
我的tesseract学习记录
前言:花了约三周看文档(打酱油),又花了两周搭环境,终于把tesseract用起来了,对简体中文的识别率还不错,在95%以上。现在简要记录一下安装、识别过程。
一、系统环境
系统:windows7
编译环境:VS2010
依赖软件:leptonica、opencv2.4.10、tesseract3.02
linux下的tesseract在这里
二、安装过程
(1) leptonica
1、leptonica是tesseract的依赖库,安装过程主要参考官网教程;
vs2010的编译过程参考这里;
建议直接使用leptonica提供的vs2008的工程,转换成vs2010以后,需要修改的地方如下:
Fix the liblept168 project by doing the following:
-
Right-click on liblept168 and choose Properties.
-
Then change liblept168 Property Pages | General | Target Name to one of the following values:
For the LIB Debug Configuration:
$(ProjectName)-static-mtdll-debug
For the LIB Release Configuration:
$(ProjectName)-static-mtdll
For the DLL Debug Configuration:
$(ProjectName)d
-
编译即可得到:
LIB_RELEASE和LIB_DEBUG:
liblept168-static-mtdll.lib 和 liblept168-static-mtdll-debug.lib
DLL_RELEASE和DLL_DEBUG:
liblept168.lib、liblept168.dll和 liblept168d.lib、liblept168d.dll
在调用生成的动态库liblept168d.dll,报错,找不到从属程序集 Microsoft.VC90.DebugCRT
解决方法,参考这里
2、如果想自己编译所有依赖库,超级麻烦,可以参考下面的步骤:
一共需要安装5个依赖包,分别是:zlib、libpng、libjpeg、libtiff、giflib
上述5个依赖库安装过程可参考这里;
整个leptonica安装过程也可参考这里;
注意:以下五个库的生成,应确保运行库都选择/MD或/MDd
不使用全程序优化/GL编译
1.zlib
zlib的编译过程参考这里;
首先cd to the BuildFolder\zlib\contrib\masmx86 directory. Then execute:bld_ml32.bat
然后打开\BuildFolder\zlib\contrib\vstudio\vc10\zlibvc.sln
修改运行时库为/MD或/MDd
移除 ZLIB_WINAPI from Configuration Properties | C/C++ | Preprocessor | Preprocessor Definitions.
If you don’t do this you’ll get undefined symbol error messages when trying to build libpng and libtiff.
最后,Copy zlib\zlib.h and zconf.h to BuildFolder\include.
2.libpng
libpng的编译过程参考这里;
(1)Open BuildFolder\lpng143\projects\visualc71\libpng
(2)change the LIB Debug Configuration Properties | C/C++ | General | Debug Information Format
from Program Database for Edit & Continue (/ZI) to C7 Compatible (/Z7).
(3)change run time library from /MT to /MD or from /MTd to /MDd
(4)Build the libpng by right-clicking it and choosing Build
3.libjpeg
libjpeg的编译过程参考这里;
如果编译的过程中,nmake有问题,参考这里;
打开D:\libjpeg\jpeg-9a\install.txt 里面有vs2010编译的说明。
编译jpeg时,官网上的只有release版本的lib,需要debug版本的lib的话,编译选项需要自己配置
配置方法,就是拷贝release版本预处理器定义,并进行修改,将NDEBUG改为_DEBUG
将运行库改为:/MDd
基本运行时检查改为:两者
将全程序优化(GL)选项关闭。
4.libtiff
libtiff源码的下载地址;
编译过程参考这里
libtiff depends on libjpeg and zlib.
由于libtiff依赖了libjpeg和zlib,因此需要修改nmake.opt和tiffconf.vc.h文件。
nmake.opt修改如下:
# Uncomment and edit following lines to enable JPEG support.
#
JPEG_SUPPORT = 1
JPEGDIR = D:/zhuyan/leptlib/libtiff/jpeg
JPEG_INCLUDE = -I$(JPEGDIR)
JPEG_LIB = $(JPEGDIR)/libjpeg9a-static-mtdll.lib
# Uncomment and edit following lines to enable ZIP support
# (required for Deflate compression and Pixar log-format)
#
ZIP_SUPPORT = 1
ZLIBDIR = D:/zhuyan/leptlib/libtiff/zlib
ZLIB_INCLUDE = -I$(ZLIBDIR)
ZLIB_LIB = $(ZLIBDIR)/zlib125-static-mtdll.lib
tiffconf.vc.h(使用IDE,则直接在tiffconf.h中修改)修改如下:
增加两条语句:
#define JPEG_SUPPORT 1
#define ZIP_SUPPORT 1
使用nmake编译
输入nmake /f makefile.vc clean
输入nmake /f makefile.vc
使用IDE编译:
从nmake编译换成IDE编译,需要获取编译时宏定义参考这里;
即在命令行中输入nmake /f makefile.vc clean all > vc.txt
用于查看编译用到了哪些文件,定义了哪些宏。
需要的源文件,tiff_* 共38个,port中3个源文件,snprintf.c,strcasecmp.c,getopt.c
5.giflib
giflib的官网地址;
download giflib for windows : here
按以下要求修改预处理器定义
WIN32
WINDOWS32
NDEBUG
_LIB
_OPEN_BINARY
HAVE_IO_H
HAVE_FCNTL_H
HAVE_STDARG_H
HAVE_BASETSD_H
HAVE_STDINT_H
HAVE_SYS_TYPES_H
_MBCS
3、 依赖库编译好了以后,直接使用leptonica的vs2008工程,将其转换为vs2010工程,
由于使用的依赖库版本与工程中的设定不同,因此需要修改属性管理器中定义的用户宏。
leptonica的vs2008工程中使用的宏:

修改为自己使用的版本。
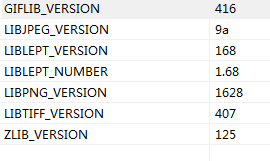
修改方法参考这里;
(2) tesseract3.02
1.找到编译tesseract3.02的说明,由于这里没有vpn,可以直接参考下载的源码里自带的说明:
D:\tesseract-3.02.02\vs2008\doc\setup.html
也可以辅助参考一下官网说明;
不想看英文的可以参考这里;
官网中说,可以直接下载leptonica的leptonica-1.68-win32-lib-include-dirs.zip,包含了leptonica的所有头文件和静态库,这个是vs2008编译的。
如果在vs2010工程中不能使用,只需使用vs2010重新编译leptonica的静态库和动态库。
2.下载leptonica头文件和库文件;
下载tesseract源码
3.对D:\tesseract-3.02.02\vs2008\中的vs2008工程进行转换为vs2010,提出以下警告
| MSB8012: $(TargetName) ('libtesseract302') does not match the Librarian's OutputFile property value '..\LIB_Debug\libtesseract302-static-debug.lib' ('libtesseract302-static-debug') in project configuration 'LIB_Debug|Win32'. This may cause your project to build incorrectly. To correct this, please make sure that $(TargetName) property value matches the value specified in %(Lib.OutputFile). |
| MSB8012: $(TargetPath) ('D:\zhuyan\leptlib\tesseract-build\tesseract-3.02.02\vs2010\libtesseract\..\LIB_Debug\libtesseract302.lib') does not match the Librarian's OutputFile property value '..\LIB_Debug\libtesseract302-static-debug.lib' ('D:\zhuyan\leptlib\tesseract-build\tesseract-3.02.02\LIB_Debug\libtesseract302-static-debug.lib') in project configuration 'LIB_Debug|Win32'. This may cause your project to build incorrectly. To correct this, please make sure that $(TargetPath) property value matches the value specified in %(Lib.OutputFile). |
| MSB8012: $(TargetName) ('libtesseract302') does not match the Librarian's OutputFile property value '..\LIB_Release\libtesseract302-static.lib' ('libtesseract302-static') in project configuration 'LIB_Release|Win32'. This may cause your project to build incorrectly. To correct this, please make sure that $(TargetName) property value matches the value specified in %(Lib.OutputFile). |
| MSB8012: $(TargetPath) ('D:\zhuyan\leptlib\tesseract-build\tesseract-3.02.02\vs2010\libtesseract\..\LIB_Release\libtesseract302.lib') does not match the Librarian's OutputFile property value '..\LIB_Release\libtesseract302-static.lib' ('D:\zhuyan\leptlib\tesseract-build\tesseract-3.02.02\LIB_Release\libtesseract302-static.lib') in project configuration 'LIB_Release|Win32'. This may cause your project to build incorrectly. To correct this, please make sure that $(TargetPath) property value matches the value specified in %(Lib.OutputFile). |
| MSB8012: $(TargetPath) ('D:\zhuyan\leptlib\tesseract-build\tesseract-3.02.02\vs2010\libtesseract\..\DLL_Release\libtesseract302.dll') does not match the Linker's OutputFile property value '..\DLL_Release\libtesseract302.dll' ('D:\zhuyan\leptlib\tesseract-build\tesseract-3.02.02\DLL_Release\libtesseract302.dll') in project configuration 'DLL_Release|Win32'. This may cause your project to build incorrectly. To correct this, please make sure that $(TargetPath) property value matches the value specified in %(Link.OutputFile). |
| MSB8012: $(TargetName) ('libtesseract302') does not match the Linker's OutputFile property value '..\DLL_Debug\libtesseract302d.dll' ('libtesseract302d') in project configuration 'DLL_Debug|Win32'. This may cause your project to build incorrectly. To correct this, please make sure that $(TargetName) property value matches the value specified in %(Link.OutputFile). |
| MSB8012: $(TargetPath) ('D:\zhuyan\leptlib\tesseract-build\tesseract-3.02.02\vs2010\libtesseract\..\DLL_Debug\libtesseract302.dll') does not match the Linker's OutputFile property value '..\DLL_Debug\libtesseract302d.dll' ('D:\zhuyan\leptlib\tesseract-build\tesseract-3.02.02\DLL_Debug\libtesseract302d.dll') in project configuration 'DLL_Debug|Win32'. This may cause your project to build incorrectly. To correct this, please make sure that $(TargetPath) property value matches the value specified in %(Link.OutputFile). |
修改方法参考这里;
错误描述为:
warning MSB8012: TargetPath(D:\zhuyan\leptlib\tesseract-build\tesseract-3.02.02\vs2010\libtesseract\..\LIB_Debug\libtesseract302-static-mtdll-debug.lib)
与 Library 的 OutputFile 属性值(D:\zhuyan\leptlib\tesseract-build\tesseract-3.02.02\vs2010\LIB_Debug\libtesseract302-static-debug.lib)不匹配。
即:
LIB_RELEASE:
将属性->配置属性->常规中目标文件名改为$(ProjectName)-static
LIB_Debug:
将属性->配置属性->常规中目标文件名改为$(ProjectName)-static-debug
DLL_Debug:
将属性->配置属性->常规中目标文件名改为$(ProjectName)d
编译时,弹出如下错误:
..\..\ccmain\equationdetect.cpp : warning C4819: 该文件包含不能在当前代码页(936)中表示的字符。请将该文件保存为 Unicode 格式以防止数据丢失
这是因为该cpp文件的编码格式有问题,只需要在双击该文件,在右侧导航栏上点击该文件,在文件->高级保存选项中,在窗口中选择“简体中文(gb2312)-代码页936”,保存后重新编译。
4.编译过程主要参考有:
http://www.jianshu.com/p/5446776095b8
http://blog.csdn.net/u012566751/article/details/54141109
http://blog.csdn.net/rrrfff/article/details/8552946
linux : http://blog.csdn.net/zhangping1987/article/details/51151050
采用LIB_RELEASE和LIB_DEBUG模式,分别生成的文件是:libtesseract302-static.lib 和 libtesseract302-static-debug.lib
采用DLL_RELEASE和DLL_DEBUG模式,分别生成的文件是:libtesseract302.dll、libtesseract302.lib 和 libtesseract302d.dll、libtesseract302d.lib
5.api的使用,主要参考有:
http://blog.csdn.net/u012566751/article/details/54136836
http://www.tuicool.com/articles/aMZfMv
https://wenku.baidu.com/view/46858352b7360b4c2e3f64b8.html
主要参考:http://www.jianshu.com/p/a53c732d8da3
工程配置如下:
1、将tesseract中所有的.h文件搜索出来,放到文件夹include/tesseract,将静态库放到文件夹lib
2、将leptonica中的所有.h文件,放到一个文件夹include/leptonica,将静态库放到文件夹lib
3、属性->C/C++->附加包含目录,包含上述头文件的文件夹
4、链接器->常规->附加库目录,包含上述静态库文件夹
5、链接器->输入->附加依赖项,输入leptonica和tesseract的静态库
6、如果使用的是动态库,则将动态库文件放到一个文件夹bin中,并修改计算机的环境变量,同时包含动态库的导入库lib
7、注意,新建文件夹tessdata,存放训练过的语言文件,放的位置在xx/Tesseract-OCR/tessdata/
8、需要将xx/Tesseract-OCR/添加到新建环境变量TESSDATA_PREFIX中,再将xx/Tesseract-OCR/添加到Path环境变量中。
动态库的使用,网上例子很多(参考上面三个链接)。
现在说下静态库的使用,必须包含所有上述的静态库,否则报错。
参考D:\tesseract-3.02.02\vs2008\doc\programming.html
LIB_Release Linker Additional Dependencies:
ws2_32.lib
user32.lib
zlib$(ZLIB_VERSION)-static-mtdll.lib
libpng$(LIBPNG_VERSION)-static-mtdll.lib
libjpeg$(LIBJPEG_VERSION)-static-mtdll.lib
giflib$(GIFLIB_VERSION)-static-mtdll.lib
libtiff$(LIBTIFF_VERSION)-static-mtdll.lib
liblept$(LIBLEPT_VERSION)-static-mtdll.lib
libtesseract$(LIBTESS_VERSION)-static.lib
6.opencv的使用
opencv的静态库在工程中的debug和release模式中需要分别添加
release:
opencv_calib3d2410.lib
opencv_contrib2410.lib
opencv_core2410.lib
opencv_features2d2410.lib
opencv_flann2410.lib
opencv_gpu2410.lib
opencv_highgui2410.lib
opencv_imgproc2410.lib
opencv_legacy2410.lib
opencv_ml2410.lib
opencv_nonfree2410.lib
opencv_objdetect2410.lib
opencv_ocl2410.lib
opencv_photo2410.lib
opencv_stitching2410.lib
opencv_superres2410.lib
opencv_ts2410.lib
opencv_video2410.lib
opencv_videostab2410.lib
debug模式就是在这些库的末尾加上d,比如opencv_videostab2410d.lib
三、识别过程
(1)图像预处理
图像预处理主要参考官网提出的对图像的处理,由于我主要用来识别扫描的文件,所以只做了简单的去噪,使用的是腐蚀和膨胀。由于只会opencv,所以用的opencv做图像预处理。
如果扫描件的图片周围有黑框,可以参考Border removal中的算法去除。
下面是做的一些图像处理时,参考的链接。
1、 Border removal :
a) http://answers.opencv.org/question/30082/detect-and-remove-borders-from-framed-photographs/
2、 Binarization:
a) threshold in opencv with parameter of OTSU
b) other approach, ref: http://liris.cnrs.fr/christian.wolf/papers/icpr2002v.pdf
3、 remove noise introduced by digitization:
a) median filter for salt/pepper noise
b) morphological operations : http://stackoverflow.com/questions/8654858/noise-removal-in-opencv
c) mean filter for Gaussian noise
4、 chunk segmentation :no images, horizontal or vertical separators
5、 detect skew angle of text
a) http://felix.abecassis.me/2011/10/opencv-rotation-deskewing/
(2)页面布局分析
1、字体大小和分辨率
在测试时发现,将一个文档的图片直接扔到tesseract中,识别效果不太理想,但是,将图片中字体和大小不同的文字截图成多个图片块,再扔给tesseract,识别率惊人的高。
仔细看了一下官方网站,对待识别的图片中文字的要求是:
Is there a Minimum Text Size? (It won't read screen text!)
There is a minimum text size for reasonable accuracy. You have to consider resolution as well as point size. Accuracy drops off below 10pt x 300dpi,
rapidly below 8pt x 300dpi. A quick check is to count the pixels of the x-height of your characters. (X-height is the height of the lower case x.)
At 10pt x 300dpi x-heights are typically about 20 pixels,although this can vary dramatically from font to font. Below an x-height of 10 pixels,
you have very little chance of accurate results, and below about 8 pixels, most of the text will be"noise removed".
总的来说:最小5号字,扫描仪dpi不小于300,单个字符的高度不小于20个像素。
由于使用的扫描仪,最后得到的是一个pdf格式的文档,得转成图片,转图片时,选择300dpi,使用的小工具转换的。
2、页面分块
既然将图片分块,可以提高识别率,那么就来分块吧。可是不知道用什么分块算法,不过幸好tesseract自带有页面布局分析模块,很强大,很好用(崇拜一下)。
过程如下:
1.初始化tesseract和设置参数
api.Init()
api.SetPageSegMode() //这里要使用 tesseract::PSM_AUTO 自动页面布局分析模式
api.SetImage((uchar*)src.data, src.cols, src.rows, src.channels(), src.cols * src.channels()); //我用的opencv的数据结构输入的
2.获取图片分块
Boxa *boxes = api.GetRegions(NULL);//获取粗分块
BOX* box = boxaGetBox(boxes, i, L_CLONE);//获取分块方框的坐标,一共有boxes->n个方框
3.获取文字行分块
Boxa *lineboxes = api.GetTextlines(NULL,NULL);//获取每个粗分块中的文字行分块,这里会自动舍弃含有图片的分块。
将分块后的图片,截取出来,直接扔到OCR里,结果啥也没识别出来,问题在哪里??
原来是截取得文字行的高和宽将图片占满了,OCR没法识别,怎么办?我想的方法是在周围加空白。
试了一些参数,在文字行四周增加空白的高宽比例为文字行高度的0.6倍,即垂直和水平方向上增加的空白的高度相加,为文字行高度的1.2倍。
再扔到OCR里,效果还是不好啊(哭),觉得是不是文字的比例还是不合适,那么就进行缩放吧,将图片缩小了一倍,即缩放系数0.5,然后,surprise,识别率大增,非常满意。
当然这里的两个参数,可以根据实际情况,来调整。
int boxEdge = (int)r.height*1.2;//增加的空白比例
Mat dst(box_img.rows+boxEdge,box_img.cols+boxEdge,box_img.type(), Scalar(255,255,255));//空白图片
addWeighted(dst(Rect(boxEdge/2,boxEdge/2,r.width,r.height)),0,box_img,1,0.0,dst(Rect(boxEdge/2,boxEdge/2,r.width,r.height)));//文字与空白图片融合
Mat resize_dst;
double scale = 0.5;//缩放系数
cv::resize(dst, resize_dst, cv::Size(dst.cols * scale, dst.rows * scale), (0,0), (0,0), cv::INTER_LINEAR);//缩放图片
如果对tesseract页面布局分析的过程感兴趣的可参考:http://blog.csdn.net/kaelsass/article/details/46874627
3、去除盖章
由于我主要用来识别一些红头文件,所以,里面有些地方有盖的红章,tesseract在页面布局分析时,直接将含有叠加图片的整!行!文字都舍弃了(或者识别出来是乱码)。
于是,我得想办法把红章去掉,然后识别红章下的文字。去掉的方法呢,首先想到的是颜色,检测红色,再去掉。然后发现红头文件啊,红色字也好多啊。
灵机一动,可以将上一步页面布局分析中,将红章和文字划分为一块的那个分块图像单独拿出来,怎么找到呢,默认都是圆章,那么使用霍夫变换吧,检测圆。
1.检测圆
cvtColor(box_img, gray_img, CV_BGR2GRAY);
cv::GaussianBlur(gray_img,gray_img,cv::Size(7,7),1.5);
std::vector<cv::Vec3f> circles;
cv::HoughCircles(gray_img, circles, CV_HOUGH_GRADIENT,
2, // 累加器的分辨率(图像尺寸/2)
box_img.rows/2, // 两个圆之间的最小距离
200, // Canny中的高阈值
300, // 最小投票数
50, box_img.rows/2); // 有效半径的最小和最大值
2.去除红色的像素点
MatIterator_<Vec3b> it_in=box_img.begin<Vec3b>();
if((*it_in)[2]>80)
{
(*it_in)[0]=255;//b
(*it_in)[1]=255;//g
(*it_in)[2]=255;//r
}
成功地去掉了红章以后,对文字造成了一些破坏,使用了膨胀+腐蚀来增强图像,最后识别率很高。
前期的图像预处理很重要,最好丢进去的文字,没有噪声,没有倾斜,清晰,无底纹或者图片。
(2)识别过程
网上的例子很多,识别的过程,几乎做不了太多事情,除非去源码里进行改进,由于时间有限,加上tesseract的识别率还不错,所以,只需要对参数进行设置就可以了。
这些参数,是用于识别日文时设置的,但官网上说,对中文也适用,主要是以下参数进行了设置:
//SetVariable
bool out;
out = api.SetVariable("chop_enable","T");
out = api.SetVariable("use_new_state_cost","F");
out = api.SetVariable("segment_segcost_rating","F");
out = api.SetVariable("enable_new_segsearch","0");
out = api.SetVariable("language_model_ngram_on","0");
out = api.SetVariable("textord_force_make_prop_words","F");
out = api.SetVariable("edges_max_children_per_outline","40");
设置这些参数后,确实对识别率有了一些提升。
这些参数的说明,参考官网说明。


