
结对作业2
结对成员
031502113 胡俊钦
031502308 付逸豪
github链接
数据生成原理
在数据生成的时候,按照规定的要求,一步步的进行生成
部门的生成部分:
部门编号:由于确定了部门数量上限是20,那么我们就用一个字符串数组存所有的部门编号,从D001到D020
部门学生上限:规定是单个,数值,在[10,15]内,于是就rand一个整数搞定
标签:由于现实中标签不可能很多,于是我们手工写了20个左右的单词,用一个数组全部存下来,同时我们限定一个部门的标签是有一个上限的,根据一个部门至少有2个标签的限制,我们生成一个2~4之间的随机数,表示这个部门有这么多个标签,然后根据这个数量rand这么多次,确定所有的标签。由于最后的数据大概率出现重复的情况,我们加入了判重处理。
常规活动时间:由于在时间上随机可能看过去不太直观,并且类似于12:34、03:12之类的时间不太具有实际意义,于是我们限定了几个特殊的时间,在一天之内我们只有可能选择那几个时间点,存在数组中,然后对数组进行rand,确定时间。同样的,需要判重。有一点细节就是一个部门一周不可能活动十几二十次,于是需要限定活动次数,大约是3,4次这样比较合理。
学生的生成部分
学生编号:由于有300个学生,加上学生学号可能不是连续的,因为不是所有的学生都会选择参加部门,于是就固定了前面几位,保证是031502开头,剩下部分随机生成
学生空闲时间:学生的空闲时间一般来说是比较多的,那么我们和部门常规时间的生成方式类似,只是把可以生成的数量增加,确保生成的数据尽量符合现实。
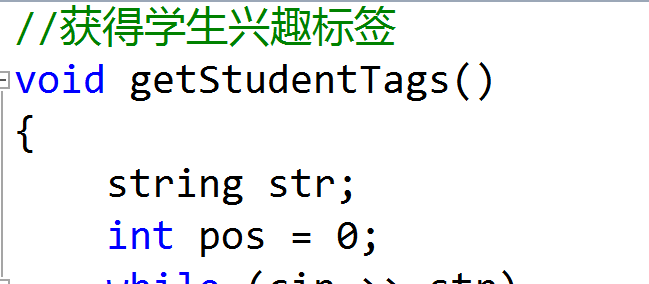
学生标签:由于学生标签一定是部门标签中的一个,而我们的部门标签是在一个预设的字符串数组中选择的,所以学生标签也在那个数组中rand
志愿:随机生成一个1~5的整数,表示一共有x个志愿,然后生成x个不同的1~部门数之间的数(需要判重),表示选择这个部门。
由于我们做了比较多的限制,其实每组数据出来都是比较稳定的,我认为每组数据实际上都“比较好”,就选了一组数据,这组数据还有一个“好处”,就是我们认为跑出来的结果也很好
github链接
数据建模及匹配程序过程
数据建模过程是手工模拟字符串读入(所以特别在意空格以及换行。。),按照给定的json格式的样本,模拟输入的过程,在这个过程中,主要考验耐心以及细心程度。事实上,大部分的时间也花在了这儿= =。具体的实现就是每次读入一个string,然后按照格式,去处理这个string。
整个匹配的过程是经过了5轮的匹配,每一轮匹配都从第一个部门开始,循环到第20个部门,在第i轮匹配的时候,考虑第j个部门,我们把前i个志愿报第j个部门的所有时间允许的同学都拿出来,排序,决定是否选他,以此类推。所谓的时间允许,是指能参加的活动次数占总活动次数一半以上。每次参加活动(允许迟到早退一定比例)。也就是说比如有一个同学晚上7点到9点有空,我报名了部门1和部门2,其中部门1活动时间是7点到8点,部门2活动时间是8点到9点,我的匹配代码是允许这个同学同时参加2个部门的。排序的要求是这样的:第一关键字是第几志愿,志愿优先,第二关键字是参与时间,参与时间越多越好,第三关键字是兴趣匹配程度,兴趣标签匹配越多越好,第四关键字是已经参加的部门个数,越少越好(假定参加更少的部门,就会有更多的经历参加本部门的活动),最后一个关键字是学号,按学号升序。
那么确定了思路之后,还有一些细节需要处理,最重要的就是时间的匹配如何。那么我有2个大致的想法,1是假如一个部门一周有1000分钟的活动时间,要求能够出席至少P%*1000分钟的时间,2是假如一个部门一周固定有5次活动,要求能过出席P%*5次活动(每次出席就得几乎匹配上),由于感觉第一种方案不够科学,经过讨论后选择了第二种方案,取p%为0.5,也就是至少出席半数的活动。
还有一个细节就是冲突时间的处理,也就是说,人的空闲时间是动态更新的,如果我参加了部门1,就势必会导致我某些时间变的没空,也就是一旦一个部门选择了一个人,那么这个人的空闲时间就要进行更新。
同时在时间的处理上转化成分钟,虽然这样时间复杂度会增加,但是写代码的难度下降了许多。同时可以支持处理12:34~12~40这样的情况。
到此,确定了完整的匹配过程。也就是说,匹配的过程是部门选人,而不是人选部门。具体的实现就是第一重循环是1~5,表示第几轮,第二重循环1~20表示20个部门,第三重循环是1~300,表示学生,对于每一轮的每一个部门,把所有符合要求的学生拿出来排序,确定匹配情况。
实现相关部门、学生分别用不同的struct来存
学生和部门之间的匹配关系,用20个vector来存,每一个部门对应一个vector
处理unlucky的学生和部门的时候为了偷懒,用了2个set,一旦有一个部门选择了一个同学,或者一个同学被一个部门选择了,就从set中erase,最后还在set中的学生和部门就是unlucky的
代码规范
在变量命名上我们采用了驼峰命名方式,第一个单词小写,后面的单词首字母大写
函数体之间换行花括号单独一行
if else for中就算只有一个语句,也用花括号括起来尽量用看得懂的英文命名变量
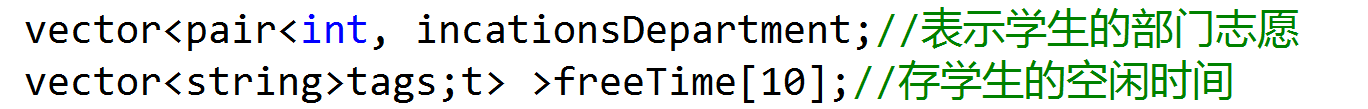
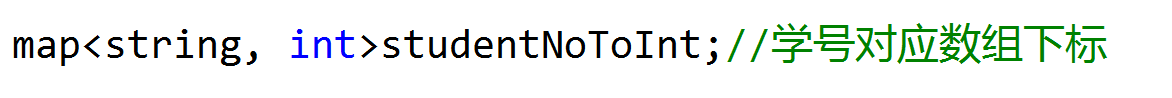

结果评估
这组结果基于我们生成的“最好”数据,如果采用助教提供的数据,unlucky学生在181个左右,没有不幸运的部门
我们这组数据是300个学生,20个部门,最终结果是199个同学加入了部门,部门的总容量是251个,实际上也收了251人次,也就是说所有的部门都收满了人,而只有101个同学没有加入部门,我们对这个结果是比较满意的,因为现实生活中大部分部门都可以收到较多的同学,而与此同时很多同学没有加入部门
结对感受
两人做事情效率是会大于一个人的,不仅仅是因为人数的增加提高了效率,还要对队友考虑负责,不能拉后腿,所以得加快加快进度。
同时,两个人可以讨论问题,这个很重要,因为一个人想问题不可能那么全面,往往可能存在一些细节上的漏洞,那如果一个人看不出来的话,2个人看出来的可能性会大于一个人。
最重要的就是分工,一人负责一个模块的话,只要保证自己的模块不出错,事实上会加快我们完成编程的时间。
这次作业刚好赶上了国庆,由于国庆acm这儿有训练,导致前几天白天在训练,晚上在休闲,一直拖延下去,知道deadline快到了才开始动手,还好还好,完成了作业。在交流上我们都是用qq交流的,还好交流的也比较顺畅。确定了分工之后,我们就开始分头行动。但是在匹配算法的很多细节上,还是要双方讨论之后拍板决定,也降低了思考的复杂度。
这次作业也是大学生活中第一次遇到的结对作业,我想这次作业就是想让我们体会到团队作业的好处,可以更加直观的告诉我们1+1>2,事实上我们也感受到了,团队在很多情况下都会大于个人的。团队的好处我想主要在于沟通,2个人的交流,会带来更多的想法,而不仅仅局限在编码上。
一拿到题目的时候还比较困惑,如何匹配才好呢?这时候就体现出团队的作用了,让我们早早的就确定了一个大方向,是部门选人,而不是人选部门,那么在这个基础上,再加上各种各样的细节,就完成了整个匹配的思路
闪光点的话:胡老师全身都是闪光点!胡老师强啊,非常高效率的搞定了数据的生成部分,提供了良好的数据以供测试,在讨论的过程中提供了很多的思路,匹配的一些细节上也提出了想法,还是很开心的!
建议:胡老师稍微注意一下一些小细节,比如生成数据时候判重之类的,然后就是超强的胡老师,我就不提建议啦。

