

TCP拥塞控制
在某段时间,若对网络中某资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏——产生拥塞(congestion)。 出现资源拥塞的条件: 对资源需求的总和 > 可用资源 (5-7) 若网络中有许多资源同时产生拥塞,网络的性能就要明显变坏,整个网络的吞吐量将随输入负荷的增大而下降。
拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。
拥塞控制是一个全局性的过程,涉及到所有的主机、所有的路由器,以及与降低网络传输性能有关的所有因素。
流量控制往往指在给定的发送端和接收端之间的点对点通信量的控制。
流量控制所要做的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
拥塞控制的一般原理
拥塞控制是很难设计的,因为它是一个动态的(而不是静态的)问题。
当前网络正朝着高速化的方向发展,这很容易出现缓存不够大而造成分组的丢失。但分组的丢失是网络发生拥塞的征兆而不是原因。
在许多情况下,甚至正是拥塞控制本身成为引起网络性能恶化甚至发生死锁的原因。这点应特别引起重视。
开环控制和闭环控制
开环控制方法就是在设计网络时事先将有关发生拥塞的因素考虑周到,力求网络在工作时不产生拥塞。
闭环控制是基于反馈环路的概念。属于闭环控制的有以下几种措施:
监测网络系统以便检测到拥塞在何时、何处发生。
将拥塞发生的信息传送到可采取行动的地方。
调整网络系统的运行以解决出现的问题。
几种拥塞控制方法
1. 慢开始和拥塞避免
发送方维持一个叫做拥塞窗口 cwnd (congestion window)的状态变量。拥塞窗口的大小取决于网络的拥塞程度,并且动态地在变化。发送方让自己的发送窗口等于拥塞窗口。如再考虑到接收方的接收能力,则发送窗口还可能小于拥塞窗口。
发送方控制拥塞窗口的原则是:只要网络没有出现拥塞,拥塞窗口就再增大一些,以便把更多的分组发送出去。但只要网络出现拥塞,拥塞窗口就减小一些,以减少注入到网络中的分组数。
慢开始算法的原理
在主机刚刚开始发送报文段时可先设置拥塞窗口 cwnd = 1,即设置为一个最大报文段 MSS 的数值。
在每收到一个对新的报文段的确认后,将拥塞窗口加 1,即增加一个 MSS 的数值。
用这样的方法逐步增大发送端的拥塞窗口 cwnd,可以使分组注入到网络的速率更加合理
发送方每收到一个对新报文段的确认 (重传的不算在内)就使 cwnd 加 1
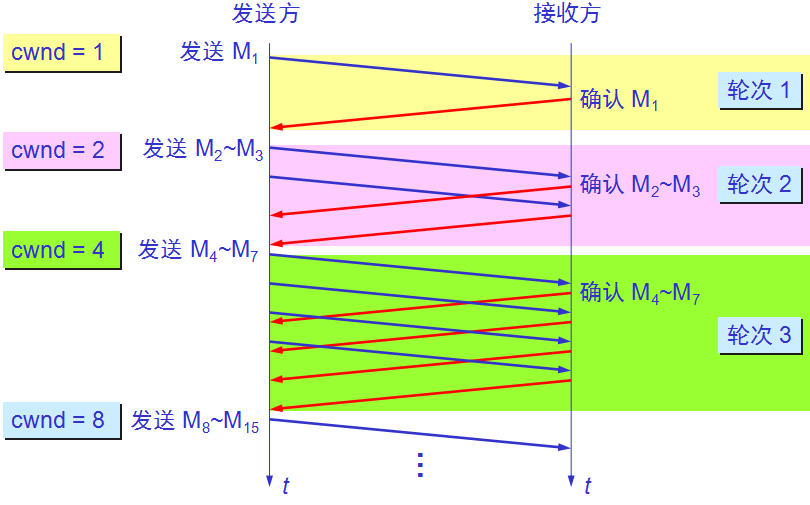
传输轮次
使用慢开始算法后,每经过一个传输轮次,拥塞窗口 cwnd 就加倍。
一个传输轮次所经历的时间其实就是往返时间 RTT。
“传输轮次”更加强调:把拥塞窗口 cwnd 所允许发送的报文段都连续发送出去,并收到了对已发送的最后一个字节的确认。
例如,拥塞窗口 cwnd = 4,这时的往返时间 RTT 就是发送方连续发送 4 个报文段,并收到这 4 个报文段的确认,总共经历的时间。
设置慢开始门限状态变量ssthresh
慢开始门限 ssthresh 的用法如下:
当 cwnd < ssthresh 时,使用慢开始算法。
当 cwnd > ssthresh 时,停止使用慢开始算法而改用拥塞避免算法。
当 cwnd = ssthresh 时,既可使用慢开始算法,也可使用拥塞避免算法。
拥塞避免算法的思路是让拥塞窗口 cwnd 缓慢地增大,即每经过一个往返时间 RTT 就把发送方的拥塞窗口 cwnd 加 1,而不是加倍,使拥塞窗口 cwnd 按线性规律缓慢增长。
当网络出现拥塞时
无论在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞(其根据就是没有按时收到确认),就要把慢开始门限 ssthresh 设置为出现拥塞时的发送方窗口值的一半(但不能小于2)。 然后把拥塞窗口 cwnd 重新设置为 1,执行慢开始算法。 这样做的目的就是要迅速减少主机发送到网络中的分组数,使得发生拥塞的路由器有足够时间把队列中积压的分组处理完毕。
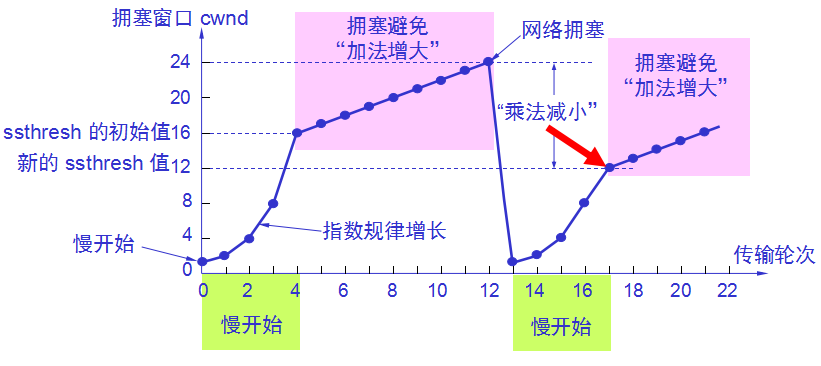
“乘法减小“是指不论在慢开始阶段还是拥塞避免阶段,只要出现一次超时(即出现一次网络拥塞),就把慢开始门限值 ssthresh 设置为当前的拥塞窗口值乘以 0.5。 当网络频繁出现拥塞时,ssthresh 值就下降得很快,以大大减少注入到网络中的分组数。
“加法增大”是指执行拥塞避免算法后,在收到对所有报文段的确认后(即经过一个往返时间),就把拥塞窗口 cwnd增加一个 MSS 大小,使拥塞窗口缓慢增大,以防止网络过早出现拥塞。
“拥塞避免”并非指完全能够避免了拥塞。利用以上的措施要完全避免网络拥塞还是不可能的。 “拥塞避免”是说在拥塞避免阶段把拥塞窗口控制为按线性规律增长,使网络比较不容易出现拥塞。
快重传和快恢复
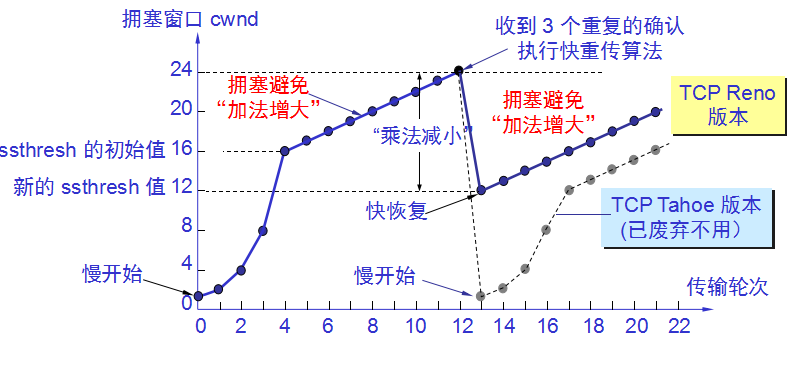
快重传算法首先要求接收方每收到一个失序的报文段后就立即发出重复确认。这样做可以让发送方及早知道有报文段没有到达接收方。 发送方只要一连收到三个重复确认就应当立即重传对方尚未收到的报文段。 不难看出,快重传并非取消重传计时器,而是在某些情况下可更早地重传丢失的报文段。

快恢复算法
(1) 当发送端收到连续三个重复的确认时,就执行“乘法减小”算法,把慢开始门限 ssthresh 减半。但接下去不执行慢开始算法。
(2)由于发送方现在认为网络很可能没有发生拥塞,因此现在不执行慢开始算法,即拥塞窗口 cwnd 现在不设置为 1,而是设置为慢开始门限 ssthresh 减半后的数值,然后开始执行拥塞避免算法(“加法增大”),使拥塞窗口缓慢地线性增大。
发送窗口的上限值
发送方的发送窗口的上限值应当取为接收方窗口 rwnd 和拥塞窗口 cwnd 这两个变量中较小的一个,即应按以下公式确定: 发送窗口的上限值
Min [rwnd, cwnd]
当 rwnd < cwnd 时,是接收方的接收能力限制发送窗口的最大值。
当 cwnd < rwnd 时,则是网络的拥塞限制发送窗口的最大值。
随机早期检测 RED
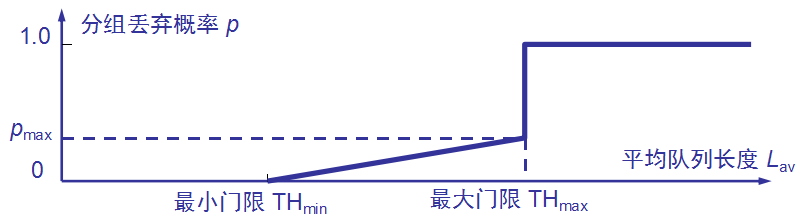
使路由器的队列维持两个参数,即队列长度最小门限 THmin 和最大门限 THmax。 RED 对每一个到达的数据报都先计算平均队列长度 LAV。 若平均队列长度小于最小门限 THmin,则将新到达的数据报放入队列进行排队。 若平均队列长度超过最大门限 THmax,则将新到达的数据报丢弃。 若平均队列长度在最小门限 THmin 和最大门限THmax 之间,则按照某一概率 p 将新到达的数据报丢弃。

丢弃概率 p 与 THmin 和 Thmax 的关系
当 LAV < Thmin 时,丢弃概率 p = 0。
当 LAV >Thmax 时,丢弃概率 p = 1。
当 THmin < LAV < THmax时, 0 <p < 1 。
例如,按线性规律变化,从 0 变到 pmax。

平均队列长度=(1-x)*旧的L av + x*当前的队列长度的样本
x越小越好
p=ptmp/(1-cnt*ptmp)
cnt是一个常数
ptmp=pmax*(lav-Tmin)/(Tmax-Tmin)

