽了文件描述符,那么可以使用 lsof 统计打开的文件数目,以进行验证。lsof语法格式是:
lsof [options] filename
常用的参数列表:
lsof filename 显示打开指定文件的所有进程
lsof -a 表示两个参数都必须满足时才显示结果
lsof -c string 显示COMMAND列中包含指定字符的进程所有打开的文件
lsof -u username 显示所属user进程打开的文件
lsof -g gid 显示所属gid的进程情况
lsof +d /DIR/ 显示目录下被进程打开的文件
lsof +D /DIR/ 同上,但是会递归搜索,但是会搜索目录下的所有目录,时间相对较长
lsof -d FD 显示指定文件描述符的进程
lsof -n 不将IP转换为hostname,缺省是不加上-n参数
lsof -p <pid> 查看指定进程打开的文件
lsof -i[46] [protocol][@hostname|@hostaddr][:service|port]
46 --> IPv4 or IPv6
protocol --> TCP or UDP
hostname --> Internet host name
hostaddr --> IPv4地址
service --> /etc/services 中的 service name (可以不只一个)
port --> 端口号 (可以不只一个)
lsof使用实例
一、查找谁在使用文件系统
在卸载文件系统时,如果该文件系统中有任何打开的文件,操作通常将会失败。那么通过lsof可以找出那些进程在使用当前要卸载的文件系统,如下:
# lsof /GTES11/
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
bash 4208 root cwd DIR 3,1 4096 2 /GTES11/
vim 4230 root cwd DIR 3,1 4096 2 /GTES11/
二、恢复删除的文件
当Linux计算机受到入侵时,常见的情况是日志文件被删除,以掩盖攻击者的踪迹。管理错误也可能导致意外删除重要的文件,比如在清理旧日志时,意外地删除了数据库的活动事务日志。
有时可以通过lsof来恢复这些文件。
当进程打开了某个文件时,只要该进程保持打开该文件,即使将其删除,它依然存在于磁盘中。这意味着,进程并不知道文件已经被删除,它仍然可以像打开该文件时提供给它的文件描述符进行读取和写入。
除了该进程之外,这个文件是不可见的,因为已经删除了其相应的目录索引节点inode。
在/proc 目录下,其中包含了反映内核和进程树的各种文件。/proc目录挂载的是在内存中所映射的一块区域,所以这些文件和目录并不存在于磁盘中,因此当我们对这些文件进行读取和写入时,实际上是在从内存中获取相关信息。大多数与 lsof 相关的信息都存储于以进程的 PID 命名的目录中,即 /proc/1234 中包含的是 PID 为 1234 的进程的信息。每个进程目录中存在着各种文件,它们可以使得应用程序简单地了解进程的内存空间、文件描述符列表、指向磁盘上的文件的符号链接和其他系统信息。lsof 程序使用该信息和其他关于内核内部状态的信息来产生其输出。所以lsof 可以显示进程的文件描述符和相关的文件名等信息。也就是我们通过访问进程的文件描述符可以找到该文件的相关信息。
ll /proc/8775/exe
lrwxrwxrwx 1 root root 0 Mar 29 19:02 /proc/8775/exe -> /usr/sbin/sshd
当系统中的某个文件被意外地删除了,只要这个时候系统中还有进程正在访问该文件,那么我们就可以通过lsof从/proc目录下恢复该文件的内容。 假如由于误操作将/var/log/messages文件删除掉了,那么这时要将/var/log/messages文件恢复的方法如下:
首先使用lsof来查看当前是否有进程打开/var/logmessages文件,如下:
# lsof |grep /var/log/messages
syslogd 1283 root 2w REG 3,3 5381017 1773647 /var/log/messages (deleted)
从上面的信息可以看到 PID 1283(syslogd)打开文件的文件描述符为 2。同时还可以看到/var/log/messages已经标记被删除了。因此我们可以在 /proc/1283/fd/2 (fd下的每个以数字命名的文件表示进程对应的文件描述符)中查看相应的信息,如下:
# head -n 10 /proc/1283/fd/2
Aug 4 13:50:15 holmes86 syslogd 1.4.1: restart.
Aug 4 13:50:15 holmes86 kernel: klogd 1.4.1, log source = /proc/kmsg started.
Aug 4 13:50:15 holmes86 kernel: Linux version 2.6.22.1-8 (root@everestbuilder.linux-ren.org) (gcc version 4.2.0) #1 SMP Wed Jul 18 11:18:32 EDT 2007
Aug 4 13:50:15 holmes86 kernel: BIOS-provided physical RAM map:
Aug 4 13:50:15 holmes86 kernel: BIOS-e820: 0000000000000000 - 000000000009f000 (usable)
Aug 4 13:50:15 holmes86 kernel: BIOS-e820: 000000000009f000 - 00000000000a0000 (reserved)
Aug 4 13:50:15 holmes86 kernel: BIOS-e820: 0000000000100000 - 000000001f7d3800 (usable)
Aug 4 13:50:15 holmes86 kernel: BIOS-e820: 000000001f7d3800 - 0000000020000000 (reserved)
Aug 4 13:50:15 holmes86 kernel: BIOS-e820: 00000000e0000000 - 00000000f0007000 (reserved)
Aug 4 13:50:15 holmes86 kernel: BIOS-e820: 00000000f0008000 - 00000000f000c000 (reserved)
如果可以通过文件描述符查看相应的数据,那么就可以使用 I/O 重定向将其复制到文件中,如:
cat /proc/1283/fd/2 > /var/log/messages
对于许多应用程序,尤其是日志文件和数据库,这种恢复删除文件的方法非常有用
查找误删文件具体步骤
比如查找/var/log/messages
1、使用lsof查看/var/log下面的文件所用的文件描述符
lsof +D /var/log
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
auditd 1138 root 5w REG 253,0 724625 1312257 /var/log/audit/audit.log
rsyslogd 1168 root 1w REG 253,0 1111 1312269 /var/log/messages
rsyslogd 1168 root 2w REG 253,0 55962 1312253 /var/log/cron
rsyslogd 1168 root 4w REG 253,0 1763 1312270 /var/log/secure
mcelog 1493 root 3w REG 253,0 0 1312155 /var/log/mcelog
zabbix_ag 2054 zabbix 1w REG 253,0 263546 1312233 /var/log/zabbix/zabbix_agentd.log
zabbix_ag 2054 zabbix 2w REG 253,0 263546 1312233 /var/log/zabbix/zabbix_agentd.log
zabbix_ag 2058 zabbix 1w REG 253,0 263546 1312233 /var/log/zabbix/zabbix_agentd.log
zabbix_ag 2058 zabbix 2w REG 253,0 263546 1312233 /var/log/zabbix/zabbix_agentd.log
2、找到使用/var/log/messages的进程的pid ,和/var/log/messages所使用的文件描述符次数 这里次数为1
ll /proc/1168/fd
total 0
lrwx------ 1 root root 64 Mar 25 11:00 0 -> socket:[10156]
l-wx------ 1 root root 64 Mar 25 11:00 1 -> /var/log/messages
l-wx------ 1 root root 64 Mar 30 10:24 2 -> /var/log/cron
lr-x------ 1 root root 64 Mar 25 11:00 3 -> /proc/kmsg
l-wx------ 1 root root 64 Mar 30 10:24 4 -> /var/log/secure
3、cat一下文件描述符为1的文件
cat /proc/1168/fd/1
Mar 28 10:37:01 steven rsyslogd: [origin software="rsyslogd" swVersion="5.8.10" x-pid="1168" x-info="http://www.rsyslog.com"] rsyslogd was HUPed
Mar 28 11:49:21 steven fail2ban.filter[2075]: INFO Log rotation detected for /var/log/secure
Mar 28 12:40:12 steven kernel: e1000: eth0 NIC Link is Down
Mar 28 12:40:22 steven kernel: e1000: eth0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None
Mar 28 13:36:27 steven kernel: e1000: eth0 NIC Link is Down
Mar 28 13:36:38 steven kernel: e1000: eth0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None
Mar 28 18:24:48 steven yum[4880]: Installed: sysstat-9.0.4-27.el6.x86_64
Mar 28 19:13:41 steven kernel: e1000: eth0 NIC Link is Down
Mar 28 19:13:53 steven kernel: e1000: eth0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None
Mar 29 12:34:14 steven kernel: e1000: eth0 NIC Link is Down
Mar 29 12:34:23 steven kernel: e1000: eth0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None
Mar 29 19:01:57 steven kernel: e1000: eth0 NIC Link is Down
Mar 29 19:02:09 steven kernel: e1000: eth0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None
4、进行比较,发现确实是一样的
at /var/log/messages
Mar 28 10:37:01 steven rsyslogd: [origin software="rsyslogd" swVersion="5.8.10" x-pid="1168" x-info="http://www.rsyslog.com"] rsyslogd was HUPed
Mar 28 11:49:21 steven fail2ban.filter[2075]: INFO Log rotation detected for /var/log/secure
Mar 28 12:40:12 steven kernel: e1000: eth0 NIC Link is Down
Mar 28 12:40:22 steven kernel: e1000: eth0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None
Mar 28 13:36:27 steven kernel: e1000: eth0 NIC Link is Down
Mar 28 13:36:38 steven kernel: e1000: eth0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None
Mar 28 18:24:48 steven yum[4880]: Installed: sysstat-9.0.4-27.el6.x86_64
Mar 28 19:13:41 steven kernel: e1000: eth0 NIC Link is Down
Mar 28 19:13:53 steven kernel: e1000: eth0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None
Mar 29 12:34:14 steven kernel: e1000: eth0 NIC Link is Down
Mar 29 12:34:23 steven kernel: e1000: eth0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None
Mar 29 19:01:57 steven kernel: e1000: eth0 NIC Link is Down
Mar 29 19:02:09 steven kernel: e1000: eth0 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None
5、备份下来
cat /proc/1168/fd/1> /var/log/messages
pidof命令
pidof 进程名
21852是libvirtd 进程的进程号
[root@gz]# netstat -lntp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:5905 0.0.0.0:* LISTEN 21945/qemu-kvm
tcp 0 0 0.0.0.0:16509 0.0.0.0:* LISTEN 21852/libvirtd
tcp 0 0 0.0.0.0:9022 0.0.0.0:* LISTEN 1150/sshd
tcp 0 0 127.0.0.1:8000 0.0.0.0:* LISTEN 1173/python
tcp 0 0 0.0.0.0:6080 0.0.0.0:* LISTEN 1171/python
tcp 0 0 0.0.0.0:5903 0.0.0.0:* LISTEN 21977/qemu-kvm
tcp 0 0 :::9022 :::* LISTEN 1150/sshd
[root@gzy1]# pidof libvirtd
21852
htop
Python工具,能展示的粒度到线程级别,能看到进程目录树,以彩色展示结果
安装
yum install -y htop
https://blog.51cto.com/liuzhengwei521/2360430
perf 可以对指定的进程或者事件进行采样,并且还可以用调用栈的形式,输出整个调用链上的汇总信息。
使用 perf 来查找应用程序或者内核中的热点函数,从而找出是什么函数占用CPU比较高,从而定位性能瓶颈。
使用 perf 对系统内核线程进行分析时,内核线程依然还在正常运行中,所以这种方法也被称为动态追踪技术。
安装
yum install perf -y
perf常用参数:
top:动态时实追踪显示占用CPU较高的进程
record:由于top只能实时查看不能保存,不便于事后分析,用此参数保存追踪的内容,文件名为perf.data
report:重放perf.data的内容
perf record常用参数:
-p:指定追踪进程的PID
-g:启用进程中函数的调用关系(CPU使用超过0.5%时,才会显示调用栈,可以通过man查看)
-a:追踪所有的CPU的
sleep N:采集多长时间的数据(如:perf record -ag sleep 10;perf report,直接采集10数据并分析)
第一种,perf top
Samples: 16K of event 'cpu-clock', 4000 Hz, Event count (approx.): 416537460 lost: 0/0 drop: 0/0 Overhead Shared Object Symbol 7.57% [kernel] [k] _raw_spin_unlock_irqrestore 3.76% [kernel] [k] __do_softirq 3.67% [kernel] [k] finish_task_switch 3.33% libpython3.6m.so.1.0 [.] _PyEval_EvalFrameDefault 2.92% libc-2.17.so [.] __ctype_get_mb_cur_max 2.20% mongod [.] __config_next 1.87% [kernel] [k] _raw_spin_lock 1.76% [kernel] [k] tick_nohz_idle_enter 1.54% perf [.] perf_mmap__consume 1.51% [kernel] [k] clear_page 1.32% [kernel] [k] copy_pte_range
第二种常见用法,也就是 perf record 和 perf report。
perf top 虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析。
而 perf record 则提供了保存数据的功能,保存后的数据,需要你用 perf report 解析展示。
record会自动保存到当前目录下的perf.data文件中
$ perf record -g # 按Ctrl+C终止采样
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.452 MB perf.data (6093 samples) ]
$ perf report # 展示类似于perf top的报告
在实际使用中,我们还经常为 perf top 和 perf record 加上 -g 参数,开启调用关系的采样,方便我们根据调用链来分析性能问题。
用法示例:
perf top -g -p <pid> :实时显示<pid>进程的
perf record -g -p <pid> :会自动生成<pid>进程的 perf.data文件
perf report ./perf.data :会自动分析当前目录下的perf.data文件
#追踪mongodb perf top -g -p 3282 Samples: 687 of event 'cpu-clock', 4000 Hz, Event count (approx.): 67623374 lost: 0/0 drop: 0/0 Children Self Shared Object Symbol + 16.64% 0.00% mongod [.] execute_native_thread_routine + 15.06% 2.37% mongod [.] mongo::FTDCCompressor::getCompressedSamples + 14.05% 0.00% mongod [.] mongo::FTDCController::doLoop + 13.91% 13.86% mongod [.] __config_next + 13.80% 1.49% mongod [.] __config_getraw.constprop.0 + 11.62% 3.02% mongod [.] deflate_slow + 11.42% 0.82% mongod [.] mongo::FTDCCompressor::addSample + 9.24% 0.00% mongod [.] mongo::FTDCFileManager::writeSampleAndRotateIfNeeded + 9.24% 0.00% mongod [.] mongo::FTDCFileWriter::writeSample + 8.99% 0.19% mongod [.] mongo::CmdServerStatus::run + 6.66% 6.66% mongod [.] longest_match + 6.28% 0.00% mongod [.] mongo::BlockCompressor::compress + 6.28% 0.00% mongod [.] deflate
https://www.jianshu.com/p/e9b1505ed104
execsnoop
execsnoop-专门用于为追踪短时进程(瞬时进程)设计的工具,它通过 ftrace 实时监控进程的 exec() 行为,并输出短时进程的基本信息,包括进程 PID、父进程 PID、命令行参数以及执行的结果。
exec功能:将一个新程序装入调用进程的内存空间,来改变调用进程的执行代码,从而形成新进程。 如果exec调用成功,当前进程将被覆盖,然后开始执行新程序,并且不会返回原进程,这样就产生了一个新进程,但是它的进程标识符与调用进程相同。这说明什么?说明exec并没有像fork()一样创建一个与调用进程并发执行的新进程,而是用新进程取代了原来的进程。所以,exec调用成功后,没有任何返回数据
在bcc软件包里
yum install -y bcc-tools
tcpdump:网络包跟踪(用libpcap库)。
snoop:为基于Solaris的系统打造的网络包跟踪工具。
blktrace:块I/O跟踪(Linux)。
iosoop:块I/O跟踪(基于DTrace)。
execsnoop:跟踪新进程(基于DTrace)。
dtruss:系统级别的系统调用缓冲跟踪(基于DTrace)。
DTrace:跟踪内核的内部活动和所有资源的使用情况(不仅仅是网络和块I/O),支持静态和动态的跟踪。
SystemTap: 跟踪内核的内部活动和所有资源的使用情况,支持静态和动态的跟踪。
eBPF:跟踪内核的内部活动和所有资源的使用情况,支持静态和动态的跟踪。
perf:Linux性能事件,跟踪静态和动态的探针。
https://blog.csdn.net/qq_33894122/article/details/108186999
在排查一些系统问题时,往往 top 看到的CPU使用率已经到 100%了,但是看 各个进程的 cpu使用率相加 只有
30% 这种远低于 100%,这是因为 系统快速创建的进程往往没有被显示出来,top更新频率是 1次/s
那么有什么工具可以看到 系统中短时间内有大量进程被创建呢。
可以通过bcc的 execsnoop 工具来查看
一般可以看到有 大量进程被创建,这种进程一般是 通过shell 脚本 或者 C 语言system 命令直接调用的
一般可以
减少这种方式使用
或者使用 C库里面的C库函数来实现而不是偷懒使用 system直接调用 shell命令这种
隐藏进程
方法一
利用mount命令挂载到/proc进行进程隐藏
由于ps、top命令都是通过扫描/proc目录的,所以可以利用mout将目录挂载到/proc对应进程中,这样就达到的隐藏进程的功能。例如:
mount /dev/sda1 /proc/2222
这样就对2222进程号隐藏了,使用ps、top的时候就查看不到该进程了。
对抗方式:使用df -h 命令查看当前挂载的目录是否挂载到/proc的pid进程中。
方法二
通过Linux用户进行分离进程,很少用,对root用户无效
这种方式操作比较简单,一般用来防止用户之间可以相互看到启动的内容。将hidepid设置会2可以达到上述效果。(由于我使用的是root用户所以不存在这种情况了)
对抗方式: 可以查看fastab
vim /etc/fstab
proc /proc proc defaults,hidepid=2 0 0
方法三
Hook系统调用
这就要从ps、top的命令执行原理来说了,这些命令执行一般分为以下几步:
调用openat函数获取/proc目录的文件句柄。
调用getdents函数递归获取/proc目录下所有(包含子文件)文件。
调用open函数打开/proc/pid/stat,status,cmdline文件,获取进程数据,打印出来。
攻击者一般通过以下几种操作来达到隐藏进程的操作
修改命令需要调用的函数源码,比如open()、getdents()
修改libc库中的readdir函数源码
利用环境变量LD_PRELOAD或者配置ld.so.preload使得恶意文件先于系统标准库加载,使得系统使用命令时绕过系统标准库,达到进程隐藏的目的。
prlimit 命令
prlimit==process limit
假设有个场景,数据库或者其它中间件的运行时文件句柄等参数设置过低,导致服务不可用或者间歇性不可用。
但是重启服务的代价可能很大,那么我们也可以不重启进程,做到修改某个进程的 limits范围。
centos7提供了 prlimit 命令来实现
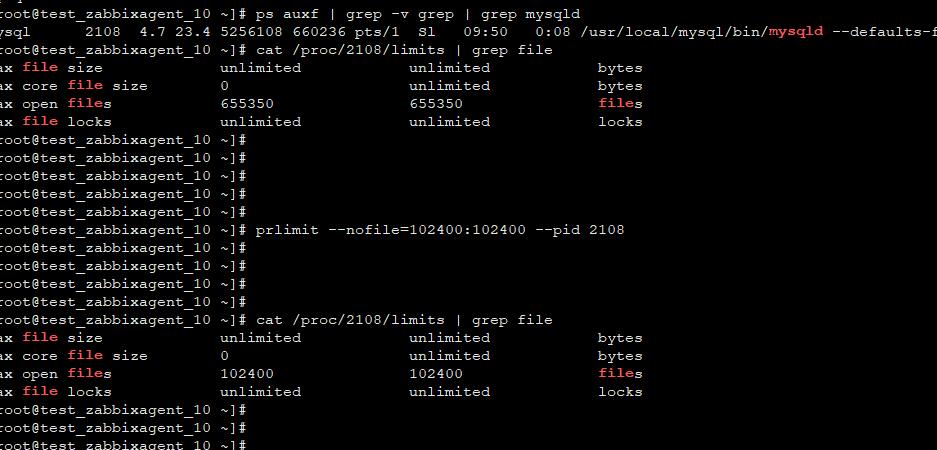
以MySQL服务为例
$ ps auxf | grep -v grep | grep mysqld mysql 1204 1.3 3.4 7311604 1134388 ? Sl Aug31 68:40 ./bin/mysqld --defaults-file=/usr/local/mysql/my.cnf --user=mysql --log-error-verbosity=3 $ cat /proc/1204/limits | grep file # 看到文件句柄限制为10240了 Max file size unlimited unlimited bytes Max core file size 0 unlimited bytes Max open files 10240 10240 files Max file locks unlimited unlimited locks # 用prlimit $ prlimit --nofile=102400:102400 --pid 1204 # 再次查看,可以看到已经变成 102400了 $ cat /proc/1204/limits | grep file Max file size unlimited unlimited bytes Max core file size 0 unlimited bytes Max open files 102400 102400 files Max file locks unlimited unlimited locks
prlimit 还支持其它的参数修改,具体如下
$ prlimit --help Usage: prlimit [options] [-p PID] prlimit [options] COMMAND General Options: -p, --pid <pid> process id -o, --output <list> define which output columns to use --noheadings don't print headings --raw use the raw output format --verbose verbose output -h, --help display this help and exit -V, --version output version information and exit Resources Options: -c, --core maximum size of core files created -d, --data maximum size of a process's data segment -e, --nice maximum nice priority allowed to raise -f, --fsize maximum size of files written by the process -i, --sigpending maximum number of pending signals -l, --memlock maximum size a process may lock into memory -m, --rss maximum resident set size -n, --nofile maximum number of open files # 最常用 -q, --msgqueue maximum bytes in POSIX message queues -r, --rtprio maximum real-time scheduling priority -s, --stack maximum stack size -t, --cpu maximum amount of CPU time in seconds -u, --nproc maximum number of user processes # 常用 -v, --as size of virtual memory -x, --locks maximum number of file locks -y, --rttime CPU time in microseconds a process scheduled under real-time scheduling Available columns (for --output): DESCRIPTION resource description RESOURCE resource name SOFT soft limit HARD hard limit (ceiling) UNITS units
f


