
爬虫入门(一)——静态网页爬取:批量获取高清壁纸
应老师分的方向,昨天开始自学入门爬虫了
虽然实现了一个比较简单的小爬虫,自己还是非常兴奋的,还是第一次实现 真的好开心
本来想爬pexel上的壁纸,然而发现对方的网页不知道设置了什么,反正有反爬虫机制,用python访问直接Fobbiden!真小气qwq
最后还是乖乖去爬zol上的壁纸了
Before:
在设计爬虫项目的时候,首先要在脑内明确人工浏览页面获得图片时的步骤
一般地,我们去网上批量打开壁纸的时候一般操作如下:
1、打开壁纸网页
2、单击壁纸图(打开指定壁纸的页面)
3、选择分辨率(我们要下载高清的图)
4、保存图片
实际操作时,我们实现了如下几步网页地址的访问:打开了壁纸的网页→单击壁纸图打开指定页面→选择分辨率,点击后打开最终保存目标图片网页→保存图片
在爬虫的过程中我们就尝试通过模拟浏览器打开网页的操作,一步步获得、访问网页、最后获得目标图片的下载地址,对图片进行下载保存到指定路径中
*这些中间过程中网页的一些具体筛选条件的构造,需要打开指定页面的源代码去观察和寻找包含有目的链接的标签
具体实现项目与注释
这里我只想获得一些指定的图片,所以我先在网页上搜索“长门有希”,打开了一个搜索结果页面,发现在这个页面上就已经包含了同类型的其他壁纸链接,于是我一开始就把最初访问的目的地址设置为这个搜索结果页面
目标结果页面截图:
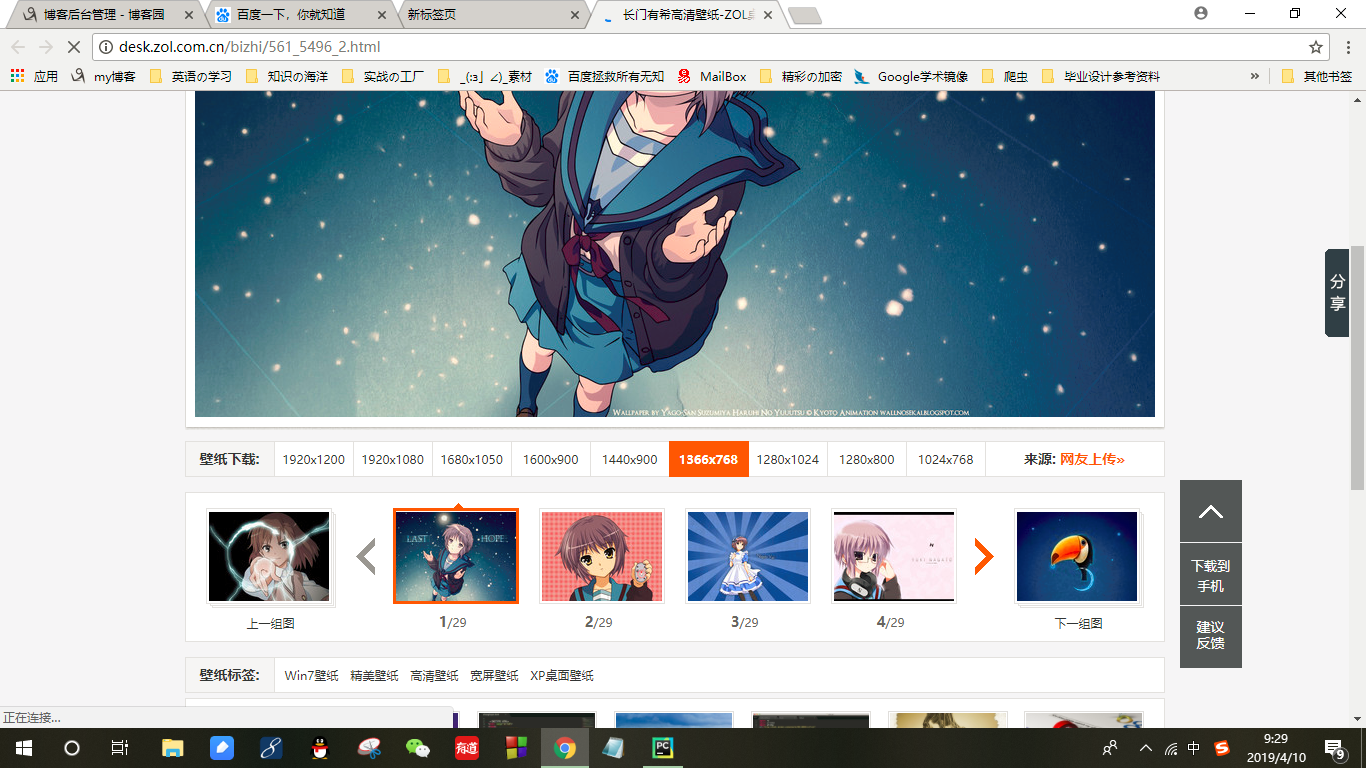
图中下标为"1/29"."2/29"为其他同类型目标壁纸,通过点击这些图片我们可以打开新的目标下载图片页面
这里我们查看一下网页源代码

图中黄色底的地方就是打开这些同类壁纸的目的地址(访问的时候需要加上前缀"http://desk.zol.com.cn")
现在我们可以尝试实现构建爬虫:
打开指定页面→筛选获得所有长门有希壁纸的目标下载页面链接
代码如下:
1 from urllib import request,error 2 import re 3 4 url = "http://desk.zol.com.cn/bizhi/561_5496_2.html" 5 6 try: 7 response = request.urlopen(url)# 打开页面 8 html = response.read() #此时是byte类型 9 html = str(html) # 转换成字符串 10 11 pattern = re.compile(r'<a.*? href="(.*?)".*?>.*?</a>') 12 imglist = re.findall(pattern,html) # 匹配<a>标签中的href地址 13 truelist = [] 14 for item in imglist: 15 if re.match(r'^\/bizhi\/561_',item): # 观察到所有目的地址下载页面前缀都是/bizhi/561_,通过match函数进行筛选 16 truelist.append(item)# 筛选掉其他无关的页面(把真的目标页面加到truelist列表中) 17 except error.HTTPError as e: 18 print(e.reason) 19 except error.URLError as e: 20 print(e.reason) 21 except: 22 pass
获得地址以后我们可以通过获取地址→打开指定页面→选择分辨率→获得目的下载地址→保存到本地指定路径中
在测试的时候我输出了一下上一步truelist中保存的内容
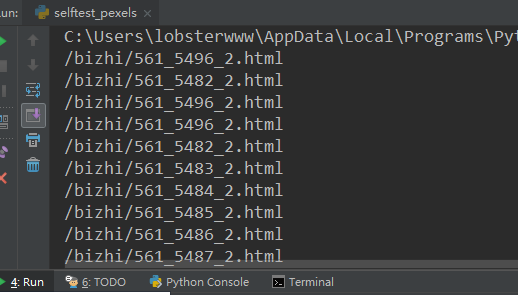
可以看到保存的只是一个后缀,在访问的时候我们需要加上一个指定的前缀
实现代码如下(注释见代码):
1 # 对于每一张地址,抓取其地址并且下载到本地 2 x=0 3 for wallpaperpage in truelist: 4 try: 5 # print(wallpaperpage) 6 url1 = "http://desk.zol.com.cn" + wallpaperpage 7 response1 = request.urlopen(url1) # 打开壁纸的页面,相当于在浏览器中单击壁纸名 8 html1 = response1.read() 9 html1 = str(html1) 10 pattern1 = re.compile(r'<a.*?id="1920x1080" href="(.*?)".*?>.*</a>') 11 urllist = re.findall(pattern1,html1) #匹配<a>标签中的id为1920 * 1080的地址,相当于在浏览器中选择1920*1080分辨率 12 html2 = str(request.urlopen("http://desk.zol.com.cn"+urllist[0]).read()) # 打开网页 13 14 pattern2 = re.compile(r'<img.*? src="(.*?)"') 15 wallpaperurl = re.findall(pattern2,html2) # 用于获取高清图片的地址 16 17 request.urlretrieve(wallpaperurl[0],"E://walkingbug/chapter1pic/%r.jpg" % x) 18 x+=1 19 except error.HTTPError as e: 20 print(e.reason) 21 except error.URLError as e: 22 print(e.reason) 23 except: 24 pass
最后可以在自己的目标文件夹中看到爬下来的图片集~

其他:
对上面代码出现的一些函数作用加以解释:
①request.urlopen(url):用于获取url网页的源代码内容信息,相当于模仿浏览器打开这个页面
②response.read():打印出源代码的内容
③pattern = re.compile(r'<a.*? href="(.*?)".*?>.*?</a>'):对正则表达式进行预编译
imglist = re.findall(pattern,html):在html中搜寻有无与pattern内容相匹配的字符串,保存括号内的内容,(黄色底内的内容)
这两段实际上等价于
imglist = re.findall(r'<a.*? href="(.*?)".*?>.*?</a>',html)
其实当匹配次数很高的时候,有无预编译的正则表达式匹配速度会有明显的差距,所以尽可能使用compile()预编译之后再进行正则表达式的匹配
④request.urlretrieve(wallpaperurl[0],"E://walkingbug/chapter1pic/%r.jpg" % x):用于把目标文件下载保存到指定路径中

