第一次个人编程作业
计算模块接口的设计与实现过程
从拿到题目开始,就以完成附加题为目的去思考题目的实现方法,即不仅要分离地级信息,还要补全缺失的地级信息。对于前两个难度,完全可以利用正则表达式对文本串进行拆分分级,代码实现比较简单。然而如果要补全缺失的地级信息就需要联网查询或者本地保存地址集查询某个地址的上级。
原本的想法是Java+爬虫的思想在线实现地级查询,但考虑到网络速度和访问失败等不一定因素拖慢运行效率(受舍友@Stolf蛊惑),所以前期工作还是决定先用Java写个爬虫从国家统计局爬取地址信息转化为本地文件+C++离线查询。(选择C++又是受了舍友蛊惑(´-ι_-`))
前期工作
先Mark一下地址集的来源网址
在耗时一个晚上的爬虫编写和调试过后,终于成功的爬取到了地址集信息。因为地级具有层级关系,所以先将地址信息保存为Json格式以便下一步操作。输出的格式要求是Json格式,这里我偷了个懒在网上找了一个第三方库JsonCPP,可以很方便的解析和生成Json格式的字符串,不过因此恶补了一波VS工程链接的知识,还是花了不少时间。到这里前期工作算是完成了。
- 补一个自己写的Java爬虫GitHub
字符串编码转换
然后就是思考如何处理用户输入的字符串,首先要解决的是字符串的编码转换。与Java不同,C++ STL由于出现的比较早,STL字符串类型string在处理中文等宽字符相比Java String类就显得非常吃力,好在万能的网友早就解决了这一类问题。
字符编码的第一个难关是字符编码的问题,这次作业的输入文件和输出文件的编码格式都是UTF-8编码,UTF-8对汉字等宽字符的定义是由多个字符拼接组成,但是并没有指定是由多少个字符拼接(可能是两个也可能是三个),汉字操作非常麻烦。而GBK编码的定义是严由两个字符组成一个宽字符,可以更方便的处理中文字符,因此需要先将读入的字符先转为GBK编码,处理结束后再转化为UTF-8输出。第二个难关是如何同时处理数字(电话号码以及门牌号)和中文的问题,汉字是由宽字符组成的,占两个字符2个字节,而数字占用的依旧是1个字节的大小,遍历数组的时候无论每1个字节遍历还是每2个字节遍历都会导致字符处理出现问题。好在STL后续的版本中出现了宽字符串类型wstring,其定义的每个字符长度是2个字节(包括数字),恰好与GBK编码定义的标准相同,转化为wstring就可以方便的处理数字和中文了。因此对于一个读入的字符串,首先要将他由UTF-8转换为GBK,然后由string转化为wstring,处理结束后需要由GBK转换为UTF-8输出,所以至少要3个函数来实现这些转换。因为受到Java编程思想的影响,写了一个工具类StringChanger来存放字符转换的函数,但事实上C++只要写函数就行了,没有封装成类的必要。
StringChanger类接口:
- Utf8ToWstring():读入UTF-8编码字符串,返回GBK编码字符串,返回类型为wstring
- WstringToString():读入wstring字符串,返回string字符串
- StringToWstring():读入string字符串,返回wstring字符串
- Utf8ToGBK():读入UTF-8编码字符串,返回GBK编码字符串,返回类型为string
前四级地址的解析与补全
现在获得了一个GBK编码的wstring字符串,就可以进行信息分解了。将名字和电话号码分离后,就只剩下地址的分解。地址的格式大概为:
省级(可能缺失,后缀省略)+市级(可能缺失,后缀省略)+区级(可能缺失)+街道(可能缺失)+详细地址
由于前四级是之前爬虫爬取过数据集的,可以对爬取的数据集进行匹配和补全,但地址集有接近6w条,如果按照一般的匹配算法复杂度高达O(NM),如何高效进行匹配是接下来的重头戏。首先考虑这道题是典型的多模式串匹配文本串的问题,受职业病影响很快就想到了利用字典树Trie存储关键字来加速文本串的匹配。进行粗略的的构思后,抛弃了简单的正则匹配,开始尝试设计中文字典树。
进行长时间的思考和尝试后,我设计出了一种解决方案,例如
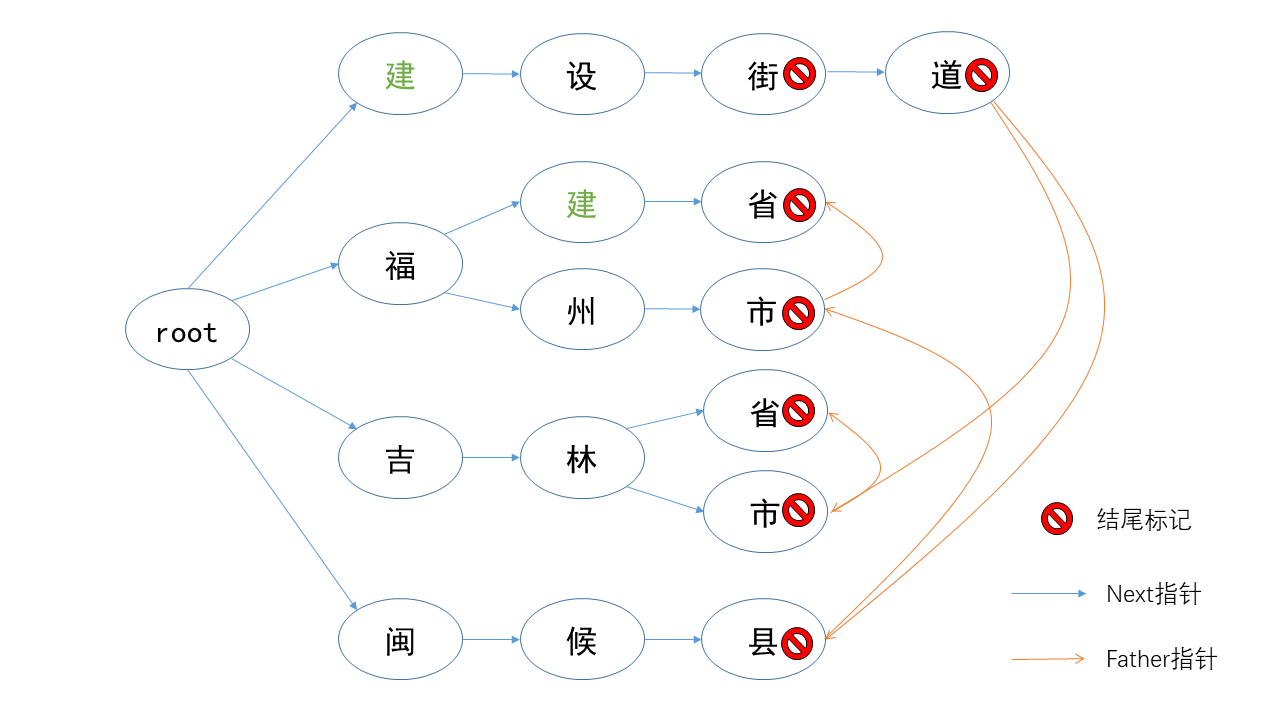
这幅图是我设计的字典树的一个例子,它由以下几个字符串组成
省级名称:福建省,吉林省
市级名称:福州市,吉林市
县级名称:闽侯县
街道名称:建设街,建设街道
Trie树中的每个节点中都有一个汉字,但即使代表的汉字相同不同的前缀也决定了这两个点不相同,例如“福建省”的“建“字和“建设街”的"建",因此Trie树的每个节点表示的应该是一段前缀,福建省的建表示的是"福建",而建设街的建表示的是“建”。next指针指向这段前缀下一个可能的汉字,而结尾标记表示这段前缀是字典树中的某个字符串,并在这个节点上标记该文本串的等级rank,即地级等级,例如福建省等级为0,福州市等级为1。
先按这个规则尝试匹配“福建省福州闽侯县”:
- 1、新建一个now指针初始在root点,从root点出发匹配"福",该字存在,now指针指向“福”;
- 2、接着在“福”这个点匹配“建”,这个字存在,now指针指向目标指针;
- 3、然后匹配“省”,存在,移动;
- 4、匹配“福”,可以发现,当前的now指针后继中不存在“福”字,匹配中止,now这个点存在结尾指针,说明“福建省”是个合法的地级名称,而且rank为0,即省级行政区。保存信息后,now指针重新指向root,继续匹配。
- 5、now从root匹配“福”,存在,移动
- 6、now指针匹配“州”,存在,移动
- 7、now指针匹配“闽”,可以发现“福州闽”这个节点并不存在(之前说过,每个节点表示的是一段前缀),匹配中止,但是“福州”这个节点并没有结尾指针,说明“福州”不是一个合法/完整的地级。
对于这种缺少地级后缀的情况,我设计的解决方法是往Trie树中加入一个es[rank]数组,保存在这个点上,等级为rank的最可能字符串,例如“福州”这个节点上,rank为1的地级最可能的是福州市,即es[1]=“福州市”。因为省略地名的只有前两级,而前两级去掉后缀重名的只有吉林省吉林市(全国唯一省级行政区与市级行政区同名的例子),而两者rank不同,也不会出现冲突的情况,所以es数组的命中率是100%,可以利用这种暴力的方法进行地级后缀的补全。利用新增的es数组回到刚刚的例子,“福州”虽然不是一个完整的地址,但是待查询的最高级地址(吉林省吉林市的例子,如果吉林省已经匹配,即0已经不是待匹配的最高等级,那么在“吉林”这个点上的不可能是吉林省,这里的待查询最高等级是1)存在合法地级信息,即es[1]猜测它是市级行政区:
- 8、询问es数组自己待查询的最高级地址有没有合法的地级信息。目前待查询的最高等级是1,而es[1]存在合法答案“福州市”,因此贪心将福州市作为自己的第二级名称,即市级行政区。保存信息后,now指针重新指向root,继续匹配。
- 9、重复匹配过程,直到匹配结束。如果待查询的最高等级大于3,意味着前四级已经分离完成,剩下的字符串直接作为详细地址保存,并退出匹配过程。
详细的过程参考这张流程图:
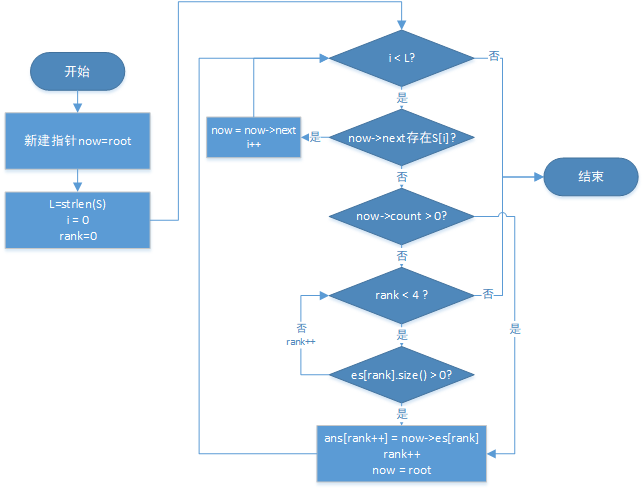
这种匹配方法没有匹配失败重新匹配的情况,即使有也会被标记后继续匹配文子串,匹配的复杂度可以降至O(M)(M为待查询文本串的长度),对于超大数据来说效率非常高。至此已经可以非常高效的完成难度1和难度2了。
难度3需要知道每一个地级上一级的信息,例如学园路的上级是闽侯县,闽侯县的上级是福州市。但中国地域广大,光是五一路南京路两只手就已经数不过来了。在受到失败指针的灵感后,我想到在所有结尾节点上链接若干条father指针,指向可能的上级。例如五一街道可以连到鼓楼区,也可以连到上海市。补全过程即是从最低层沿着father指针向上dfs,因为答案保证唯一,所以dfs的过程中一定会有唯一的一条路径是答案。根据粗略的计算,dfs的复杂度最坏不超过100次循环,是可实现的算法。
例如上面那张Trie树,我想要补全"福州市建设街道",那么就从“建设街道”这个节点沿着father指针dfs,走到“吉林市”的时候会因为无法和之前匹配完得到的“福州市”对上,就会回溯重新匹配,不断重复直到完全匹配到福建省福州市闽侯县建设街道。这样也就可以解决难度3的问题了。
按照我设计的算法,创建一个Trie类,root保存字典树根节点的指针,设计以下接口:
- insert():插入一个地级信息,设字符平均长度为M,复杂度约为O(M)。
- init():初始化字典树。因为要判断地级等级而之前处理的Json文件正好带有层级关系,减轻了实现的复杂度。从文件中读取Json字符串并利用JsonCPP解析,然后按层次递归加入字典树。初始化的复杂度是调用N(地级数量)次insert()接口,复杂度为O(NM),但因为N本身很大而且insert()的常数也不小,所以要花比较多的时间。
- seach():查询一个文本串中的地级信息。设查询的字符串长度为M,则查询复杂度约为O(M)。
- getPtr():返回某个地级的指针,主要用于补全地址。复杂度O(M)。
字典树初始化结束后,将整个地址丢入seach()接口,前四级的地址就会被准确的分离出来。再之后,详细地址由于没有数据集,但鉴于详细地址不可能缺失,因此可以也只能进行简单的正则匹配来分离文本串了。
答案存储和字符串处理入口
接着定义一个Person类存储分解的信息,并设计以下接口整合文本串分离的功能
- getName():将名字(第一个逗号之前)分离并保存到结构体
- getPhone():电话号码(连续的11个数字)分离并保存到结构体
- getCity():调用字典树的seach()接口分离前四级,并保存到结构体
- getAddress():分离后三级地址
- fixAddress():调用字典树的getPtr()接口获取字典树地级指针,补全缺失的信息。由于数据集只能爬到四级,没有第五级信息用于补全第四级,因此只能补全前三级,算是不足之处之一。
信息分解按照不同的难度依次调用不同的接口来完成对地址不同的处理方法。最后利用JsonCPP构造出Json文本即可。
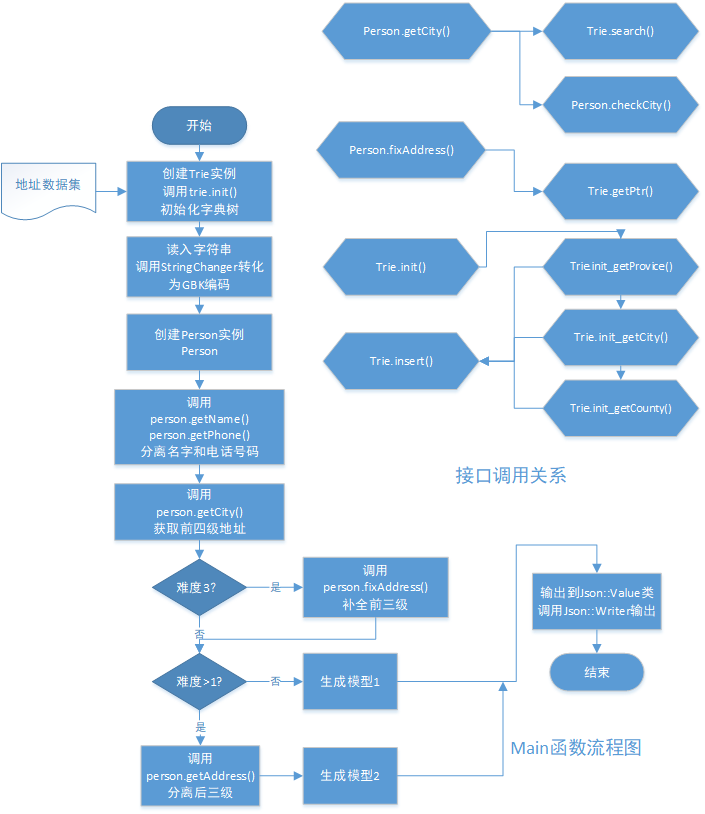
类图及流程图:
该项目共构造两个类(StringChanger类,Trie类)和两个结构体(Person,trie_node)
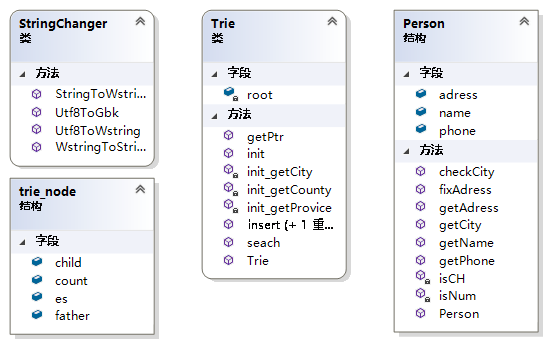
项目接口之间的调用关系和实现流程如下
计算模块接口部分的性能改进
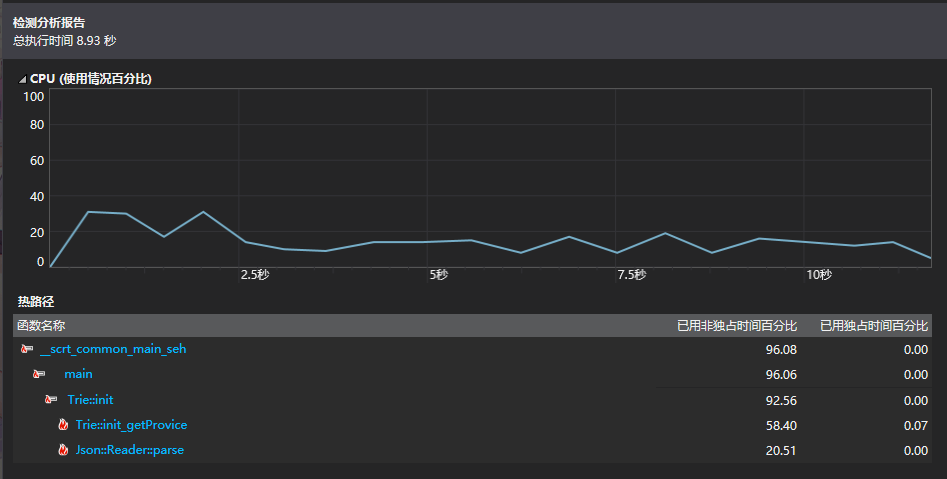
上图是运行约1000组数据的耗时,虽然一开始有想到Trie树的初始化(Trie.init())会花比较多的时间,但没有想到居然会耗时高达7s多的时间,反倒是1000组数据运行了不到1s,可见初始化是这个程序目前最大的瓶颈。
不过这个结果也侧面证明了Trie树处理数据的高效性,由于每一条数据长度不超过20,数据量每增长一条Trie的复杂度只会增加20个循环,而如果直接匹配会增加6w个循环,数据量越大Trie树的优势就会更大,只是用户在使用的时候需要等待7s的初始化时间,这个算法更适合大数据的处理。
考虑Trie初始化的流程来思考如何进行优化。初始化的时候需要频繁的从Json::Value变量中取出模式串,而且对于前缀重复的字符串需要进行更多重复的循环,因此我想到能否将数据结构保存在本地,在程序运行的时候不再重新构建Trie,Trie结构直接从文件中读取?由于对文件OI的速度并没有一个直觉,于是决定尝试一下。在对Trie数进行一个下午4个小时的修改过后再进行测试,初始化的时间反而增加了两倍,从7s延长到了14s,优化大失败......即使是文件OI果然速度也非常令人堪忧。
计算模块部分单元测试展示

以上是我设计的单元测试的代码及数据。因为这题的难度设计是层层递进的,因此在设计算法的时候就考虑了按层分解,难度3就几乎可以调用到我的所有代码,覆盖率很高,每份代码的覆盖率都至少打到了96%。
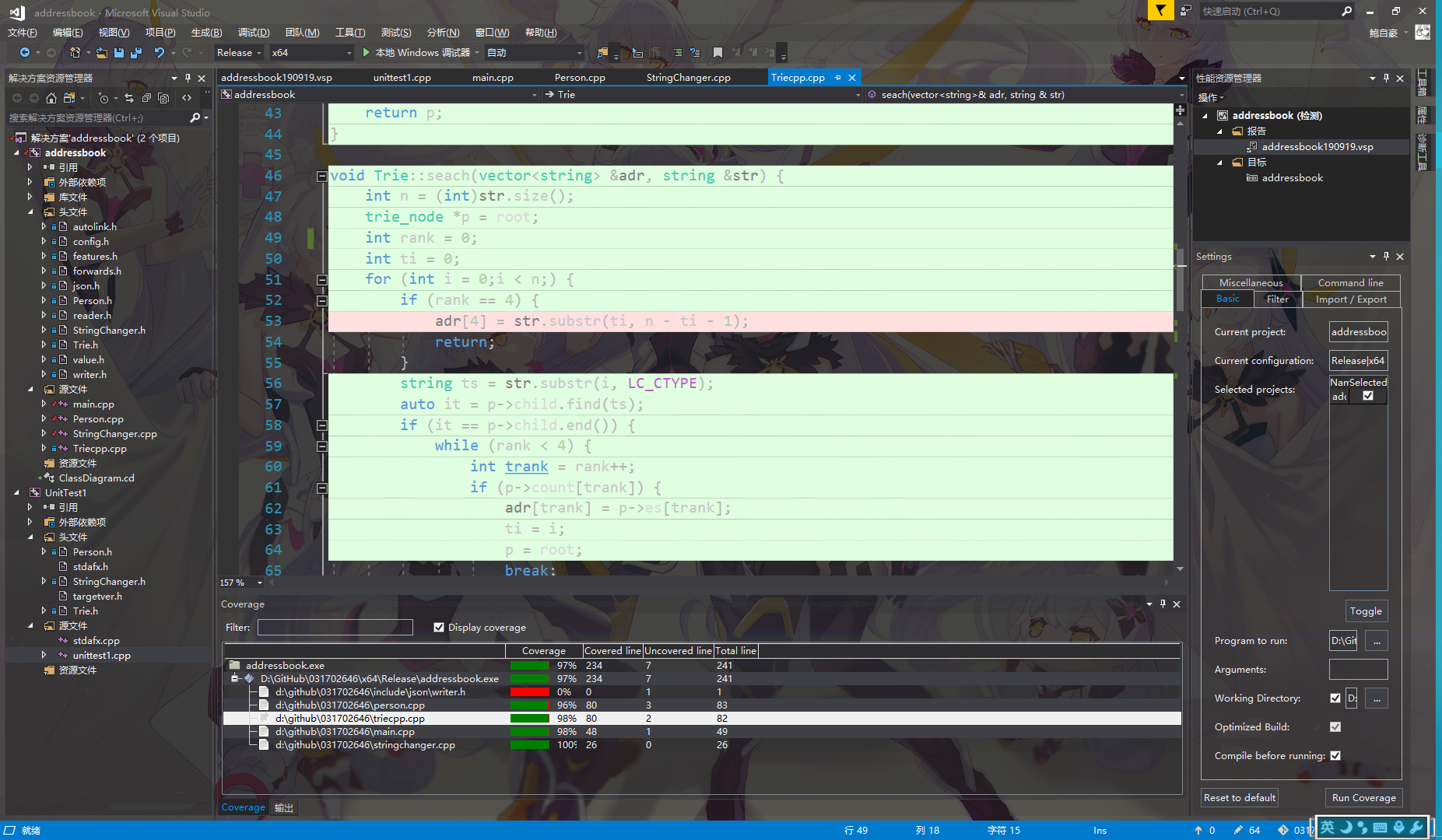
至于writer.h,这是JsonCPP的代码,由于只用到了打印的部分,所以覆盖率较低。
计算模块部分异常处理
在设计和编码的过程中,陆陆续续的有想到很多特殊的数据。由于中国地域实在广大,地名格式各式各样,总是能想要很多奇奇怪怪的数据,不得不针对这些特殊数据修改自己的算法。
由于我的Trie树是把所有等级的地名都连向了根部,这导致了几个异常的问题:
1、某个地级名称恰好是另一个地级名称的前缀
我刚开始设计的时候就想到了这个奇葩的问题,但当时想的是地级是有后缀的,应该没有这么巧的问题,但我万万没想到测试的时候还是找到了这么个奇葩的数据:
=====INPUT=====
1!罗小黑,13866777766上海市奉贤区泽丰路66弄老君社区.
=====OUTPUT=====
"姓名":"罗小黑",
"手机":"13866777766",
"地址":["","","","","上海市奉贤区泽丰路66弄老君社区"]
=====CORRECT=====
"姓名":"罗小黑",
"手机":"13866777766",
"地址":["上海","上海市","奉贤区","","泽丰路66弄老君社区"]
在查看数据集后,发现在上海市奉贤区恰好有个下级“上海市奉贤区海湾旅游区”,其名称前缀恰好包含了“上海市”,导致在匹配的过程在匹配到上海市奉贤区海(删除部分匹配失败)后因为匹配失败且不存在上海市奉贤区这个地级而判断失误。
对于这个异常,我想出的解决方案是改变查找中止条件,即不是搜索到无法移动然后进行分离操作,而是一开始就针对rank来查找,当下个节点的rank值:例如我寻找的是rank为0的节点,就会在遍历的时候进行询问防止越过可能的答案。但直到作业结束提交的时候还没想到实现的方法,这个异常在上交代码的时候暂未处理,可以进行优化。
2、地级可能出错(层次关系错误)
这个也是我设计算法的一个问题,举个栗子:
=====INPUT=====
1!仙贝,13869114514福建省闽侯县五一街道社区2号.
=====OUTPUT=====
"姓名":"仙贝",
"手机":"13869114514",
"地址":["福建省","","闽侯县","五一街道","社区2号"]
=====CORRECT=====
"姓名":"仙贝",
"手机":"13869114514",
"地址":["福建省","","闽侯县","","五一街道社区2号"]
闽侯县并没有五一街道,但是由于我的算法中所有模式串都连着根节点,因此有可能会搜索到别的地级下的四级街道,例如鼓楼区的五一街道。这里的解决方案是利用Father指针建立的层级关系从后往前来check一遍答案,对于错误的层次关系贪心将其挪到下一级或是挪到具体地址,来避免层次错误。
3、第四级的缺失补全
根据我的算法,如果要补全第四级则需要第五级的数据来check,但由于国家统计局只能爬取到第四级的地级数据,这使得第四级没有数据来确定。如果要实现第四级的补全,则要么花更多精力去寻找第五级的数据,要么联网接到某些地图的API来补全。介于我对C++网络功能的不了解及时间太紧的原因,没有解决这个问题,只能放弃这个点的得分了。
总结
因为自己直接奔着第三个难度去实现这次作业,以及自己追求效率(被舍友蛊惑)的原因,使得自己一开始就选择了一个非常Hard的道路。虽然过程非常辛苦(自己选择的难度跪着也要敲完),最后的得分相比Stolf大佬的算法也略逊一筹(1150个点仅通过1065个),但是从中学到了非常多有用的知识,例如在VS项目中如何链接和使用第三方库资源、C++字符串的编码问题、VS的效率分析和单元测试等等,更重要的是加深了对字典树的理解。ICPC区域赛马上就要开始了,希望今年自己能努力冲一把争取拿个铁牌。

