
pandas删除某一列的方法
方法一:直接del df['column-name']
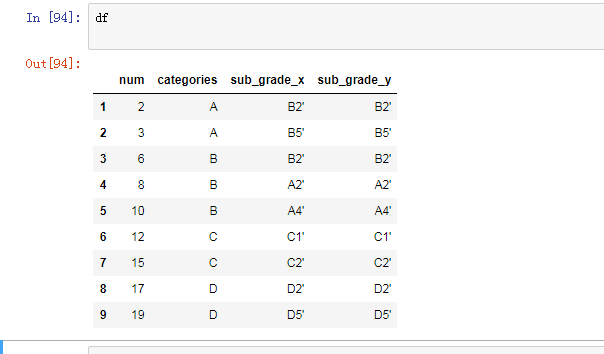
删除sub_grade_列, 输入del df['sub_grade_x']
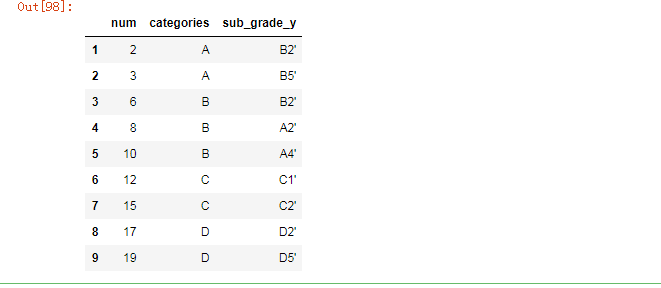
方法二:采用drop方法,有下面三种等价的表达式:
1. df= df.drop('column_name', 1)
输入:df,drop('num',axix=1),不改变内存,及输入df的时候,它还是显示原数据

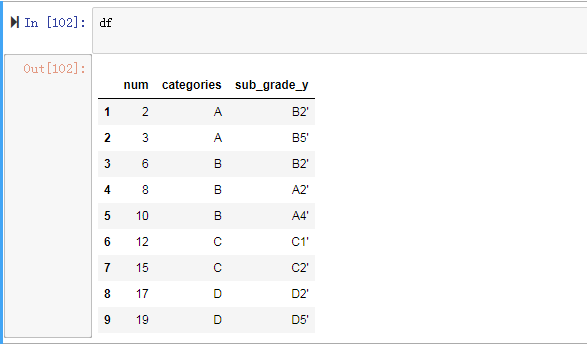
2. df.drop('column_name',axis=1, inplace=True)
输入:df.drop('num',axix=1,inplace=True),改变内存,及输入df的时候,它显示改变后的数据
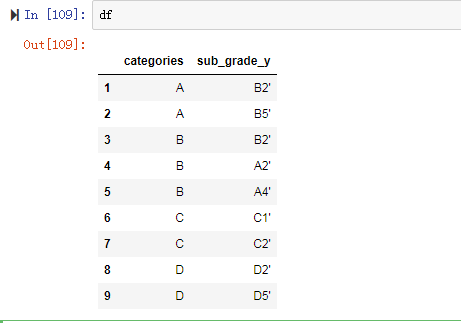
3. df.drop([df.columns[[0,1, 3]]], axis=1,inplace=True)
输入:df.drop([df.columns[[0,1]]],axis=1,inpalce=True)

总结:凡是会对原数组作出修改并返回一个新数组的,往往都有一个 inplace可选参数。如果手动设定为True(默认为False),那么原数组直接就被替换。也就是说,采用inplace=True之后,原数组名(如2和3情况所示)对应的内存值直接改变;而采用inplace=False之后,原数组名对应的内存值并不改变,需要将新的结果赋给一个新的数组或者覆盖原数组的内存位置(如1情况所示)。
通过pandas删除列:
1.del df['columns'] #改变原始数据
2.df.drop('columns',axis=1)#删除不改表原始数据,可以通过重新赋值的方式赋值该数据
3.df.drop('columns',axis=1,inplace='True') #改变原始数据

