深度残差网络(ResNet)
前言
对于传统的深度学习网络应用来说,网络越深,所能学到的东西越多。当然收敛速度也就越慢,训练时间越长。但是如果简单地增加深度,会导致梯度弥散或梯度爆炸。对于该问题的解决方法是正则化初始化和在中间加入Batch Normalization,这样的话可以训练几十层的网络。
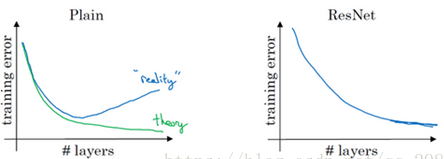
虽然通过上述方法 深层网络能够训练了,但是又会出现另一个问题,就是网络退化问题,网络层数增加,但是在训练集上的准确率却饱和甚至下降了。这个不能解释为overfitting,因为overfit应该表现为在训练集上表现更好才对。退化问题说明了深度网络没有很好地被优化。
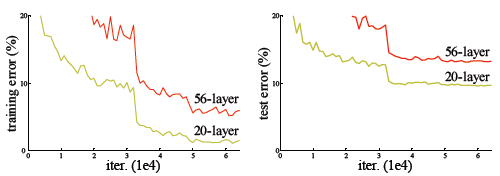
这种现象并不是由于过拟合导致的,过拟合是在训练集中把模型训练的太好,但是在新的数据中表现却不尽人意的情况。从上图可以看出,我们的训练准误差和测试误差在层数增加后皆变大了,这说明当网络层数变深后,深度网络变得难以训练。为什么这么说呢,因为56层的模型只要前20层和20层的模型参数一模一样,后面的36层只要做恒等映射$H(x)=x$,就能达到20层的效果,不可能更差,这就说明,恒等映射并不好学习,网络变得难以训练了。
如果大家还没理解的话,那我讲细一点,网络太深,模型就会变得不敏感,不同的图片类别产生了近似的对网络的刺激效果,这时候网络均方误差的减小导致最后分类的效果往往不会太好,所以解决思路就是引入这些相似刺激的“差异性因子”。
以卷积神经网络为例,我们都知道经过卷积神经网络的图像,都会起到一种有损压缩的效果,我们称之为“降采样”,产生的效果就是让输入向量在通过降低采样处理后具有更小的尺寸,主要目的是为了避免过拟合,以及有一定的减少运算量的作用。回过头来,我们可以联想到经过越多层数网络处理过的图像,“有损压缩”就越来越严重。
深度残差网络(ResNet)引入了残差块的设计,克服了这种由于网络深度的加深而产生的学习率变低、准确率无法有效提升的问题。
残差块
前面说到恒等映射较难学习$H(x)=x$较难学习,应该让网络去学习差异化因子,如果我们把网络设计为$H(x)=F(x)+x$,网络需要学习的残差就是$F(x)=H(x)-x$,只要$F(x)=0$,就能构成一个恒等映射$H(x)=x$。而且拟合残差肯定更容易。
残差块的原理为将前面网络层的输出 直接跳过多层 与后面网络层的输出进行相加。简单来说就是,前面较为“清晰”的数据和后面被“有损压缩”的数据 共同作为后面网络数据的输入。我们用$F(x)$表示没有跳跃连接的两层网络,则残差块的输出可以表示为$H(x)=F(x)+x$。F是求和前 网络映射,H是从输入到求和后的网络映射
残差块(Residual block)(也可以理解为跳跃连接)的结构如下图所示:
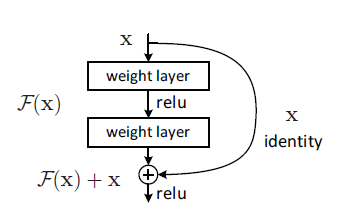
它有两层,我们用$\sigma$表示激活函数,如下表达式,
$$y=\sigma(F(x)+x$$
举个例子:比如把5映射到5.1,那么引入残差前是$F'(5)=5.1$,引入残差后是$H(5)=5.1$,如果用残差结构$H(5)=F(5)+5,\ F(5)=0.1$,从5.1变到5.2,F'增加了0.1/5=2%,对于残差结构F(5)从0.1变到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,所以效果更好。残差的思想都是去掉相同的主体部分,从而突出微小的变化。
这个残差块往往需要两层以上,单单一层的残差块并不能起到提升作用。这种残差学习结构可以通过前向神经网络+shortcut连接实现,如结构图1所示。而且shortcut连接相当于简单执行了同等映射,不会产生额外的参数,也不会增加计算复杂度。 而且,整个网络可以依旧通过端到端的反向传播训练。
ImageNet上的实验证明了何凯文提出的加深的残差网络能够比简单叠加层生产的深度网络更容易优化,而且,因为深度的增加,结果得到了明显提升。另外在CIFAR-10数据集上相似的结果以及一系列大赛的第一名结果表明ResNet是一个通用的方法。 残差网络的确解决了退化的问题,在训练集和校验集上,都证明了的更深的网络错误率越小,如下图

实际中,考虑计算的成本,对残差块做了计算优化,即将两个3x3的卷积层替换为1x1 + 3x3 + 1x1,如下图。新结构中使用了1*1卷积来削减和恢复维度,既保持了精度又减少了计算量。
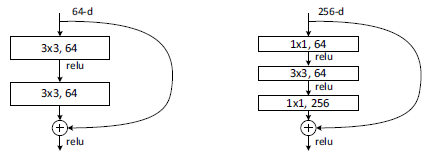
上面是两种不同的跳跃结构,主要就是使用了不同的卷积核。左边参数要比右边的多一倍。所以当网络很深时,用右边的比较好。
残差神经网络
下图是一个普通网络

下图是一个残差网络(ResNet)
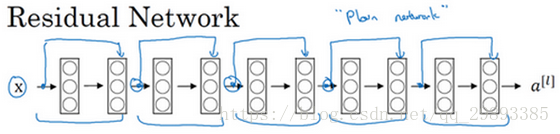
由此可见,把普通网络变成ResNet的方法就是加上跳跃连接,每两层增加一个shortcut,构成一个残差块。
对于跳跃结构,当输入与输出的维度一样时,不需要做其他处理,两者相加就可,但当两者维度不同时,输入要进行变换以后去匹配输出的维度,主要经过两种方式,1)用zero-padding去增加维度,2)用1x1卷积来增加维度。
普通的神经网络,随着网络深度的加深,训练错误会越来越多。但有了ResNets就不一样了,即使网络再深,训练的表现却不错,比如说训练误差减少,这种方式确实有助于解决梯度消失和梯度爆炸问题,让我们在训练更深网络的同时,又能保证良好的性能。
python实现残差网络
https://github.com/ry/tensorflow-resnet
https://github.com/raghakot/keras-resnet/blob/master/resnet.py
前者还可以从网上下载一个pretrained Model的模型,我们可以认为是具有一定识别能力的“半成品”
参考文献
何恺明的论文ResNet V1:Deep Residual Learning for Image Recognition
何恺明的论文ResNet V2:Identity Mappings in Deep Residual Networks
CSDN博主的--深度学习笔记(七)--ResNet(残差网络)
CSDN博主三百斤菠萝--ResNet论文笔记

