
20172328 2018-2019《Java软件结构与数据结构》第五周学习总结
20172328 2018-2019《Java软件结构与数据结构》第五周学习总结
概述 Generalization
本周学习了第九章:排序与查找,主要包括线性查找和二分查找算法和几种排序算法。我们在软件开发过程中要在某一组查找某个特定的元素或要将某一组元素按特定顺序排序,所以要学习排序与查找的多种算法。
教材学习内容总结 A summary of textbook
- 9.1查找
- 查找:是一个过程,即在某个项目组中寻找某一项指定目标元素,或者确定该指定目标并不存在。
- 高效的查找会使该过程所做的比较操作次数最小化。
- 静态方法:也称为类方法,可以通过类名来调用,无需实例化该类的对象。 在方法声明中,通过使用static修饰符就可以把他声明为静态的。
- 泛型方法:要创建一个泛型方法,只需要在方法头的返回类型前插入一个泛型声明即可:
public static <T extends Comparable<T>> Booolean linearSearch(T[] data,int min,int max,T target);
- 这样,就可以直接通过类名和要用来替换泛型的具体数据类型来调用静态方法啦。
Searching.linearSearch(targetarray,min,max,target) - 线性查找法
- 线性查找法就是从头开始查找,与每一个列表中的元素进行比较,直到找到该目标元素或查找到末尾还没找到。
- 以下的方法实现了一个线性查找。该方法返回一个布尔值,若是true,便是找到该元素,否则为false,表示没找到。
public static <T>
boolean linearSearch(T[] data, int min, int max, T target)
{
int index = min;
boolean found = false;
while (!found && index <= max)
{
found = data[index].equals(target);
index++;
}
return found;
}
- 二分查找法
- 二分查找是从排序列表(查找池是已排序的)的中间开始查找,而不是从一端或者另一端的开始的。通过比较,确定可行候选项就又减少了一半的元素量,以相同的方式继续查找,直到最后找到目标元素或者不再存在可行候选项。
- 二分查找的关键在于每次比较都会删除一半的可行候选项。
- 以下的方法实现了一个二分查找,其中的最大索引和最小索引定义了用于查找(可行候选项)的数组部分。
public static <T extends Comparable<T>>
boolean binarySearch(T[] data, int min, int max, T target)
{
boolean found = false;
int midpoint = (min + max) / 2; // determine the midpoint
if (data[midpoint].compareTo(target) == 0)
found = true;
else if (data[midpoint].compareTo(target) > 0)
{
if (min <= midpoint - 1)
found = binarySearch(data, min, midpoint - 1, target);
}
else if (midpoint + 1 <= max)
found = binarySearch(data, midpoint + 1, max, target);
return found;
}
}
-
注意:在该算法中,
midpoint = (min + max) / 2,当min+max所得数值是基数的时候,会自动转化成int类型,直接忽略小数部分,也就是确定中点索引时选择的是两个中间值的第一个(小一点的)。 -
查找算法的比较
-
对于线性查找和二分查找,最好的情形都是目标元素恰好是我们考察的第一个元素,最坏的情形也都是目标不在该组中。因此,线性查找的时间复杂度为O(n),二分查找的时间复杂度为O(log2(n))。
-
当n比较大时,即元素特别多的时候,二分查找就会大大提高效率。而当n比较小的时候,线性查找更简单好调试且不需要排序,因此也在小型问题上常用线性查找。
-
9.2排序
-
排序:基于某一标准,将某一组项目按照某个规定顺序排列。
- 顺序排序:通常使用一对嵌套循环对n个元素进行排序,需要大约n^2次比较。
- 对数排序:对n个元素进行排序通常大约需要nlog2(n)次比较。
-
常见的三种顺序排序:
- ①选择排序、②插入排序、③冒泡排序;
-
常见的两种对数排序:
- ①快速排序、②归并排序
-
选择排序:通过反复地找到某个最小(或者最大)元素,并把它放置到最后的位置来给元素排序。
-
插入排序:通过反复地把某个元素插入到之前已经排序的子列表中,实现元素的排序。
-
冒泡排序:通过反复的比较相邻元素并交换他们,来给元素排序。
-
快速排序:通过把未排序元素分隔成两个分区,然后递归地给每个分区排序。
-
快速排序的平均时间复杂度为O(nlogn)。在所有平均时间复杂度为O(nlogn)的算法中,快速排序的平均性能是最好的。

-
在课本代码中,需要重点理解Partition方法
while (left < right)
{
// search for an element that is > the partition element
while (left < right && data[left].compareTo(partitionelement) <= 0)
left++;
// search for an element that is < the partition element
while (data[right].compareTo(partitionelement) > 0)
right--;
// swap the elements
if (left < right)
swap(data, left, right);
}
// move the partition element into place
swap(data, min, right);
两个内层while循环用于寻找位于错误分区的交换元素,第一个循环从左边扫到右边,寻找大于分区元素的元素,第二个循环从右边扫到左边,寻找小于分区元素的元素,在找到这两个元素后,将他们互换,该过程会一直持续下去直到左索引和右索引在该列表的“中间”相遇。
-
归并排序:通过递归地把列表分半,直到每个子列表中只剩下一个元素为止,然后归并这些子列表。
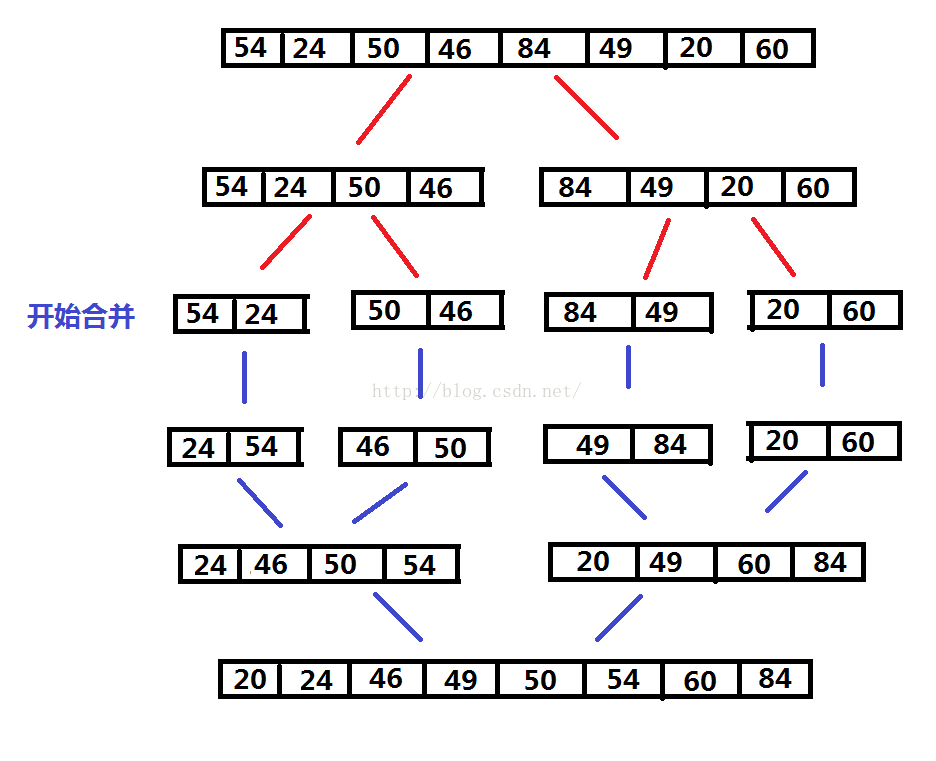
-
归并排序算法稳定,数组需要O(n)的额外空间,链表需要O(log(n))的额外空间,时间复杂度为O(nlog(n)),不需要对数据的随机读取。
-
在课本代码中,需重点理解merge方法。
-
基数排序:使用排序密钥而不是直接地进行比较元素,来实现元素排序。
-
比较数字大小,我们是先比位数,如果一个位数比另一个位数多,那这个数肯定更大。如果位数同样多,就按位数递减依次往下进行比较,哪个数在这一位上更大那就停止比较,得出这个在这个位上数更大的数字整体更大的结论。同样来讲我们也可以从最小的位开始比较。这就和基数排序原理相通了。
-
这是一篇介绍的很详细的博客,大家可以参考理解桶子法排序原理和实现
教材学习中的问题和解决过程 Problem and countermeasure
- 问题1:不明白基数排序RadixSort代码的循环中为什么循环次数是10次?
for (int digitVal = 0; digitVal <= 9; digitVal++)
digitQueues[digitVal] = (Queue<Integer>)(new LinkedList<Integer>());
- 问题1的解决:关键就在于
Queue<Integer>[] digitQueues = (LinkedList<Integer>[])(new LinkedList[10]);中,最初创建的数组中含有十个队列,那为什么创造10个队列呢?通过Debug跟着程序走一遍,我才明白原来这10个队列是分别保存不同的关键字取值。而每一个数字位上可取0~9的数字,故创建了包含10个队列的数组。 - 问题2:还是在基数排序RadixSort的代码中,不理解Character.digit方法
digit = Character.digit(temp.charAt(3-position), 10);,隐隐约约觉得Character是一个类,而digit是里面的静态方法,从代码的实现目的来看,应该是得到特殊位置的元素值。 - 问题2的解决:通过查询JavaAPI文档,得到如下的解释。

其实意思就是将3-position这个位置上的数字值返回。
代码实现时的问题作答 Exercise
-
1.在做pp9.2的时候程序写完后借用Contact的测试类来测试新的gapSort方法,没有报错但是排序直接没有改变。
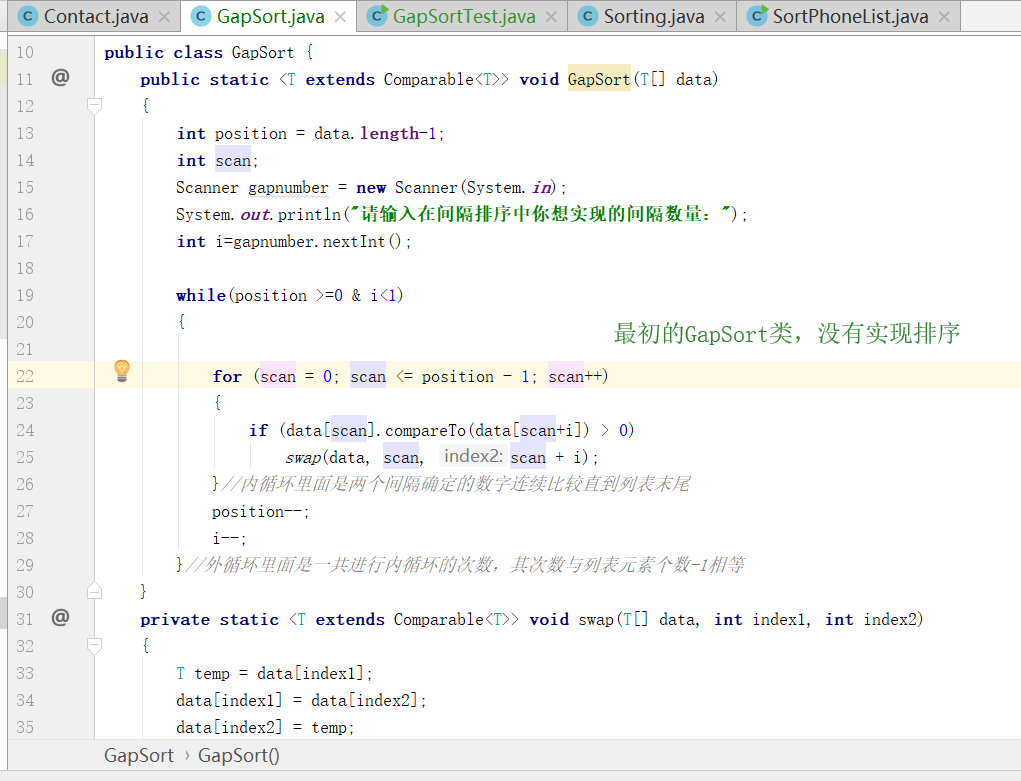
-
问题1的解决:其实是很简单的错误,又检查了一遍就发现了问题所在,当进行外循环的时候,while语句中应该是满足的条件,而不是跳出循环的条件,在内循环中,只要从比较
position-i次即可,这样所有数字都可以遍历比较到了。
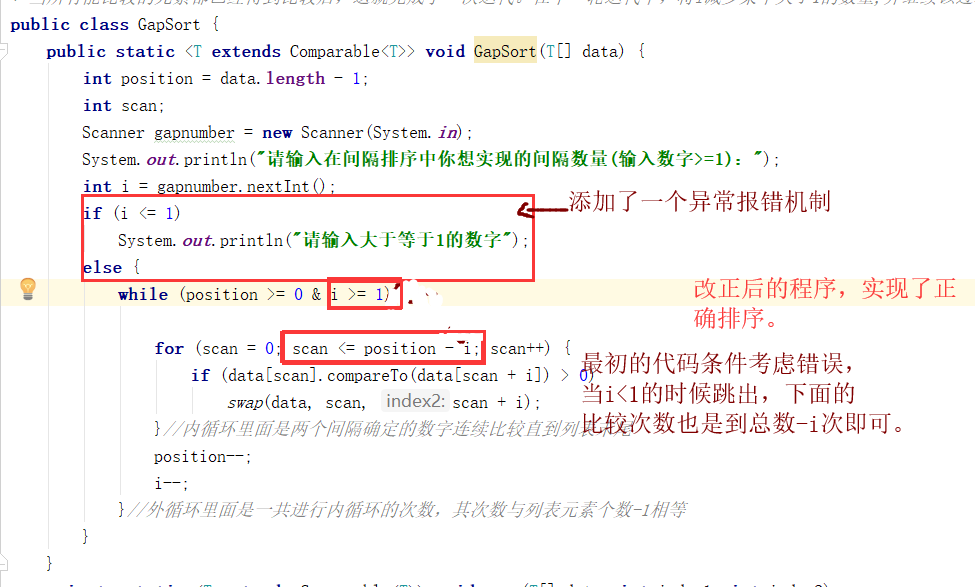
-
2:对pp9.3要求的“在每个排序法中添加代码以使得他们能够对总的比较次数和每一算法的总执行时间进行计数”中的计算时间不太了解。
-
问题2的解决:我找到啦java计算代码段运行时间
也就是在程序执行前获取当前系统时间,然后在程序执行完之后再获取此时的系统时间,两者相减就得到了该程序的运行时间。 -
代码也是很简洁明了の
第一种是以毫秒为单位计算的。
long startTime = System.currentTimeMillis(); //获取开始时间
doSomething(); //测试的代码段
long endTime = System.currentTimeMillis(); //获取结束时间
System.out.println("程序运行时间:" + (endTime - startTime) + "ms"); //输出程序运行时间
第二种是以纳秒为单位计算的。
long startTime=System.nanoTime(); //获取开始时间
doSomeThing(); //测试的代码段
long endTime=System.nanoTime(); //获取结束时间
System.out.println("程序运行时间: "+(endTime-startTime)+"ns");
上周测试活动错题改正 Correction
- 1.A circular array implementation of a queue is more efficient than a fixed array implementation of a queue because elements never have to be _________.(一个用循环数组实现的队列比起一个用普通数组实现的队列更高效是因为元素不需要?)
A .added(添加)
B .removed(删除)
C .shifted(移动)
D .initialized(初始化) - 问题的改正和理解:由于队列操作会修改集合的两端,因此将一端固定在索引0处要求移动元素,这样就会使得元素移位产生O(n)的复杂度,而环形数组可以除去在队列数组实现中把元素移位的需要。
本道题不该错,也不知道是点错了还是当时理解错题目了
码云链接
代码量(截图)
结对及互评Group Estimate
点评模板:
- 博客中值得学习的或问题:
- 20172301:这周的博客不仅交的早,质量也超级高。课本上的问题有关于
public static <T extends Comparable<? super T>>的理解实在到位,而且那个盘装水果真的妙啊。 - 20172304:这周的博客有点长哦(褒义的“有点”),很棒!对于pp9.3中的各种排序法的比较次数有自己的深入探讨,但是在博客上的解释我没怎么看懂,大概意思是自己又写了方法去调用计算?希望之后能一起讨论一下。
- 20172301:这周的博客不仅交的早,质量也超级高。课本上的问题有关于
- 本周结对学习内容:还没有在一起讨论学习, 周五课上应该会有讨论的吧!O(∩_∩)O
其他(感悟、思考等,可选)Else
纸上得来终觉浅,绝知此事要躬行。
在本周的学习过程中,其实连得来纸上也花费了一番功夫,尤其是后面的快速排序、归并排序和基数排序。
大二其实也不算清闲,每天过的还是很充实。曾经了解过工作外8小时决定人生理论,所以很多时候我们要去往哪里也是一点一点时间累积着告诉我们的。时间安排对一个成年人太重要了,我渐渐意识到自己的生命正因为有局限才有不同的阶段、不同的需要、不同的安排。
知道我是谁,我要做什么就好。
本来上面就是这周想说的全部内容了,但是又手欠看了几篇班里同学的博客,真的是太敬佩了。真的有一种我的作业太差了不敢交的感觉。就像小时候写作文写的不工整不敢交的感觉一模一样。捂脸逃跑~~~
学习进度条Learning List
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | |
|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 |
| 第一周 | 0/0 | 1/1 | 8/8 |
| 第二周 | 621/621 | 1/2 | 12/20 |
| 第三周 | 678/1299 | 1/3 | 10/30 |
| 第四周 | 2734/4033 | 1/4 | 20/50 |
| 第五周 | 1100/5133 | 1/5 | 20/70 |
参考资料Reference
- 《Java软件结构与数据结构》(第四版)
- 《JavaAPI文档》
- java计算代码段运行时间
- java快速排序原理
- java归并排序原理

