

《Metadata Tables》第6章 Correlating Metadata Tables
![]()
6. Correlating Metadata Tables
In all the previous chapters that we presented, we had elucidated all the concepts and tables through distinct programs. In this chapter, we have endeavored to inscribe a single program, which encompasses all the tables and displays meaningful output. In lieu of displaying references to various tables, such as typeDef[1], MethodRef[2] etc., we shall display the actual values existent at these locations. Thus, we have essayed to resolve all the cross-references and to display the metadata information in a comprehensive manner.
But, prior to embarking on the explanation of this gargantuan program, which cross-references all the tables, we wish to shed light on a few crucial aspects.
Every table in the metadata world is constituted of fields. Moreover, even a structure is essentially a collection of fields. Therefore, in the C# program, we have represented the metadata tables in a structure.
For instance, we have created an ExportedTypeTable as a structure tag, which contains multiple fields. The structure in essence, is a logical entity, which has no physical existence. Hence, we generate an actual structure by creating a variable of the structure tag named ExportedTypeTableStruct. A structure is a value type, and hence, it does not have to be instantiated.
The variable ExportedTypeTableStruct is declared as an array of structures.
public struct ExportedTypeTable { public int flags ; public int typedefindex ; public int name ; public int nspace ; public int coded ; } public ExportedTypeTable [] ExportedTypeStruct;
The program gets underway by creating a structure tag for every table in the metadata. We have proffered the entire program to you, despite being aware of the fact that it would run into reams of pages. Before you get going with the main program, compile b.cs in the c:\mdata subdirectory and generate the file b.exe. The metadata information of this executable will be displayed in the output.
b.cs
using System.Runtime.InteropServices; using System; public class zzz { static int i; const int j = 2; public event EventHandler a; public event EventHandler b; [DllImport("user32.dll")] public static extern int MessageBox(int hWnd, String text, String caption, uint type); public static void Main() { i = 10; Console.WriteLine("hell {0}", i); } public int abc(float k) { return 0; } public long pqr(int[] i, char j) { return 0; } public void xyz() { } } public class yyy : iii { public int aa { set { } get { return 10; } } public string bb { set { } get { return "hi"; } } public long uuu(int i, char[] j) { return 0; } void iii.xxx() { Console.WriteLine("hello"); } public unsafe void aaa() { } } interface iii { void xxx(); } public class uuu : yyy { class a1 { } }
a.txt
author=vijay
book=metadata
>resgen a.txt
>csc b.cs /res:a.resources /unsafe
a.cs
代码太长,在这里下载
Output
输出太长,在这里下载
The Main function in the zzz class calls the abc function, which launches forthwith the task of displaying information from the metadata table, by calling other functions.
public void abc(string [] args) { InitializeObjects(args); ReadPEStructures(); DisplayPEStructures(); ImportAdressTable(); CLRHeader(); ReadStreamsData(); FillTableSizes(); ReadTablesIntoStructures(); DisplayTableForDebugging(); }
The first function to be called is InitializeObject.
public void InitializeObjects(string[] args) { tablenames = new String[]{ "Module" , "TypeRef" , "TypeDef" ,"FieldPtr","Field", "MethodPtr","Method", "ParamPtr" , "Param", "InterfaceImpl", "MemberRef", "Constant", "CustomAttribute", "FieldMarshal", "DeclSecurity", "ClassLayout", "FieldLayout", "StandAloneSig" , "EventMap","EventPtr", "Event", "PropertyMap", "PropertyPtr", "Properties","MethodSemantics", "MethodImpl","ModuleRef","TypeSpec","ImplMap","FieldRVA","ENCLog","ENCMap", "Assembly", "AssemblyProcessor","AssemblyOS","AssemblyRef", "AssemblyRefProcessor","AssemblyRefOS", "File","ExportedType", "ManifestResource","NestedClass","TypeTyPar","MethodTyPar" }; if (args.Length == 0) filename = "C:\\mdata\\b.exe"; else filename = args[0]; }
This function verifies if the executable has been called with any command line arguments or not. If the executable has been called with a single argument, i.e. >a mscorlib.dll, the 0th member becomes the first argument, i.e. mscorlib.dll and the length member becomes a non-zero number. In the case where command line arguments have not been supplied, the file named b.exe gets scrutinized by default. We have tried and tested this program with mscorlib.dll, and with various other dlls that are furnished together with the .Net framework. You may disassemble the main program to authenticate whether the output relates to the program file or not. Just make a copy of a.exe as bb.exe, and then, run the program as
>a bb.exe
Every metadata table is identified by a name and an id. The first table has an id of 0 and the name of 'module'. Similarly, the second table has an id of 1 and the name of 'TypeDef'. There are a total of 43 such defined tables. However, in the IL disassembled mode, the name is not stored anywhere, since the table is referenced by its id. So, in order to display a readable output, we have stored the tables' names in an array, where the offset in the array can be regarded as the id.
We start deciphering the file contents from the next function named ReadPEStructures. The PE file header is read first, followed by the Image Optional Header. The virtual address, size of rawdata and pointer to rawdata, are all stored in separate arrays.
The function DisplayPEStructures displays the output as emitted by the Microsoft ILDASM program utility. Also, the functions of ImportAddressTable and DisplayFromFile facilitate the display of the output as depicted by the utility.
The Data Directory renders information about where the Directories begin, i.e. its Relative Virtual Address (RVA) and the size. An RVA is a memory location. However, since the file is read from the disk and is not loaded into the memory, the disk locations of these directories need to be ascertained. The DisplayDataDirectory function prints out these details in a proper format for every directory.
The second last data directory member, i.e. CLR header, is a recipient of special treatment, since it forms the very foundation of the metadata information. The CLRHeader function details every aspect of the header.
The PE file format has a sections table, which is a series of structures containing variegated information about data code, etc. It also stores the starting locations of these sections in both, the memory and on the disk, together with the size of each section. The ConvertRVA function determines the actual disk location of a section whose memory location has been provided.
The metadata header is read into different variables and then, these details are displayed using the WriteLine function.
The next function to be called in the abc function is ReadStreamsData(). It is very similar to what we have observed in the earlier chapters. The lone dissimilarity is that, the variable startofmetadata has been initialized using the ConvertRVA function. The filepointer is then positioned at the startofmetadata in memory, by using the Position property in the stream. A vital point to be taken into account is that, everything in the .Net world is aligned at 4.
In the .Net world, the metadata tables are stored as offsets or indexes in the streams of String, GUID or Blob. The question that crops up now is, whether these indexes should take up 2 bytes or 4 bytes. The answer depends entirely on the stream sizes.
If the stream size is upto 64K, then the index field takes up 2 byes. However, if it exceeds 64K, then the index takes up 4 bytes. The designers of metadata could have stringently fixed it at 4 bytes, but they were quick to realize that this approach would result in excessive wastage of space. Thus, it is amply evident that the metadata concept has been primarily designed for efficiency.
Five arrays have been created for the five streams. Then, the data contained within the streams is stored within them. Thereafter, the details of the streams, barring the #~ stream, are printed out.
The 6th byte from the start of the metadata header is a byte called heapsize. Out of the 8 bits, 3 bits are inspected to ascertain the size of the index. If the first bit is on, the string size is larger than 64 K, and therefore, the offsetstring variable is set to 4.
if ((heapsizes & 0x01) == 0x01)
offsetstring = 4;
Similarly, the second and the third bits are checked, and if these bits are on, the variables of offsetguid and offsetblob are assigned a value of 4 each, respectively.
if ((heapsizes & 0x02) == 0x02) offsetguid = 4; if ((heapsizes & 0x04) == 0x04) offsetblob = 4;
By default, the three variables of offsetstring, offsetguid and offsetblob are initialized to a value of 3. Thereafter, to eschew any further complications, the functions of ReadStringIndex, ReadGuidIndex and ReadBlobIndex determine the values of the offset variables offsetstring, offsetguid and offsetblob, respectively; it is done whenever indexes are to be read off the stream. If the value is set to 2, the Int16 converter is used, however if it is 4, the converter of Int32 is employed.
All the earlier programs in this book had utilized small program snippets. As a consequence, the values never exceeded 64 K. Therefore, we had worked under the assumption that the value is 2 bytes.
An index into a table may also be either 2 bytes or 4 bytes. However, we have set the value to 2, assuming that the tablesizes, i.e. the rows in the tables, shall never exceed 64K.
public int GetTableSize() { return 2; }
The apposite approach here would be to ascertain if the rows exceed 64K in the rows array; and based on the value, either 2 or 4 shall be returned.
As perceived in the earlier programs, before the function ReadStreamsData terminates, the tables in the valid field are inspected, and simultaneously, the number of rows that it contains is placed in the rows array.
Once the rows size array is filled up, the size of every table is checked to fill up the sizes array. The most imperative function here is the GetCodedIndexSize function. Let us consider a specific case where the tablesize of the typeref table is to be ascertained. The function of GetCodedIndexSize("ResolutionScope") is called to establish whether the size of the field is 2 bytes or 4 bytes.
Thus, the GetCodedIndexSize function gets called, and the 'if' statement that checks for the ReolutionScope, returns True. Then, the following statements get executed:
if (rows[0x00] >= 8192 || rows[0x1a] >= 8192 || rows[0x23] >= 8192 || rows[0x01] >= 8192) return 4; else return 2;
For those with an evasive memory, the resolutionscope is an index into one of the 4 tables, i.e. Module, ModuleRef, AssemblyRef or TypeRef, having the id of 0x00, 0x1a, 0x23 and 0x01, respectively. In one of the earlier chapters, we had observed that if the three bits held the value of 0, it referred to the module table. A value of 1 was for moduleref, 3 was for assemblyref and 4 was for typeref. In the GetCodedIndexSize function, the rows in these three tables are verified to establish if they exceed 8192, i.e. 2^13, since the remaining 3 bits of 2 bytes are occupied by the table references. If they do, the resolutionscope takes up 4 bytes, or else, it occupies 2 bytes.
In brief, GetCodedIndexSize takes a string parameter, which is the name of the coded index. It uses the rows array to determine if the rows for the table exceed the 2 byte limit. This is accomplished by subtracting the bits that have been utilized for the table. If this is the case, then 4 bytes are used for accommodating the resolutionscope.
The sizes of these tables are never constant. If the rows expand in size, then the number of bytes that are consumed to accommodate these, also undergoes expansion. For the MemberRef table, out of the 3 fields, the first one is the coded index, the second is an index to the string, while the third one is an index into the Blob. In case of the table being small, the fields can be assumed to have a size of 2 bytes each, thus resulting in a total size of 6 bytes. However, this assumption is far from being technically accurate. Thus, GetCodedIndexSize dynamically assigns the size for the coded index field in the tables.
The computed sizes of these tables are stored in the sizes array. Thus, to retrieve the size of the MemberRef table, you can merely use size[0x0a].
The tablepresent function computes the offset of every table and stores it in the variable tableoffset. It returns a boolean value of True, if the table is present in the metadata stream; however, in case of its absence, it returns a value of False.
This nugget of information is exploited in the next function named ReadTablesIntoStructures. If the table exists, an array of structures is created, which is large enough to store all the rows in the table. We have appended an additional structure to the quantity in existence, since we would be ignoring the 0th member in the array and shall be starting the array index from 1. Every member in the structure is then filled up for the entire array. This has been repeated for all the tables.
Once the structures are filled up, the function of DisplayTableForDebugging() is called, which displays the information stored in every table of the file.
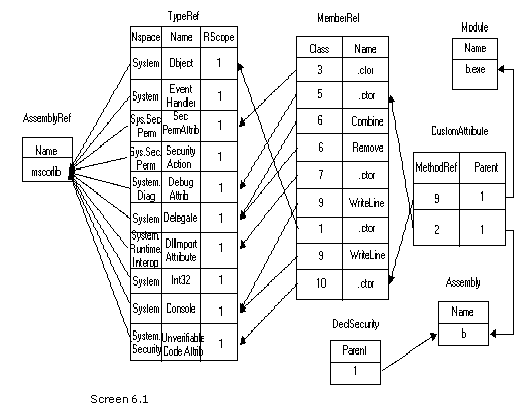
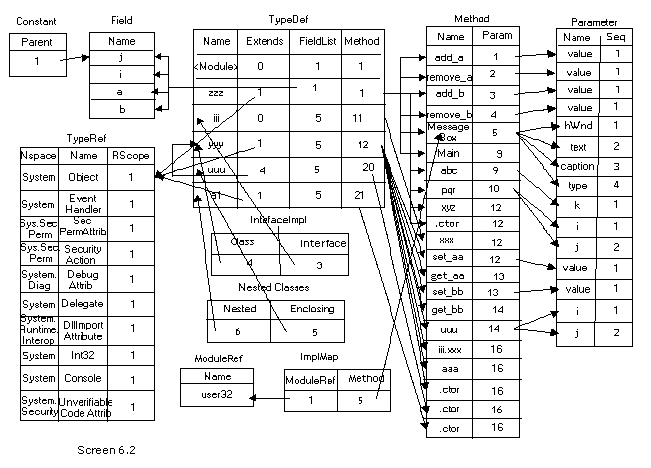
We have already explicated each one of the tables in great detail earlier. The only divergence here is that, the cross references to several tables are specified in values, along with other relevant information. For example, the function of DisplayTypeDefTable generates a lot more information, as compared to what we had encountered earlier.
The DisplayTable function called in this function, returns intelligent information. It takes two parameters, viz. the tablename and the index. Let us consider the case of class zzz, which is the second row in the typedef table. The function DisplayTable is called with the table name of TypeRef and with an index of 1. Since the table is TypeRef, the function GetTypeRefTable is called with the index parameter.
In GetTypeRefTable, the value in the name field is extracted from the typeref structure, with the index variable comporting itself as the row number. Moreover, the namespace is also retrieved. If the namespace is not null, then a dot is specified after the namespace name.
Finally, using the GetString function, the actual name is obtained, which is then specified as the return value. Thus, in place of TypeRef[1], we see the value of System.Object.
Apart from this, all the methods contained in the class are also displayed, using the DisplayAllMethods function. This function is passed the rowindex member named ii, as the parameter. The mindex member of the structure provides the starting method index owned by the type. Thus, we have stored it in the variable named 'start'. However, there is no technique of ascertaining the last method owned by the type. Yet again, the ease of understanding has been sacrificed at the altar of efficiency.
In order to obtain the last method, the next typedef member is checked. The function pointed by this typedef, marks the new set of functions owned by the next type. Thus, it can be safely concluded that all functions preceding the new set, are owned by the current type. The difference between startofnext and start belong to the current type. Then, by employing a 'for' loop, all the methods falling within the range are displayed.
A small glitch rears its head, if the type happens to be the last type in the typedeftable.
In such a case, the startofnext variable is initialized to the length of the methodstruct -1. So, when the index in the typedef table corresponds to the last entry in the table, all methods from the start upto the end of methods in the method table, are assigned to the type. Moreover, when two types share the same start, it is assumed that the current typedef does not enclose any methods in it.
The same rules have been applied while displaying all fields, events, parameters and properties.
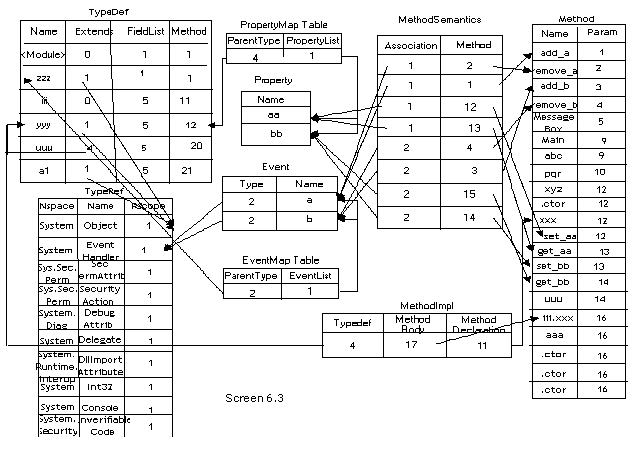
We have chosen to abstain from explicating any more code, since a large quantum of it has already been elucidated in the preceding chapters in diminutive bits and pieces. However, there are a few things that have been left unfinished, such as complex types, which have not been attended to; and signatures, which have not been decoded in their entirety.
We set aside these as an exercise for you, since these have already been expounded in considerable detail in the earlier chapters. One can synthesize all this knowledge and write a thesis on the subject with effortless ease. However, we are going to save you this effort, since our next book shall cater to all these requests with a re-production of Microsoft's IL disassembler utility, using the C# language. It shall incorporate all the formatting issues too. Au revoir!

