

博客2
这次人工智能项目的实践,我们潜心投入,全力以赴,这个过程中我们遇到了很多意想不到的困难,首先训练模型过程中实现多种物品关键字的区别识别,然后我们小组进行了各种商量,以实现特定语言的区别关键字的识别,最后决定只实现一部分该动作语言的识别,而不是穷举全部该语言的识别,例如 关闭厨房灯我们采用的示例输入模型是:关掉厨房灯、厨房灯关掉,别开厨房灯、厨房灯可以关了。还,打开厨房空调我们的匹配语句是,打开厨房空调,厨房空调打开,厨房空调不要关,厨房空调别关等。。。
之后我们就进入了开始阶段,首先由于利用图形操作界面进行GUI编程,因此组件的添加很简单顺利就完成及实现了,然后是各种监听机制,由于有微软老师给的示例代码,因此大部分实现也都很顺利的完成和实现了,至此就完成了扩展模型和扩展可视化界中可以操作的设备的任务了。
然后我先展示一下界面,这是运行之后的界面
下一步我们要实现多轮对话功能,我们理解的多轮对话是指系统可以自动识别用户本次输入的指令中的entity,并根据情况进行补全或输出。例如用户第一条指令是打开厕所灯,第二条指令是空调也一并打开,那么系统就会自动识别出第二条指令打开的空调应该是厕所内的,而不是厨房里的空调。我们定义的entity有两种type,分别是location和device。如果用户指令中两种type都出现了,那么就直接根据这两种type,通过训练过的模型取得相应的intent即可。如果两种type都没有,很显然这句话是没有意义的,因为从上文中不可能推断出这句指令是要干什么,所以输出illegal!告知用户这是非法输入。下面是识别上下文的核心了,如果用户输入的指令中只有一种type,系统则会自动在上文查找这句中缺少的type并对本句指令进行填补。具体实现方法是通过建立字典全局变量,每次输入指令都自动更新其中存储的两种type对应的entity,如果系统发现指令缺少某种type,则在字典全局变量中找到该type对应的entity进行填补,并对填补完的指令进行二次模型识别,得到的指令就是用户的本意了。
最后我在这里展示点代码截图,和多轮对话识别结果截图(因为是整个项目完成之后后来补的,所以语音输出也做好了,识别之后有语音输出)
然后实现结果的展示是这个样子的,那个得分下面的是语音输出,由于实现的是先在面板上展示wav流,然后再语音输出,于是会有一段乱码在面板上展示:

NOW,我们来到了第三环节,做文本到输出的转换,这个环节的工作是比较有难度的,不过我也惊讶的发现,我的解决问题能力果然还是有待欠缺。
首先我通过微软语音识别服务网址,在页面内找了它的文档链接,但是说实话这个文档写的真的不怎么好,没有示例代码没有输入输出。很多类型也都是微软自己创造的,而且微软出于自我安全考虑,这些东西都是不展示的。然后最后研读了2,3个小时这个文档,我们小组读了好几遍读通了读精了才发现,真片文档只写了理论,理论写的还是可以的,总体上内容清晰,功能和需求明确,但是这些挺清晰的理论后面偏偏缺少了我认为最重要的东西--------示例代码展示,可能是怕占用太多空间影响了版面了吧。即,这个文档除了把如何获得密钥的代码展示了出来其他的都没有,缺少了3个最核心的代码,1>header是怎么设置的,2>与文本转换语言网址是怎么链接然后获得返回的语音的,3>语音是怎么个性化输出的。最后我能做的真的很迷茫,就简单写了点代码,就写了几行,试试能不能获得音频流,然后输出到面板上。
但做到最后老师又给我发了个示例代码的链接,哇真是柳暗花明又一村啊太不容易了,然后得到了代码之后,理论终于可以结合实际,中国终于可以走中国特色社会主义道路了,呵,这一路披荆斩棘,真的是太辛苦了啊。
然后主要的过程就是,首先,利用官方文档里提供的方法获得微软的授权许可,然后创建WebRequest(又是微软自己的类)的一个实例,填充这个类实例里面的各种参数,总共有5个,而且最后一个是获得授权得到的Token参数,这些是发送POST请求的标头参数,然后可以发送POST请求,然后发送即可,之后返回一个音频文件,这个音频文件的输出可就有讲究了,各种,地区,语言,频率,还可以由xml设置音调高低,语句停顿,语音延迟等。嗯,that all!
部分代码展示,由于用了老师提供的官方的示例代码,于是借鉴了大量代码,代码行数达到了700多行,所以这里我就不展示全部的代码了,这里只展示部分:
这块是对官方示例代码中的代码进行分析和理解然后再进行些适量修改,然后添加到自己的代码中,以实现文本到语音的转换
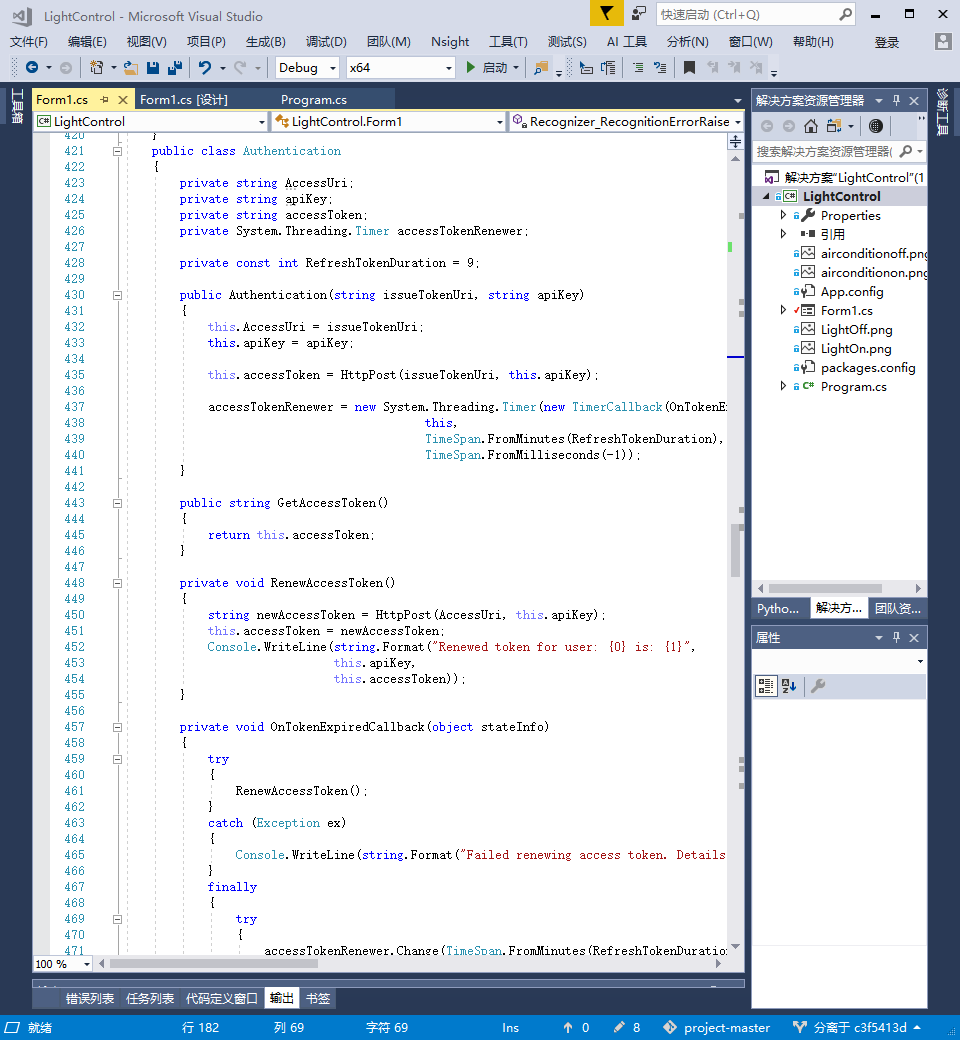
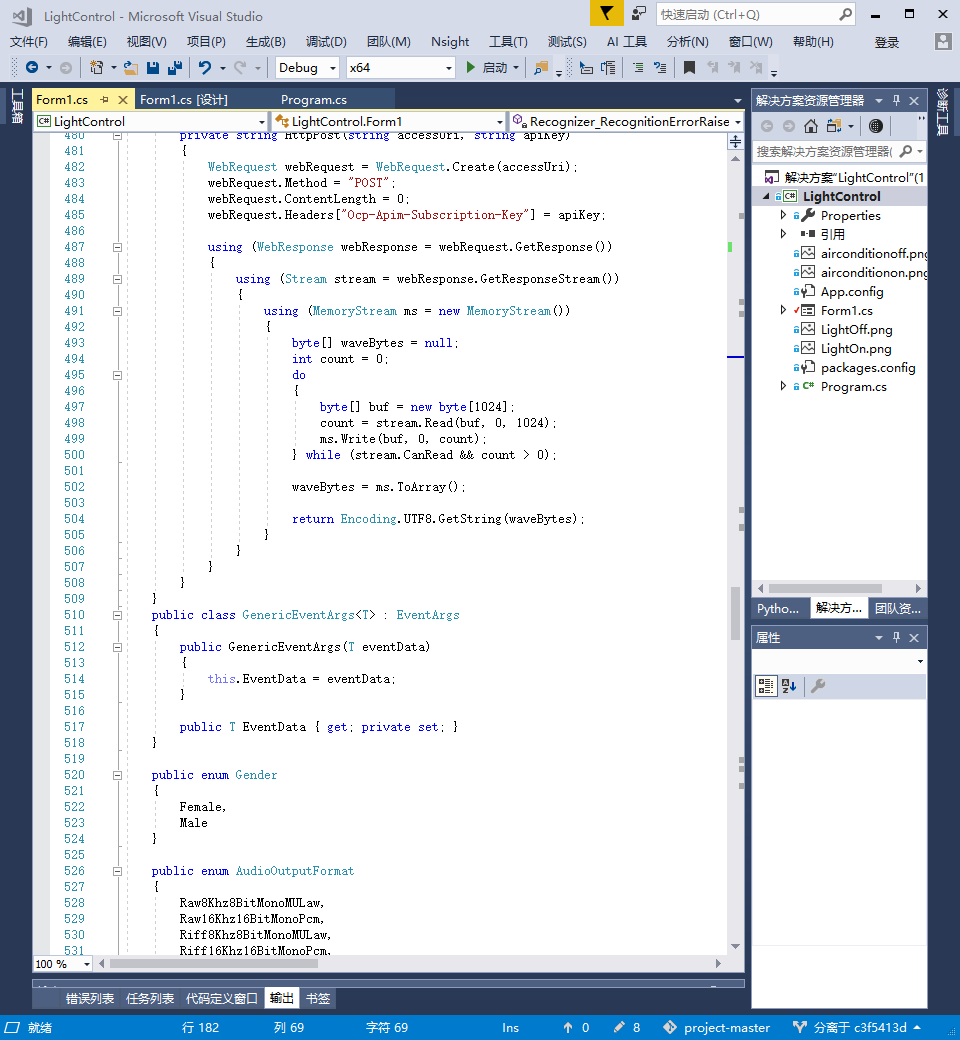
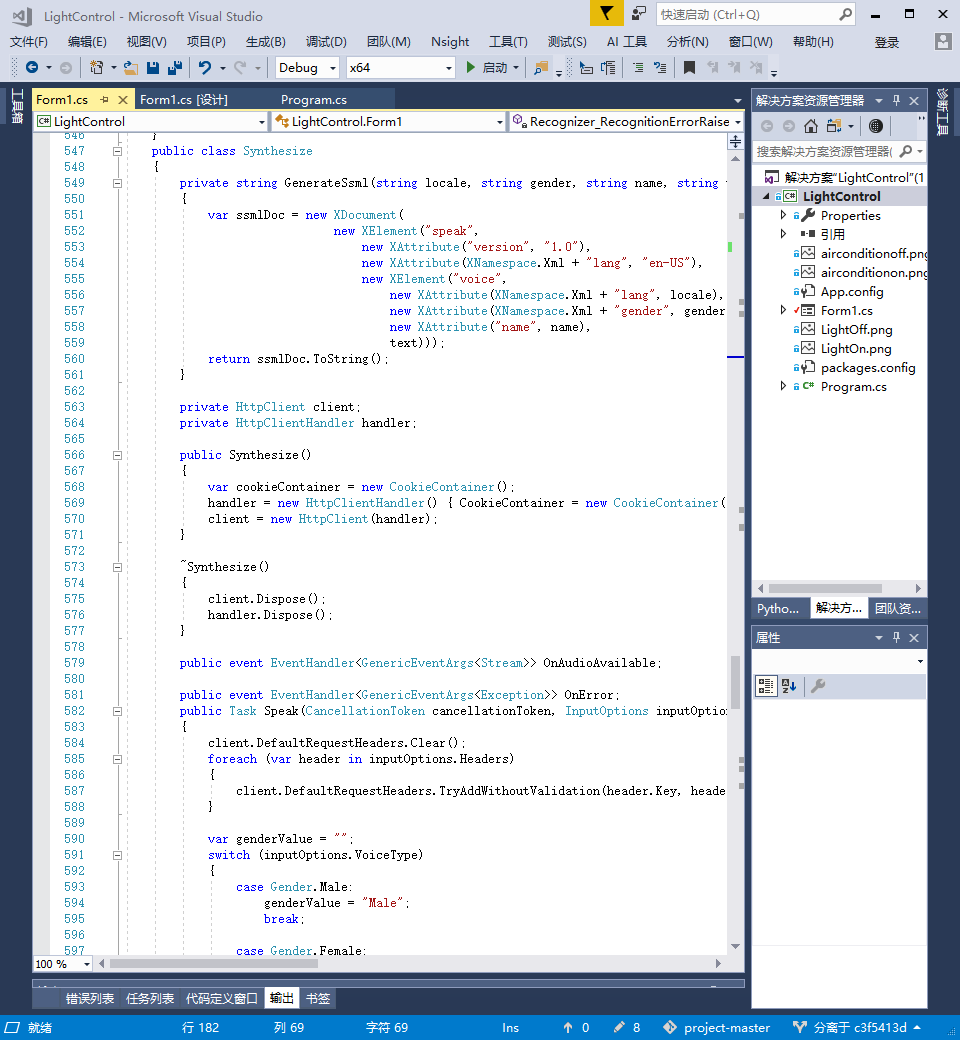

这里是调用代码的对语句进行输出的核心代码部分,是一个封装,我封装到了output里,只要调用这里的代码进行输出就可以了

然后最后我们来见证一下自己的本事,实验成果展示:
https://www.bilibili.com/video/av27182229

过程中的困难其实我已经基本都描述在进程里了,主要就是1.识别多轮对话 2.语音的输出 唯一没有写和提到的就是 3.github的团队使用和合并, emmmGitHub毕竟之前没有团队工作或开发使用Github过的经历,于是整个使用过程确实是处处碰壁,一步步摸索,不过好在我们学习能力还可以,我们很快就学会了。
我们对AI工具的反馈是,由于我们这个项目只用到了微软认知服务,于是我也就在这里只写一下对微软认知服务的反馈吧,总体来说工具很强大,不论是语音到文本的翻译还是文本到语音转换的输出,都做到的实现语言极其广泛,流的上传下载速度相当给力,音频还可以实现用xml语言的自由调控,可控音,控频,控停顿,控语种,控声色。。。。各种各样的功能。但是在这么完美的实现,我在实验过程中,我认为还是有美中不足的地方存在的,首先,语音转文本的翻译过程,没有实现可由客户端自由控制一句话的结束时间,而是由默认长度的停顿时间判断为用户语音的输入结束;二,文本转换语音输出,这个AI工具是做的真的比较完美,我没找到什么不足之处,但我对那个使用文档有小小的建议,下回能不能把官方的示例代码的链接给到文档里啊,要不是老师给我,那一步我们差点凉了。。。
然后我们对我们做的这个AI产品,有如下认识,主要都是针对一些优点和不足;
首先我们做到了老师要求的全部功能,但是其次我们并没能实现快速识别以及快速输出,这是很大的遗憾但这也是人工智能普遍都具有的共同的缺点,但同时也使我们更加富有激情去开拓和探索。通过这门课的学习我们第一次这么近距离的感受了人工智能,微软的老师教了我们很多有关人工智能的基础知识并带我们亲手制作,使我们能轻松领悟并很快的入门,同时也让我们看到了人工智能那巨大的潜在的待挖掘的宝藏,感谢微软亚洲研究院的老师们的带给我们的一切,今后我定将在人工智能方面做出我的研究和突破!
本次实验中我们总共借鉴了就一处的代码 ( 其他全为手写)。即老师最后提供给所有微软课同学的,一个官方给的示例:
https://github.com/Azure-Samples/Cognitive-Speech-TTS/tree/master/Samples-Http/CSharp
最后整个实验结束之后,我们的小组的小组成员在整个实验过程中的任务分配的得分情况是
周豪25,王钦申24,石金泽18,关柳萍17,姚云志16。

