

Java中的equals和hashCode方法
本文转载自:Java中的equals和hashCode方法详解
Java中的equals方法和hashCode方法是Object中的,所以每个对象都是有这两个方法的,有时候我们需要实现特定需求,可能要重写这两个方法。
equals()和hashCode()方法是用来在同一类中做比较用的,尤其是在容器里如set存放同一类对象时用来判断放入的对象是否重复。
这里我们首先要明白一个问题:
equals()相等的两个对象,hashcode()一定相等,equals()不相等的两个对象,却并不能证明他们的hashcode()不相等。换句话说,equals()方法不相等的两个对象,hashCode()有可能相等。(我的理解是由于哈希码在生成的时候产生冲突造成的)在这里hashCode就好比字典里每个字的索引,equals()好比比较的是字典里同一个字下的不同词语。就好像在字典里查“自”这个字下的两个词语“自己”、“自发”,如果用equals()判断查询的词语相等那么就是同一个词语,比如equals()比较的两个词语都是“自己”,那么此时hashCode()方法得到的值也肯定相等;如果用equals()方法比较的是“自己”和“自发”这两个词语,那么得到结果是不想等,但是这两个词都属于“自”这个字下的词语所以在查索引时相同,即:hashCode()相同。如果用equals()比较的是“自己”和“他们”这两个词语的话那么得到的结果也是不同的,此时hashCode() 得到也是不同的。
反过来:hashcode()不等,一定能推出equals()也不等;hashcode()相等,equals()可能相等,也可能不等。在object类中,hashcode()方法是本地方法,返回的是对象的地址值,而object类中的equals()方法比较的也是两个对象的地址值,如果equals()相等,说明两个对象地址值也相等,当然hashcode() 也就相等了;
同时hash算法对于查找元素提供了很高的效率
如果想查找一个集合中是否包含有某个对象,大概的程序代码怎样写呢?
你通常是逐一取出每个元素与要查找的对象进行比较,当发现某个元素与要查找的对象进行equals方法比较的结果相等时,则停止继续查找并返回肯定的信息,否则,返回否定的信息,如果一个集合中有很多个元素,比如有一万个元素,并且没有包含要查找的对象时,则意味着你的程序需要从集合中取出一万个元素进行逐一比较才能得到结论。
有人发明了一种哈希算法来提高从集合中查找元素的效率,这种方式将集合分成若干个存储区域,每个对象可以计算出一个哈希码,可以将哈希码分组(使用不同的hash函数来计算的),每组分别对应某个存储区域,根据一个对象的哈希吗就可以确定该对象应该存储在哪个区域HashSet就是采用哈希算法存取对象的集合,它内部采用对某个数字n进行取余(这种的hash函数是最简单的)的方式对哈希码进行分组和划分对象的存储区域;Object类中定义了一个hashCode()方法来返回每个Java对象的哈希码,当从HashSet集合中查找某个对象时,Java系统首先调用对象的hashCode()方法获得该对象的哈希码表,然后根据哈希吗找到相应的存储区域,最后取得该存储区域内的每个元素与该对象进行equals方法比较;这样就不用遍历集合中的所有元素就可以得到结论,可见,HashSet集合具有很好的对象检索性能,但是,HashSet集合存储对象的效率相对要低些,因为向HashSet集合中添加一个对象时,要先计算出对象的哈希码和根据这个哈希码确定对象在集合中的存放位置为了保证一个类的实例对象能在HashSet正常存储,要求这个类的两个实例对象用equals()方法比较的结果相等时,他们的哈希码也必须相等;也就是说,如果obj1.equals(obj2)的结果为true,那么以下表达式的结果也要为true:
obj1.hashCode() == obj2.hashCode()
换句话说:当我们重写一个对象的equals方法,就必须重写他的hashCode方法,不过不重写他的hashCode方法的话,Object对象中的hashCode方法始终返回的是一个对象的hash地址,而这个地址是永远不相等的。所以这时候即使是重写了equals方法,也不会有特定的效果的,因为hashCode方法如果都不想等的话,就不会调用equals方法进行比较了,所以没有意义了。
如果一个类的hashCode()方法没有遵循上述要求,那么,当这个类的两个实例对象用equals()方法比较的结果相等时,他们本来应该无法被同时存储进set集合中,但是,如果将他们存储进HashSet集合中时,由于他们的hashCode()方法的返回值不同(Object中的hashCode方法返回值是永远不同的),第二个对象首先按照哈希码计算可能被放进与第一个对象不同的区域中,这样,它就不可能与第一个对象进行equals方法比较了,也就可能被存储进HashSet集合中了,Object类中的hashCode()方法不能满足对象被存入到HashSet中的要求,因为它的返回值是通过对象的内存地址推算出来的,同一个对象在程序运行期间的任何时候返回的哈希值都是始终不变的,所以,只要是两个不同的实例对象,即使他们的equals方法比较结果相等,他们默认的hashCode方法的返回值是不同的。
下面来看一下一个具体的例子:
RectObject对象:
1 public class RectObject { 2 public int x; 3 public int y; 4 public RectObject(int x,int y){ 5 this.x = x; 6 this.y = y; 7 } 8 @Override 9 public int hashCode(){ 10 final int prime = 31; 11 int result = 1; 12 result = prime * result + x; 13 result = prime * result + y; 14 return result; 15 } 16 @Override 17 public boolean equals(Object obj){ 18 if(this == obj) 19 return true; 20 if(obj == null) 21 return false; 22 if(getClass() != obj.getClass()) 23 return false; 24 final RectObject other = (RectObject)obj; 25 if(x != other.x){ 26 return false; 27 } 28 if(y != other.y){ 29 return false; 30 } 31 return true; 32 } 33 }
我们重写了父类Object中的hashCode和equals方法,看到hashCode和equals方法中,如果两个RectObject对象的x,y值相等的话他们的hashCode值是相等的,同时equals返回的是true;
下面是测试代码:
1 import java.util.HashSet; 2 public class Demo { 3 public static void main(String[] args){ 4 HashSet<RectObject> set = new HashSet<RectObject>(); 5 RectObject r1 = new RectObject(3,3); 6 RectObject r2 = new RectObject(5,5); 7 RectObject r3 = new RectObject(3,3); 8 set.add(r1); 9 set.add(r2); 10 set.add(r3); 11 set.add(r1); 12 System.out.println("size:"+set.size()); 13 } 14 }
我们向HashSet中存入到了四个对象,打印set集合的大小,结果是多少呢?
运行结果:size:2
为什么会是2呢?这个很简单了吧,因为我们重写了RectObject类的hashCode方法,只要RectObject对象的x,y属性值相等那么他的hashCode值也是相等的,所以先比较hashCode的值,r1和r2对象的x,y属性值不等,所以他们的hashCode不相同的,所以r2对象可以放进去,但是r3对象的x,y属性值和r1对象的属性值相同的,所以hashCode是相等的,这时候在比较r1和r3的equals方法,因为他么两的x,y值是相等的,所以r1,r3对象是相等的,所以r3不能放进去了,同样最后再添加一个r1也是没有没有添加进去的,所以set集合中只有一个r1和r2这两个对象
下面我们把RectObject对象中的hashCode方法注释,即不重写Object对象中的hashCode方法,在运行一下代码:
运行结果:size:3
这个结果也是很简单的,首先判断r1对象和r2对象的hashCode,因为Object中的hashCode方法返回的是对象本地内存地址的换算结果,不同的实例对象的hashCode是不相同的,同样因为r3和r1的hashCode也是不相等的,但是r1==r1的,所以最后set集合中只有r1,r2,r3这三个对象,所以大小是3
下面我们把RectObject对象中的equals方法中的内容注释,直接返回false,不注释hashCode方法,运行一下代码:
运行结果:size:3
这个结果就有点意外了,我们来分析一下:
首先r1和r2的对象比较hashCode,不相等,所以r2放进set中,再来看一下r3,比较r1和r3的hashCode方法,是相等的,然后比较他们两的equals方法,因为equals方法始终返回false,所以r1和r3也是不相等的,r3和r2就不用说了,他们两的hashCode是不相等的,所以r3放进set中,再看r4,比较r1和r4发现hashCode是相等的,在比较equals方法,因为equals返回false,所以r1和r4不相等,同一r2和r4也是不相等的,r3和r4也是不相等的,所以r4可以放到set集合中,那么结果应该是size:4,那为什么会是3呢?
这时候我们就需要查看HashSet的源码了,下面是HashSet中的add方法的源码:
1 /** 2 * Adds the specified element to this set if it is not already present. 3 * More formally, adds the specified element <tt>e</tt> to this set if 4 * this set contains no element <tt>e2</tt> such that 5 * <tt>(e==null ? e2==null : e.equals(e2))</tt>. 6 * If this set already contains the element, the call leaves the set 7 * unchanged and returns <tt>false</tt>. 8 * 9 * @param e element to be added to this set 10 * @return <tt>true</tt> if this set did not already contain the specified 11 * element 12 */ 13 public boolean add(E e) { 14 return map.put(e, PRESENT)==null; 15 }
这里我们可以看到其实HashSet是基于HashMap实现的,我们在点击HashMap的put方法,源码如下:
1 /** 2 * Associates the specified value with the specified key in this map. 3 * If the map previously contained a mapping for the key, the old 4 * value is replaced. 5 * 6 * @param key key with which the specified value is to be associated 7 * @param value value to be associated with the specified key 8 * @return the previous value associated with <tt>key</tt>, or 9 * <tt>null</tt> if there was no mapping for <tt>key</tt>. 10 * (A <tt>null</tt> return can also indicate that the map 11 * previously associated <tt>null</tt> with <tt>key</tt>.) 12 */ 13 public V put(K key, V value) { 14 if (key == null) 15 return putForNullKey(value); 16 int hash = hash(key); 17 int i = indexFor(hash, table.length); 18 for (Entry<K,V> e = table[i]; e != null; e = e.next) { 19 Object k; 20 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { 21 V oldValue = e.value; 22 e.value = value; 23 e.recordAccess(this); 24 return oldValue; 25 } 26 } 27 28 modCount++; 29 addEntry(hash, key, value, i); 30 return null; 31 }
我们主要来看一下if的判断条件,
首先是判断hashCode是否相等,不相等的话,直接跳过,相等的话,然后再来比较这两个对象是否相等或者这两个对象的equals方法,因为是进行的或操作,所以只要有一个成立即可,那这里我们就可以解释了,其实上面的那个集合的大小是3,因为最后的一个r1没有放进去,以为r1==r1返回true的,所以没有放进去了。所以集合的大小是3,如果我们将hashCode方法设置成始终返回false的话,这个集合就是4了。
最后我们在来看一下hashCode造成的内存泄露的问题:看一下代码:
1 import java.util.HashSet; 2 public class Demo { 3 public static void main(String[] args){ 4 HashSet<RectObject> set = new HashSet<RectObject>(); 5 RectObject r1 = new RectObject(3,3); 6 RectObject r2 = new RectObject(5,5); 7 RectObject r3 = new RectObject(3,3); 8 set.add(r1); 9 set.add(r2); 10 set.add(r3); 11 r3.y = 7; 12 System.out.println("删除前的大小size:"+set.size()); 13 set.remove(r3); 14 System.out.println("删除后的大小size:"+set.size()); 15 } 16 }
运行结果:
删除前的大小size:3
删除后的大小size:3
发现一个问题了,而且是个大问题呀,我们调用了remove删除r3对象,以为删除了r3,但事实上并没有删除,这就叫做内存泄露,就是不用的对象但是他还在内存中。所以我们多次这样操作之后,内存就爆了。看一下remove的源码:
1 /** 2 * Removes the specified element from this set if it is present. 3 * More formally, removes an element <tt>e</tt> such that 4 * <tt>(o==null ? e==null : o.equals(e))</tt>, 5 * if this set contains such an element. Returns <tt>true</tt> if 6 * this set contained the element (or equivalently, if this set 7 * changed as a result of the call). (This set will not contain the 8 * element once the call returns.) 9 * 10 * @param o object to be removed from this set, if present 11 * @return <tt>true</tt> if the set contained the specified element 12 */ 13 public boolean remove(Object o) { 14 return map.remove(o)==PRESENT; 15 }
然后再看一下remove方法的源码:
1 /** 2 * Removes the mapping for the specified key from this map if present. 3 * 4 * @param key key whose mapping is to be removed from the map 5 * @return the previous value associated with <tt>key</tt>, or 6 * <tt>null</tt> if there was no mapping for <tt>key</tt>. 7 * (A <tt>null</tt> return can also indicate that the map 8 * previously associated <tt>null</tt> with <tt>key</tt>.) 9 */ 10 public V remove(Object key) { 11 Entry<K,V> e = removeEntryForKey(key); 12 return (e == null ? null : e.value); 13 }
在看一下removeEntryForKey方法源码:
1 /** 2 * Removes and returns the entry associated with the specified key 3 * in the HashMap. Returns null if the HashMap contains no mapping 4 * for this key. 5 */ 6 final Entry<K,V> removeEntryForKey(Object key) { 7 int hash = (key == null) ? 0 : hash(key); 8 int i = indexFor(hash, table.length); 9 Entry<K,V> prev = table[i]; 10 Entry<K,V> e = prev; 11 12 while (e != null) { 13 Entry<K,V> next = e.next; 14 Object k; 15 if (e.hash == hash && 16 ((k = e.key) == key || (key != null && key.equals(k)))) { 17 modCount++; 18 size--; 19 if (prev == e) 20 table[i] = next; 21 else 22 prev.next = next; 23 e.recordRemoval(this); 24 return e; 25 } 26 prev = e; 27 e = next; 28 } 29 30 return e; 31 }
我们看到,在调用remove方法的时候,会先使用对象的hashCode值去找到这个对象,然后进行删除,这种问题就是因为我们在修改了r3对象的y属性的值,又因为RectObject对象的hashCode方法中有y值参与运算,所以r3对象的hashCode就发生改变了,所以remove方法中并没有找到r3了,所以删除失败。即r3的hashCode变了,但是他存储的位置没有更新,仍然在原来的位置上,所以当我们用他的新的hashCode去找肯定是找不到了。
其实上面的方法实现很简单的:如下图:
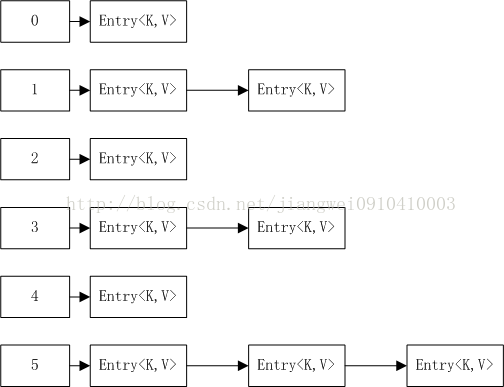
很简单的一个线性的hash表,使用的hash函数是mod,源码如下:
1 /** 2 * Returns index for hash code h. 3 */ 4 static int indexFor(int h, int length) { 5 return h & (length-1); 6 }
这个其实就是mod运算,只是这种运算比%运算要高效。
1,2,3,4,5表示是mod的结果,每个元素对应的是一个链表结构,所以说想删除一个Entry<K,V>的话,首先得到hashCode,从而获取到链表的头结点,然后再遍历这个链表,如果hashCode和equals相等就删除这个元素。
上面的这个内存泄露告诉我一个信息:如果我们将对象的属性值参与了hashCode的运算中,在进行删除的时候,就不能对其属性值进行修改,否则会出现严重的问题。
其实我们也可以看一下8种基本数据类型对应的对象类型和String类型的hashCode方法和equals方法。
其中8中基本类型的hashCode很简单就是直接返回他们的数值大小,String对象是通过一个复杂的计算方式,但是这种计算方式能够保证,如果这个字符串的值相等的话,他们的hashCode就是相等的。8种基本类型的equals方法就是直接比较数值,String类型的equals方法是比较字符串的值的。
转载自:http://blog.csdn.net/jiangwei0910410003/article/details/22739953

