
go中的数据结构-切片slice
1. 部分基本类型
go中的类型与c的相似,常用类型有一个特例:byte类型,即字节类型,长度为1,默认值是0;
1 bytes = [5]btye{'h', 'e', 'l', 'l', 'o'}
变量bytes的类型是[5]byte,一个由5个字节组成的数组。它的内存表示就是连起来的5个字节,就像C的数组。
1.1 字符串
字符串就是一串固定长度的字符连接起来的字符序列。Go 的字符串是由单个字节连接起来的。Go 语言的字符串的字节使用 UTF-8 编码标识 Unicode 文本。
字符串在Go语言内存模型中用一个2字长(8字节64位,32位内存布局方式下)的数据结构表示。它包含一个指向字符串数据存储地方的指针,和一个字符串长度数据如下图:
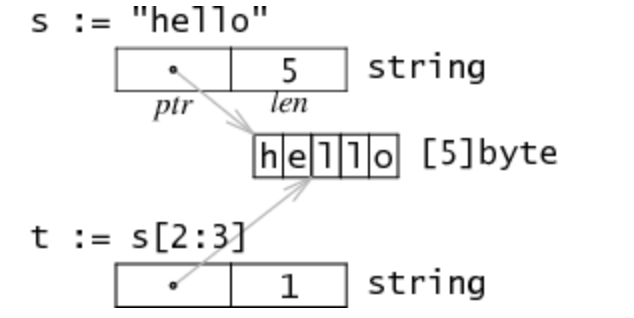
s是一个string类型的字符串,因为string类型不可变,对于多字符串共享同一个存储数据是安全的。切分操作str[i:j]会得到一个新的2字长结构t,一个可能不同的但仍指向同一个字节序列(即上文说的存储数据)的指针和长度数据。所以字符串切分不涉及内存分配或复制操作,其效率等同于传递下标。
1 func StringTest1() { 2 str := "Hello,World" 3 a := str[0] 4 b := str[1] 5 fmt.Printf("a=%c\n", a) 6 fmt.Printf("b=%c\n", b) 7 8 var byteSlice []byte 9 byteSlice = []byte(str) 10 byteSlice[0] = 'M' 11 str = string(byteSlice) 12 fmt.Printf("str=%s\n", str) 13 } 14 15 //a=H 16 //b=e 17 //str=Mello,World
-
len()返回字符串字节数目(不是rune数)。
-
通过索引可以访问某个字节值,索引大于等于0小于len(str)。越界会panic。索引不是不是对应的字符而是对应的字节,因为有非ASCII的UTF8字符有多个字节。
1 s := "hello, world" 2 fmt.Println(len(s)) // "12" 英文字符占一个字节 3 fmt.Println(s[0], s[7]) // "104 119" ('h' and 'w') 4 5 fmt.Println(s[:5]) // "hello" 6 fmt.Println(s[7:]) // "world" 7 fmt.Println(s[:]) // "hello, world" 8 fmt.Println("hi" + s[5:]) //hi, world
-
比较
字符串可以用==和<进行比较。通过逐个字节比较完成的,因此比较的结果是字符串自然编码的顺序。
-
rune
Unicode码点对应Go语言中的rune整数类型。rune表示utf8的字符,一个rune字符由一个或多个byte组成。因为 rune大小一致,所以支持数组索引和方便切割。
1 func StringTest2() { 2 3 str2 := "Hello,世界" 4 5 var str2ByteSlice []byte 6 str2ByteSlice = []byte(str2) 7 8 var str2RuneSlice []rune 9 str2RuneSlice = []rune(str2) 10 11 fmt.Printf("strLen=%v\n",len(str2) ) 12 fmt.Printf("str2ByteSlice=%v\n",len(str2ByteSlice) ) 13 fmt.Printf("str2RuneSlice=%v\n",len(str2RuneSlice) ) 14 15 for i:=0;i<len(str2RuneSlice);i++{ 16 var b = str2RuneSlice[i] 17 fmt.Printf("str2RuneSlice[%d]=%c\n" ,i,b) 18 } 19 20 //strLen=12 21 //str2ByteSlice=12 22 //str2RuneSlice=8
字符串的长度和byte切片的长度是一致的,字符串的长度要比rune切片的长度大,说明一个中文字符需要占用多个byte,这里是就是3个。
1 r := []rune("你好 world!") 2 fmt.Printf("%x\n", r) // "[4f60 597d 20 77 6f 72 6c 64 21]" 3 fmt.Println(string(r)) // "你好 world" 4 } 5 fmt.Println(string(65)) // "A", not "65" 整形字符串输出为unicode码点的utf8字符串。 6 fmt.Println(string(0x4eac)) // "京"
对字符串操作的4个包bytes、strings、strconv、unicode包
- bytes包操作[]byte。因为字 符串是只读的,因此逐步构创建字符串会导致很多分配和复制。使用 bytes.Buffer类型会更高。
- strings包提供切割,索引,前缀,查找替换等功能。
- strconv包提供了布尔型、整型数、浮点数和对应字符串的相互转换,还提供了双引号转义相 关的转换。
- unicode包提供了IsDigit、IsLetter、IsUpper和IsLower等类似功能,它们用于给字符分类。
1 x := 123 2 fmt.Println(strconv.Itoa(x)) // "123" 3 4 x, err := strconv.Atoi("123") // x is an int 5 y, err := strconv.ParseInt("123", 10, 64) 6 7 fmt.Println(strconv.FormatInt(int64(23), 2)) //将64转换成2进制
1.2 数组
数组是内置(build-in)类型,是一组同类型数据的集合,它是值类型,通过从0开始的下标索引访问元素值。数组类型定义了长度和元素类型。如, [4]int 类型表示一个四个整数的数组,其长度是固定的,长度是数组类型的一部分( [4]int 和 [5]int 是完全不同的类型)。 数组可以以常规的索引方式访问,表达式 s[n] 访问数组的第 n 个元素。数组不需要显式的初始化;数组的零值是可以直接使用的,数组元素会自动初始化为其对应类型的零值。
1 var a [4]int 2 a[0] = 1 3 i := a[0] 4 // i == 1 5 // a[2] == 0, int 类型的零值 6 [5] int {1,2} //长度为5的数组,其元素值依次为:1,2,0,0,0 。在初始化时没有指定初值的元素将会赋值为其元素类型int的默认值0,string的默认值是"" 7 [...] int {1,2,3,4,5} //长度为5的数组,其长度是根据初始化时指定的元素个数决定的 8 [5] int { 2:1,3:2,4:3} //长度为5的数组,key:value,其元素值依次为:0,0,1,2,3。在初始化时指定了2,3,4索引中对应的值:1,2,3 9 [...] int {2:1,4:3} //长度为5的数组,起元素值依次为:0,0,1,0,3。由于指定了最大索引4对应的值3,根据初始化的元素个数确定其长度为5赋值与使用
Go的数组是值语义。一个数组变量表示整个数组,它不是指向第一个元素的指针(不像 C 语言的数组)。 当一个数组变量被赋值或者被传递的时候,实际上会复制整个数组。 (为了避免复制数组,你可以传递一个指向数组的指针,但是数组指针并不是数组。) 可以将数组看作一个特殊的struct,结构的字段名对应数组的索引,同时成员的数目固定。
b := [2]string{"Penn", "Teller"} b := [...]string{"Penn", "Teller"}
这两种写法, b 都是对应 [2]string 类型。
2. 切片slice
2.1 结构
切片类型的写法是[]T ,T是切片元素的类型。和数组不同的是,切片类型并没有给定固定的长度。切片的字面值和数组字面值很像,不过切片没有指定元素个数,切片可以通过数组来初始化,也可以通过内置函数make()初始化。
letters := []string{"a", "b", "c", "d"} //直接初始化切片,[]表示是切片类型,{"a", "b", "c", "d"},初始化值依次是a,b,c,d.其cap=len=4 s := letters [:] //初始化切片s,是数组letters的引用(a slice referencing the storage of x) func make([]T, len, cap) []T //使用内置函数 make 创建 s :=make([]int,len,cap) //通过内置函数make()初始化切片s,[]int 标识为其元素类型为int的切片 s := arr[startIndex:endIndex] //将arr中从下标startIndex到endIndex-1 下的元素创建为一个新的切片 s := arr[startIndex:] //缺省endIndex时将表示一直到arr的最后一个元素 s := arr[:endIndex] //缺省startIndex时将表示从arr的第一个元素开始 s1 := s[startIndex:endIndex] //通过切片s初始化切片s1
slice可以从一个数组或一个已经存在的slice中再次声明。slice通过array[i:j]来获取,其中i是数组的开始位置,j是结束位置,但不包含array[j],它的长度是j-i。
1 var ar = [10]byte{'a','b','c','d','e','f','g','h','i','j'} // 声明一个含有10个元素元素类型为byte的数组 2 var a, b []byte // 声明两个含有byte的slice 3 a = ar[2:5] //现在a含有的元素: ar[2]、ar[3]和ar[4] 4 5 // b是数组ar的另一个slice 6 b = ar[3:5]// b的元素是:ar[3]和ar[4]
一个slice是一个数组某个部分的引用。在内存中它是一个包含三个域的结构体:指向slice中第一个元素的指针ptr,slice的长度数据len,以及slice的容量cap。长度是下标操作的上界,如x[i]中i必须小于长度。容量是分割操作的上界,如x[i:j]中j不能大于容量。slice在Go的运行时库中就是一个C语言动态数组的实现,在$GOROOT/src/pkg/runtime/runtime.h中定义:
struct Slice { // must not move anything byte* array; // actual data uintgo len; // number of elements uintgo cap; // allocated number of elements };
数组的slice会创建一份新的数据结构,包含一个指针,一个长度数据和一个容量数据。如同分割一个字符串,分割数组也不涉及复制操作,它只是新建了一个结构放置三个数据。如下图:
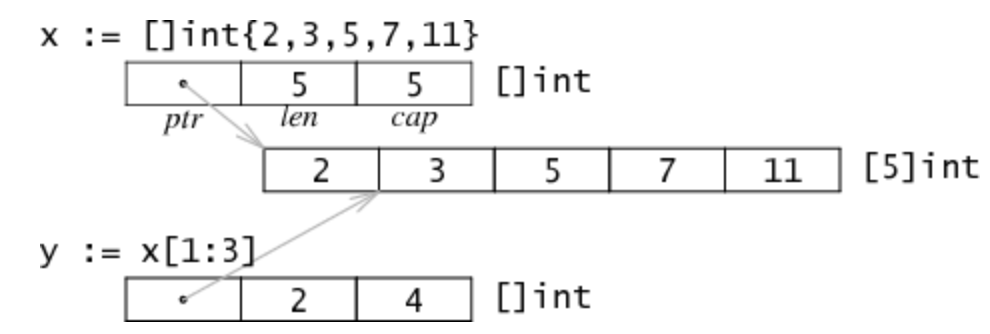
示例中,对[]int{2,3,5,7,11}求值操作会创建一个包含五个值的数组,并设置x的属性来描述这个数组。分割表达式x[1:3]不重新分配内存数据,只写了一个新的slice结构属性来引用相同的存储数据。上例中,长度为2--只有y[0]和y[1]是有效的索引,但是容量为4--y[0:4]是一个有效的分割表达式。
因为slice分割操作不需要分配内存,也没有通常被保存在堆中的slice头部,这种表示方法使slice操作和在C中传递指针、长度对一样廉价。
2.2 扩容
其实slice在Go的运行时库中就是一个C语言动态数组的实现,要增加切片的容量必须创建一个新的、更大容量的切片,然后将原有切片的内容复制到新的切片。在对slice进行append等操作时,可能会造成slice的自动扩容。其扩容时的大小增长规则是:
- 如果新的大小是当前大小2倍以上,则大小增长为新大小
- 否则循环以下操作:如果当前大小小于1024,按每次2倍增长,否则每次按当前大小1/4增长。直到增长的大小超过或等于新大小。
下面的例子将切片 s 容量翻倍,先创建一个2倍 容量的新切片 t ,复制 s 的元素到 t ,然后将 t 赋值给 s :
t := make([]byte, len(s), (cap(s)+1)*2) // +1 in case cap(s) == 0 for i := range s { t[i] = s[i] } s = t
循环中复制的操作可以由 copy 内置函数替代,返回复制元素的数目。此外, copy 函数可以正确处理源和目的切片有重叠的情况。
一个常见的操作是将数据追加到切片的尾部。必要的话会增加切片的容量,最后返回更新的切片:
func AppendByte(slice []byte, data ...byte) []byte { m := len(slice) n := m + len(data) if n > cap(slice) { // if necessary, reallocate // allocate double what's needed, for future growth. newSlice := make([]byte, (n+1)*2) copy(newSlice, slice) slice = newSlice } slice = slice[0:n] copy(slice[m:n], data) return slice }
Go提供了一个内置函数 append,也实现了这样的功能。
func append(s []T, x ...T) []T //append 函数将 x 追加到切片 s 的末尾,并且在必要的时候增加容量。 a := make([]int, 1) // a == []int{0} a = append(a, 1, 2, 3) // a == []int{0, 1, 2, 3}
如果是要将一个切片追加到另一个切片尾部,需要使用 ... 语法将第2个参数展开为参数列表。
a := []string{"John", "Paul"} b := []string{"George", "Ringo", "Pete"} a = append(a, b...) // equivalent to "append(a, b[0], b[1], b[2])" // a == []string{"John", "Paul", "George", "Ringo", "Pete"}
由于切片的零值 nil 用起来就像一个长度为零的切片,我们可以声明一个切片变量然后在循环 中向它追加数据:
// Filter returns a new slice holding only // the elements of s that satisfy fn() func Filter(s []int, fn func(int) bool) []int { var p []int // == nil for _, v := range s { if fn(v) { p = append(p, v) } } return p }
3. 使用切片需要注意的陷阱
切片操作并不会复制底层的数组。整个数组将被保存在内存中,直到它不再被引用。 有时候可能会因为一个小的内存引用导致保存所有的数据。
如下, FindDigits 函数加载整个文件到内存,然后搜索第一个连续的数字,最后结果以切片方式返回。
var digitRegexp = regexp.MustCompile("[0-9]+") func FindDigits(filename string) []byte { b, _ := ioutil.ReadFile(filename) return digitRegexp.Find(b) }
这段代码的行为和描述类似,返回的 []byte 指向保存整个文件的数组。因为切片引用了原始的数组, 导致 GC 不能释放数组的空间;只用到少数几个字节却导致整个文件的内容都一直保存在内存里。要修复整个问题,可以将需要的数据复制到一个新的切片中:
func CopyDigits(filename string) []byte { b, _ := ioutil.ReadFile(filename) b = digitRegexp.Find(b) c := make([]byte, len(b)) copy(c, b) return c }
使用 append 实现一个更简洁的版本:
8 func CopyDigitRegexp(filename string) []byte { 7 b,_ := ioutil.ReadFile(filename) 6 b = digitRefexp.Find(b) 5 var c []intb 4 // for _,v := range b{ 3 c =append(c, b) 2 //} 1 return c 0 }
4. make和new
Go有两个数据结构创建函数:make和new,也是两种不同的内存分配机制。
make和new的基本的区别是new(T)返回一个*T,返回的是一个指针,指向分配的内存地址,该指针可以被隐式地消除引用)。而make(T, args)返回一个普通的T。通常情况下,T内部有一些隐式的指针。所以new返回一个指向已清零内存的指针,而make返回一个T类型的结构。更详细的区别在后面内存分配的学习里研究。
5. 数组和切片的区别
- 数组长度不能改变,初始化后长度就是固定的;切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
- 结构不同,数组是一串固定数据,切片描述的是截取数组的一部分数据,从概念上说是一个结构体。
- 初始化方式不同,如上。另外在声明时的时候:声明数组时,方括号内写明了数组的长度或使用
...自动计算长度,而声明slice时,方括号内没有任何字符。 - unsafe.sizeof(slice)返回的大小是切片的描述符,不管slice里的元素有多少,返回的数据都是24字节。unsafe.sizeof(arr)的值是在随着arr的元素的个数的增加而增加,是数组所存储的数据内存的大小。
unsafe.sizeof总是在编译期就进行求值,而不是在运行时,这意味着,sizeof的返回值可以赋值给常量。 在编译期求值,还意味着可以获得数组所占的内存大小,因为数组总是在编译期就指明自己的容量,并且在以后都是不可变的。
unsafe.sizeof(string)时大小始终是16,不论字符串的len有多大,sizeof始终返回16,这是因为字符串类型对应一个结构体,该结构体有两个域,第一个域是指向该字符串的指针,第二个域是字符串的长度,每个域占8个字节,但是并不包含指针指向的字符串的内容。
6. nil
按照Go语言规范,任何类型在未初始化时都对应一个零值:布尔类型是false,整型是0,字符串是"",而指针,函数,interface,slice,channel和map的零值都是nil。
interface
一个interface在没有进行初始化时,对应的值是nil。也就是说var v interface{},此时v就是一个nil。在底层存储上,它是一个空指针。与之不同的情况是,interface值为空。比如:
1 var v *T 2 var i interface{} 3 i = v
此时i是一个interface,它的值是nil,但它自身不为nil。
string
string的空值是"",它是不能跟nil比较的。即使是空的string,它的大小也是两个机器字长的。slice也类似,它的空值并不是一个空指针,而是结构体中的指针域为空,空的slice的大小也是三个机器字长的。
channel
channel跟string或slice有些不同,它在栈上只是一个指针,实际的数据都是由指针所指向的堆上面。
跟channel相关的操作有:初始化/读/写/关闭。channel未初始化值就是nil,未初始化的channel是不能使用的。下面是一些操作规则:
- 读或者写一个nil的channel的操作会永远阻塞。
- 读一个关闭的channel会立刻返回一个channel元素类型的零值。
- 写一个关闭的channel会导致panic。
map
map也是指针,实际数据在堆中,未初始化的值是nil。

