
UFLDL深度学习笔记 (二)SoftMax 回归(矩阵化推导)
UFLDL深度学习笔记 (二)Softmax 回归
本文为学习“UFLDL Softmax回归”的笔记与代码实现,文中略过了对代价函数求偏导的过程,本篇笔记主要补充求偏导步骤的详细推导。
1. 详细推导softmax代价函数的梯度
经典的logistics回归是二分类问题,输入向量$ x{(i)}\in\Re$ 输出0,1判断\(y^{(i)}\in{\{0,1\}}\),Softmax回归模型是一种多分类算法模型,如图所示,输出包含k个类型,\(y^{(i)}\in{\{0,1,…,k\}}\)。
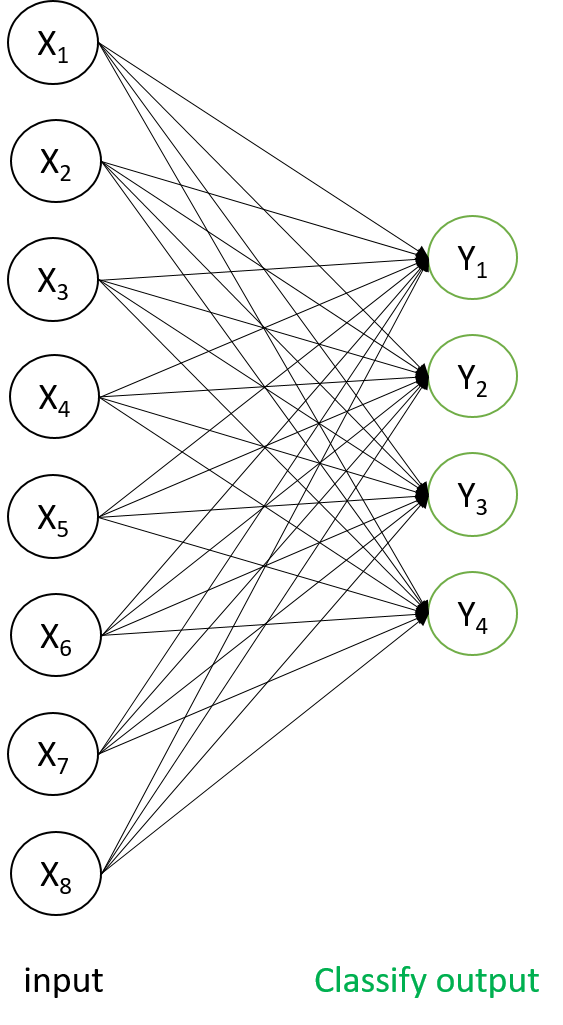
在经典的多分类问题MNIST数字识别任务中包含0-9十个手写数字。softmax的思路是将输入值直接判决为k个类别的概率,这里就需要一个判决函数,softmax采用指数形式。求和的倒数是为了归一化概率。
为了矩阵运算方便,将权重参数记作矩阵形式 $$\theta = \begin{bmatrix} \theta_1^T \ \theta_2^T\\vdots\ \theta_k^T\\end{bmatrix}_{k\times(n+1)}$$
包含权重惩罚项的softmax的代价函数为
原文Softmax回归中略过了求偏导的过程,下文对其做分步推导。\(\theta_j\)是行向量,表示每个输入x与第j个输出分类连接的权重, 将对数内除法拆分为减法可得:
对\(\theta_j\)求偏导,可得:
这样我们得到了代价函数对参数权重的梯度,类似前篇稀疏自编码的做法,需要做以下步骤:
- 结合梯度下降法,使用训练数据求出参数权重\(\theta\)的最优解;
- 用训练过的权重对测试数据做前向传播,每个测试数据得到\(k\)个软判决输出值,分别表示判决为\(1…k\)分类的概率;
- 选取\(k\)个中的最大值即为对测试数据的分类结果;
- 与测试数据集的真实输出对比统计获得预测准确率。
2. 偏导的矩阵化表示
当真正编写代码时会发现上述梯度公式是对行向量\(\theta\)的,UFLDL没有给出矩阵公式,矩阵表达又该是怎样呢?请看下文推导。
基本符号表达式这样的:
输入数据:\(X_{(n+1) \times m}\)
概率矩阵:\(norm(exp(\theta_{k\times (n+1)} \times X_{(n+1) \times m}) )= P_{k\times m}\)
1函数表示第i个输入的输出值是否为分类j,遍历所有输入、输出得到矩阵 $ G_{k \times m}$,称为groundTruth.
偏导第j行的向量为输入数据每一行(共n+1行)与\(G_{k \times m} P_{k \times m}\)的每一行的点积,加上\(\lambda\theta_j\) 本身:
再进一步写成矩阵形式:
好了,矩阵化完成,可以痛快地写代码了!
3. matlab代码实现
这里只给出实现过程中遇到问题的代码片段,完整代码见https://github.com/codgeek/deeplearning,编写过前一节稀疏自编码 的小伙伴应该对整体结构比较熟悉了,softmaxCost.m实现给定参数权重时的代价值与梯度的矩阵计算,softmaxExercise.m结合梯度下降调用代价、梯度计算,完整实现上述四个步骤。
对1函数的计算有一些语法技巧,示例代码给出的full/sparse有些抽象,我用最基本的的==返回矩阵逻辑结果这个特性来计算,
首先把校验标签复制k份获得\(k\times m\)的矩阵:labels = repmat(labels, numClasses, 1);
然后制造出每一行等于行号的矩阵:k = repmat((1:numClasses)',1,numCases);
所以1函数对应的矩阵$ G_{k \times m}$为groundTruth = double((k == labels));
上一节已经给出了完整的矩阵化公式,也是理论转换为代码实现的难点所在,softmaxCost.m详细代码如下,
function [cost, grad] = softmaxCost(theta, numClasses, inputSize, lambda, data, labels, ~)
% numClasses - the number of classes
% inputSize - the size N of the input vector
% lambda - weight decay parameter
% data - the N x M input matrix, where each column data(:, i) corresponds to
% a single test set
% labels - an M x 1 matrix containing the labels corresponding for the input data
%
% Unroll the parameters from theta
theta = reshape(theta, numClasses, inputSize);
numCases = size(data, 2);
% groundTruth = full(sparse(labels, 1:numCases, 1));
%
labels = repmat(labels, numClasses, 1);
k = repmat((1:numClasses)',1,numCases);% numClasses×numCases.
groundTruth = double((k == labels));% % groundTruth algrithum is the same as (k===label)
thetagrad = zeros(numClasses, inputSize);
%% ---------- YOUR CODE HERE --------------------------------------
% Instructions: Compute the cost and gradient for softmax regression.
% You need to compute thetagrad and cost.
% The groundTruth matrix might come in handy.
cost = 0;
z = theta*data;
z = z - max(max(z)); % avoid overflow while keep p unchanged.
z = exp(z); % matrix product: numClasses×numCases
p = z./repmat(sum(z,1),numClasses,1); % normalize the probbility aganist numClasses. numClasses×numCases
cost = -mean(sum(groundTruth.*log(p), 1)) + sum(sum(theta.*theta)).*(lambda/2);
thetagrad = -(groundTruth - p)*(data')./numCases + theta.*lambda; % numClasses×inputSize
% Unroll the gradient matrices into a vector for minFunc
grad = thetagrad(:);
end
另外一部分需要稍动脑筋的是预测判断。怎样写的简捷高效呢?请看下文.
function [pred] = softmaxPredict(softmaxModel, data)
theta = softmaxModel.optTheta; % this provides a numClasses x inputSize matrix
pred = zeros(1, size(data, 2));
inputSize = softmaxModel.inputSize;
numClasses= softmaxModel.numClasses;
%% ---------- YOUR CODE HERE --------------------------------------
z=exp(theta*data);
[~, pred] = max(z);
end
关键在于使用matlab的max函数第二个返回值,它就是每列最大值的行号。
4. 图示与结果
数据集来自Yann Lecun的笔迹数据库,我们先瞜一眼原始MMIST数据集的笔迹。

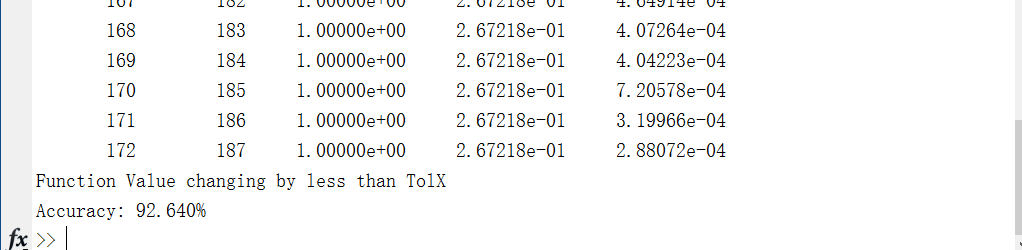
设定与练习说明相同的参数,运行完整代码https://github.com/codgeek/deeplearning 可以看到预测准确率达到92.6%。达到了练习的标准结果。
小结一下,看到梯度、矩阵化推导过程不难发现,一般都是先从对矩阵单个元素的偏导开始,给出表达式,然后把每个元素列举成行成列,根据行、列计算的关系,往矩阵乘法的“乘加”模式上套用,最终给出非常精简的矩阵化公式,矩阵只是一个规范化工具,难以直接在矩阵的抽象层次上推导,也很容易把一些在矩阵上不成立的直觉公式用上去而出错,所以现阶段还是一个从抽象到具体再到抽象的过程。

