
CUDA程序性能分析-矩阵乘法
CUDA程序性能分析-矩阵乘法
前言
矩阵乘法非常适合在GPU上并行运行,但是使用GPU并行后能获得多大的性能提升?本文将通过一些实验分析CUDA程序的性能。
测试环境
本文使用Dell XPS 8700作为测试机,相关配置如下:
| 型号 | Dell XPS 8700 |
| CPU | Intel Core i7-4970 3.6GHz |
| 主存 | 16GB |
| GPU | GeForce GTX 750Ti |
| OS | Windows 10 64bit |
| CUDA | CUDA 8.0 |
带宽测试
使用CUDA Toolkit提供的示例程序bandwidthTest测试可分页内存(Pageable)和锁页内存(Page-lock or Pinned)的带宽,测试结果如下:
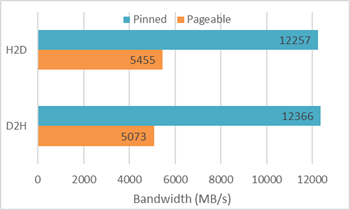
从上图可以看出,锁页内存对带宽的提升是非常大的,所以当一个程序的性能瓶颈是数据传输时,就应该考虑是否应该使用锁页内存。当然,使用锁页内存是有代价的——该内存空间不能换页,当大量使用时会导致内存耗尽而是程序崩溃。
矩阵乘法性能对比
测试了5个不同版本的矩阵乘法的性能:numpy、C++、CUDA无优化(CUDA1)、CUDA使用共享内存优化(CUDA2)、cuBLAS,由于原生Python版本的程序实在太慢了,故放弃之。CUDA和cuBLAS版本的矩阵乘法可以从CUDA Toolkit提供的示例程序matrixMul、matrixMulCUBLAS找到,当然需要做一些修改。5个版本的测试结果如下:
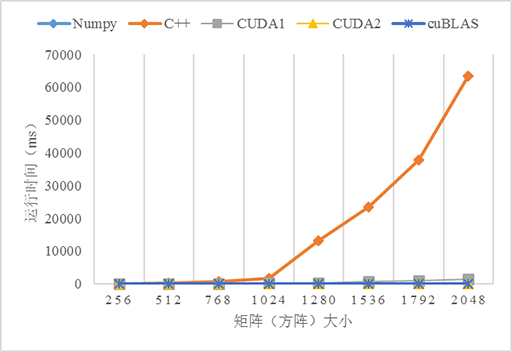
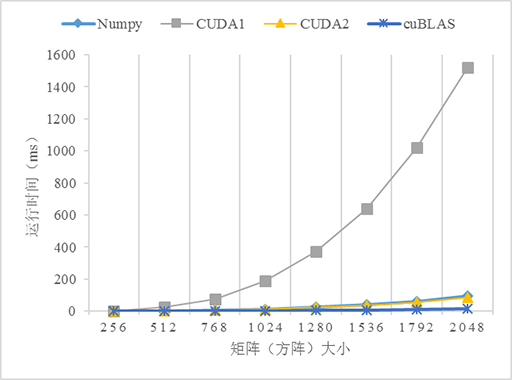
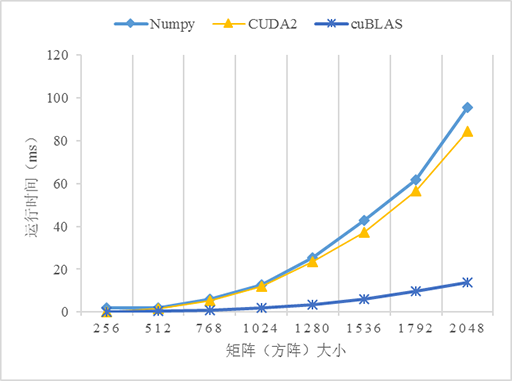
从上图可以看到,3个GPU版本的性能都比CPU(C++)版本高,尤其是在数据量变大的时候,如当数据量大于1024*1024时,C++版本的运行时间急剧上升。对比不使用共享内存和使用共享内存优化的版本可以看到,在数据量小的时候两个版本看不出差异,而当数据量越来越大的时,性能差异就很明显。使用共享内存优化的版本明显优于不优化的版本,这是因为从全局内存访问数据是非常慢的,而共享内存就相对快多了,当所有的线程都重复从全局内存读取数据势必导致全局内存总线拥堵,而且内存访问也不能合并,导致大量线程被挂起,从而降低性能。共享内存是程序员可以控制的高速缓存,应该可能地应用它以优化程序的性能。另外,使用cuBLAS似乎比自己实现一个算法的性能更高,这是因为这些库都是拥有丰富编程和优化经验的高级程序员编写的,所以当考虑自己实现一个算法的时候先看看是否有现成的库可以使用,有时候费力并不一定讨好 😄。
比较戏剧性的是Numpy,它的表现完全出乎我的意料,居然戏剧性地接近了比GPU版本的性能,关于原因还有待研究。这也告诉我们,使用Python时遇到数学计算还是尽量使用Numpy而不是python的math。当然如果你的计算机配备GPU或多核CPU(貌似现代GPU都是多核的)也可以考虑Numba加速Python程序,参考使用Python写CUDA程序。
结语
本文主要记录了本人测试CUDA程序性能的结果,并对结果进行了分析,从测试结果和分析可以为并行程序和优化性能带来一些启示。
本文完整代码可在Github上下载。

